






最近,我们在Apache 2.0 和 MIT 许可下发布了Flow-IPC(C++ 中的进程间通信工具包),并将其作为开放源代码。Flow-IPC 适用于在应用程序进程间传输数据的 C++ 项目,这些项目需要在不牺牲简单和可重用代码的前提下实现近乎零的延迟。
在公告中,我们展示了 Flow-IPC 可以像传输 100K 有效载荷一样快速传输高达 1GB 的数据结构有效载荷,传输时间不到 100 微秒。而使用传统的 IPC 时,延迟取决于有效载荷的大小,可达到 1 秒的范围。因此,改进幅度可达三或四个数量级。
在这篇文章中,我们将展示产生这些数字的源代码。我们的示例以Cap'n Proto集成为中心,表明 Flow-IPC 既快速又易于使用。(请注意,Flow-IPC API 是全面的,它支持传输各种类型的有效载荷,但基于 Cap'n Proto 的有效载荷传输是一项特殊功能)。Cap'n Proto是一个开放源码项目,与Akamai无关,其使用须遵守本博客发布之日的许可证规定(见此处)。
包括哪些内容?
Flow-IPC 是一个具有可扩展 C++17 应用程序接口的库。它是 托管在 GitHub 以及完整的文档、自动化测试、演示和 CI 管道。下面我们探讨的示例是 perf_demo 测试应用程序。Flow-IPC 目前支持在 x86-64 上运行的 Linux。我们计划将其扩展到 macOS 和 ARM64,然后根据需求扩展到 Windows 和其他操作系统变体。您 欢迎投稿 和港口。
Flow-IPC API 秉承了C++ 标准库和Boost 的精神,侧重于以模块化方式集成各种概念及其实现。其设计具有可扩展性。我们的 CI 管道会在一系列 GCC 和 Clang 编译器版本和构建配置中进行测试,包括通过运行时消毒器进行加固:ASAN(防止内存滥用)、TSAN(防止竞赛条件)和UBSAN(防止各种未定义行为)。
目前,Flow-IPC 适用于本地通信:跨越进程边界,但不跨越机器边界。不过,它的设计具有可扩展性,因此将其扩展到网络 IPC 是很自然的下一步。我们认为,远程直接内存访问(RDMA)的使用为实现超快的局域网性能提供了令人感兴趣的可能性。
谁应该使用它?
Flow-IPC 是一个实用的进程间通信工具包。在设计它时,我们从现代 C++ 系统开发人员的角度出发,特别针对人们经常面临的 IPC 任务进行了定制,尤其是在服务器应用程序开发中。我们中的许多人都曾不得不使用 Unix 域套接字、命名管道或基于 HTTP 的本地协议,将一些东西从一个进程传输到另一个进程。有时,为了避免这些解决方案中涉及的复制,我们可能会求助于共享内存(SHM),这是一种臭名昭著的难以重复使用的技术。Flow-IPC 可以帮助任何面临此类任务的 C++ 开发人员完成从普通到高级的任务。
亮点包括
- Cap'n Proto 集成:Cap'n Proto(同类产品中的佼佼者)等基于模式的就地序列化工具对进程间工作非常有帮助。但是,如果没有 Flow-IPC,您仍然需要将比特复制到套接字或管道等,然后在收到时再复制一次。Flow-IPC 可使用共享内存对Cap'n Proto 编码结构进行端到端的零拷贝传输。
- 支持 Socket/FD:通过 Flow-IPC 传输的任何信息都可以包含本地 I/O 句柄(也称为文件描述符或 FD)。例如,在网络服务器架构中,可以将服务器分成两个进程:一个进程用于管理端点,另一个进程用于处理请求。在端点进程完成 TLS 协商后,它可以将连接的 TCP 套接字句柄直接传递给请求处理进程。
- 本地 C++ 结构支持 许多算法需要直接在 C++ 上运行
struct这种结构通常涉及多层 STL 容器和/或指针。两个线程在这样的结构上协作是很常见的,也很容易编码,而两个线程在这样的结构上协作是很常见的,也很容易编码。 进程 通过共享内存来做到这一点是相当困难的--即使有像 Boost.interprocess.Flow-IPC 通过共享符合 STL 标准的结构(如容器、指针和普通数据)简化了这一过程。 - jemalloc 加 SHM:只需一行代码,您就可以在共享内存中分配任何必要的数据,无论是用于幕后操作(如 Cap'n Proto 传输),还是直接用于本地 C++ 数据。这些任务可以委托给 FreeBSD 和 Meta 背后的堆引擎jemalloc。对于需要密集共享内存分配(类似于常规堆分配)的项目来说,这一功能尤为重要。
- 无需命名或清理使用 Flow-IPC,您无需为服务器套接字、SHM 段或管道命名,也无需担心泄露的持久内存。相反,您只需在进程间建立一个 Flow-IPC会话 :这就是您的 IPC 上下文。通过这个会话对象,可以随意打开通信通道,无需额外命名。对于需要直接访问共享内存(SHM)的任务,可以使用专用的 SHM 区域。Flow-IPC 会自动进行清理,即使在异常退出的情况下也是如此,并能避免资源名称之间的冲突。
- 用于 RPC:Flow-IPC 的设计目的是与gRPC和Cap'n Proto RPC 等更高级别的通信框架互补,而非竞争。没有必要在它们和 Flow-IPC 之间做出选择。事实上,使用 Flow-IPC 的零拷贝功能通常可以提高这些协议的性能。
示例:发送多部分文件
虽然 Flow-IPC 可以传输各种类型的数据,但我们决定将重点放在由Cap'n Proto (capnp) 模式描述的数据结构上。对于熟悉 capnp 和协议缓冲区的人来说,这个示例会特别清晰,但对于不太熟悉这些工具的人来说,我们也会给出足够的上下文。
在这个示例中,有两个应用程序参与了请求-响应场景。
- 应用程序 1(服务器):这是一个内存缓存服务器,已将 100kb 至 1GB 不等的文件预加载到 RAM 中。它随时处理获取缓存文件的请求并发出响应。
- 应用程序 2(客户端):该客户端请求获取一定大小的文件。应用程序 1(服务器)在一条信息中发送文件数据,并将其分成一系列块。每个数据块都包含数据及其哈希值。
# Cap'n Proto schema (.capnp file, generates .h and .c++ source code
# using capnp compiler tool):
$Cxx.namespace("cache_demo::schema");
struct Body
{
union
{
getCacheReq @0 :GetCacheReq;
getCacheRsp @1 :GetCacheRsp;
}
}
struct GetCacheReq
{
fileName @0 :Text;
}
struct GetCacheRsp
{
# We simulate the server returning file multiple parts,
# each (~equally) sized at its discretion.
struct FilePart
{
data @0 :Data;
dataSizeToVerify @1 :UInt64;
# Recipient can verify that `data` blob's size is indeed this.
dataHashToVerify @2 :Hash;
# Recipient can hash `data` and verify it is indeed this.
}
fileParts @0 :List(FilePart);
}我们在本实验中的目标是对 N 个大小的文件发出请求,接收响应,测量处理时间,并检查部分文件的完整性。这种交互是通过通信通道进行的。
为此,我们需要首先建立这个通道。虽然 Flow-IPC 允许你从其底层组成部分(本地套接字、POSIX 消息队列等)手动建立一个通道,但使用 Flow-IPC会话 要容易得多。会话只是两个实时进程之间的通信上下文。通道一旦建立,就可以随时使用。
从鸟瞰图来看,流程是这样的。
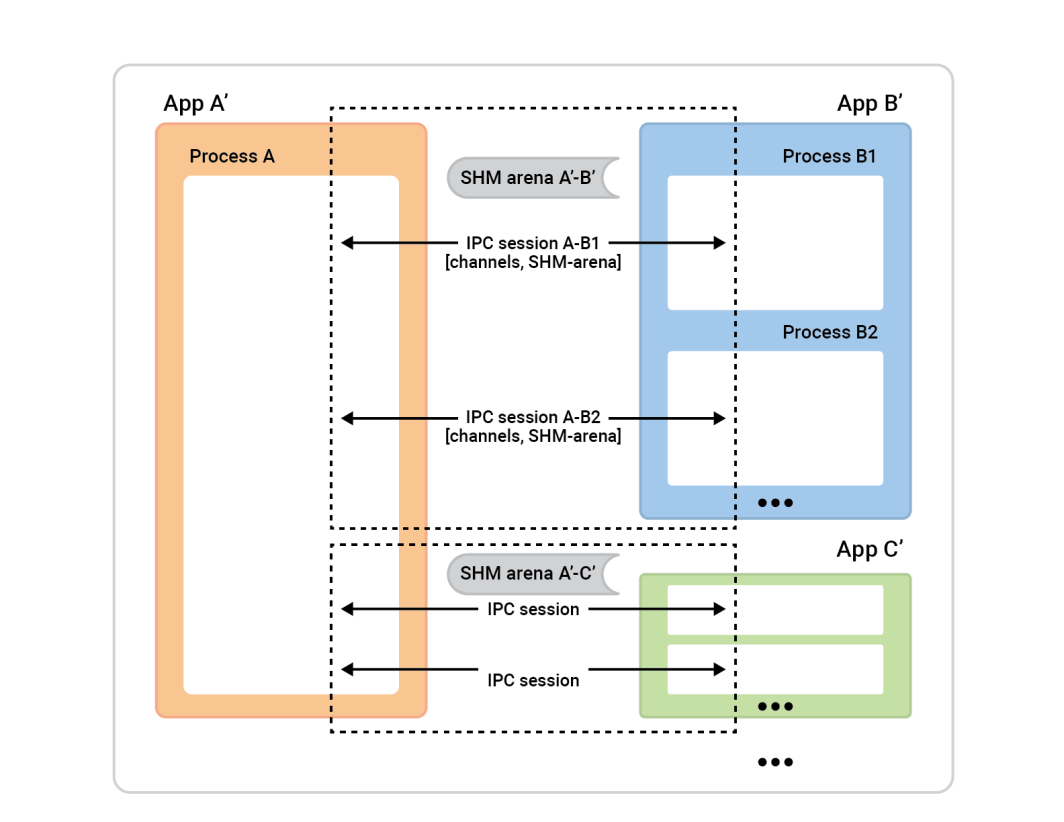
左边的进程 A 被称为会话服务器。右边的进程框(会话客户端)连接到进程 A,以建立会话。一般来说,任何给定的会话都是完全对称的,因此谁发起连接并不重要。双方能力相当,可以分配任何算法角色。不过,在会话准备就绪之前,我们需要分配角色。一边是会话客户端,将执行单个会话的即时连接;另一边是会话服务器,将接受 任意数量的会话。
在本例中,设置非常简单。有两个应用程序,它们之间有一个会话,会话中有一个通道。缓存客户端(应用程序 2)扮演会话客户端的角色,而会话服务器则由应用程序 1 担任。不过,反过来也行得通。
要实现这一功能,每个应用程序(高速缓存客户端和高速缓存服务器)都必须了解相同的 IPC 环境,这就意味着它们需要了解相关应用程序的基本情况。
原因就在这里:
- 客户端需要知道如何找到服务器以启动会话。如果您是连接应用程序(客户端),则需要知道接受应用程序的名称。Flow-IPC 会使用服务器的名称,并根据该名称确定套接字地址和共享内存段名称等细节。
- 出于安全考虑,服务器应用程序必须知道谁被允许连接到它。Flow-IPC 会根据操作系统检查客户端的详细信息,如用户/组和可执行文件路径,以确保一切相符。
- 标准操作系统安全机制(所有者、权限)适用于各种 IPC 传输(套接字、MQ、SHM)。单一选择器
enum将设置要使用的高级策略,然后 Flow-IPC 将在尊重该选择的前提下尽可能严格地设置权限。
对于我们来说,只需在两个应用程序中分别执行以下操作即可。这可以在一个 .cpp 文件链接到缓存服务器和缓存客户端应用程序中。
// IPC app universe: simple structs naming the 2 apps.
// The applications should share this code.
const ipc::session::Client_app
CLI_APP{ "cacheCli", // Name the app uniquely.
// From where it will run (for safety).
"/usr/bin/cache_client.exec",
CLI_UID, GID }; // The user and group ID (for safety).
const ipc::session::Server_app
SRV_APP{ { "cacheSrv", "/usr/bin/cache_server.exec", SRV_UID, GID },
// For the server, provide similar details --^.
// Plus a few server-specific settings:
// Safety: List client-app names that can connect to server-app.
// So in our case this will just be { "cacheCli" }.
{ CLI_APP.m_name },
"", // An optional path override; don't worry about it here.
// Safety/permissions selector:
// We've decided to run the two apps as different users
// in the same group - so we indicate that here.
ipc::util::Permissions_level::S_GROUP_ACCESS }; 请注意,更复杂的设置可以有更多这样的定义。
在每个应用程序中执行这些代码后,我们只需将这些对象传递到会话对象构造函数中,这样服务器就会知道在接受会话时应该期待什么,客户端也会知道应该连接到哪个服务器。
因此,让我们打开会话。在应用程序 2(缓存客户端)中,我们只想打开一个会话和其中的一个通道。虽然 Flow-IPC 允许随时即时打开通道(给定会话对象),但通常在会话开始时需要一定数量的随时可用通道。由于我们只想打开一个通道,因此可以让 Flow-IPC 在创建会话时创建通道。这样可以避免不必要的异步。因此,在缓存客户端的 main() 函数,我们只需使用一个 .sync_connect() 打电话:
// Specify that we *do* want zero-copy behavior, by merely choosing our
// backing-session type.
// In other words, setting this alias says, “be fast about Cap’n Proto things.”
//
// Different (subsequent) capnp-serialization-backing and SHM-related behaviors
// are available; just change this alias. E.g., omit `::shm::classic` to disable
// SHM entirely; or specify `::shm::arena_lend::jemalloc` to employ
// jemalloc-based SHM. Subsequent code remains the same!
// This demonstrates a key design tenet of Flow-IPC.
using Session = ipc::session::shm::classic::Client_session<...>;
// Tell Session object about the applications involved.
Session session{ CLI_APP, SRV_APP, /* detail omitted */ };
// Ask for 1 *channel* to be available on both sides
// from the very start of the session.
Session::Channels ipc_raw_channels(1);
// Instantly open session - and the 1 channel.
// (Fail if server is not running at this time.)
session.sync_connect(session.mdt_builder(), &ipc_raw_channels);
auto& ipc_raw_channel = ipc_raw_channels[0];
// (Can also instantly open more channel(s) anytime:
// `session.open_channel(&channel)`.)
我们应该有一个 ipc_raw_channel 是一个基本通道对象。根据具体设置,它可以代表 Unix 域流套接字、POSIX MQ 或其他类型的通道。如果我们愿意,可以在 非结构化 这意味着我们可以用它来传输二进制 Blob(保留边界)和/或本地句柄(FD)。我们还可以通过 session.session_shm()->construct<T>(...).这超出了我们的讨论范围,但它的强大功能值得一提。
现在,我们只想说 "Cap'n Proto"。 cache_demo::schema::Body 协议(来自 .capnp 文件)。因此,我们 升级 原始通道对象的 结构化通道 对象:
// Template arg indicates capnp schema. (Take a look at the .capnp file above.)
Session::Structured_channel<cache_demo::schema::Body>
ipc_channel
{ nullptr, std::move(ipc_raw_channel), “Eat” the raw channel: take over it.
ipc::transport::struc::Channel_base::S_SERIALIZE_VIA_SESSION_SHM,
&session }; 设置完成。现在我们可以通过通道交换 capnp 信息了。请注意,我们已经避开了处理操作系统特定的细节,如对象名称、Unix 权限值等。我们的做法仅仅是为两个应用程序命名。我们还选择了端到端的零拷贝传输方式,通过利用共享内存来最大限度地提高性能,而不使用单个 ::shm_open() 或 ::mmap() 就在眼前。
现在我们可以开始有趣的部分了:发布 GetCacheReq 请求,接收 GetCacheRsp 响应,并访问该响应的各个部分,即文件部分及其哈希值。
代码如下
// Issue request and process response. TIMING FOR LATENCY GRAPH STARTS HERE -->
auto req_msg = ipc_channel.create_msg();
req_msg.body_root() // Vanilla capnp code: call Cap'n Proto-generated mutator API.
->initGetCacheReq().setFileName("huge-file.bin");
// Send message; get ~instant reply.
const auto rsp_msg = ipc_channel.sync_request(req_msg);
// More vanilla capnp work: accessors.
const auto rsp_root = rsp_msg->body_root().getGetCacheRsp();
// <-- TIMING FOR LATENCY GRAPH STOPS HERE.
// ...
verify_hash(rsp_root, some_file_chunk_idx);
// ...
// More vanilla Cap'n Proto accessor code.
void verify_hash(const cache_demo::schema::GetCacheRsp::Reader& rsp_root,
size_t idx)
{
const auto file_part = rsp_root.getFileParts()[idx];
if (file_part.getHashToVerify() != compute_hash(file_part.getData()))
{
throw Bad_hash_exception(...);
}
} 在上面的代码中,我们使用了简单的 .sync_request() 它既发送信息,又等待特定的回应。信息 ipc::transport::struc::Channel API 提供了许多便利措施,使协议的代码编写更加自然,包括异步接收、按消息类型、通知与请求、非调用消息与响应对处理函数进行解复用。您的模式不受限制 (cache_demo::schema::Body 在我们的例子中)。如果可以用 capnp 表达,则可以与 Flow-IPC 结构化通道一起使用。
就是这样!服务器方面的精神和难度都差不多。服务器 perf_demo 源代码。
如果没有 Flow-IPC,复制这种端到端零拷贝性能的设置将涉及大量复杂的代码,包括 SHM 段的管理,其名称和清理必须在两个应用程序之间进行协调。即使不使用零拷贝,即只使用.NET Framework 3.0,也会出现问题::write()的 Capnp 序列化副本。 req_msg 和 ::read()摄取 rsp_msg 相比之下,要编写足够强大的代码并非易事。
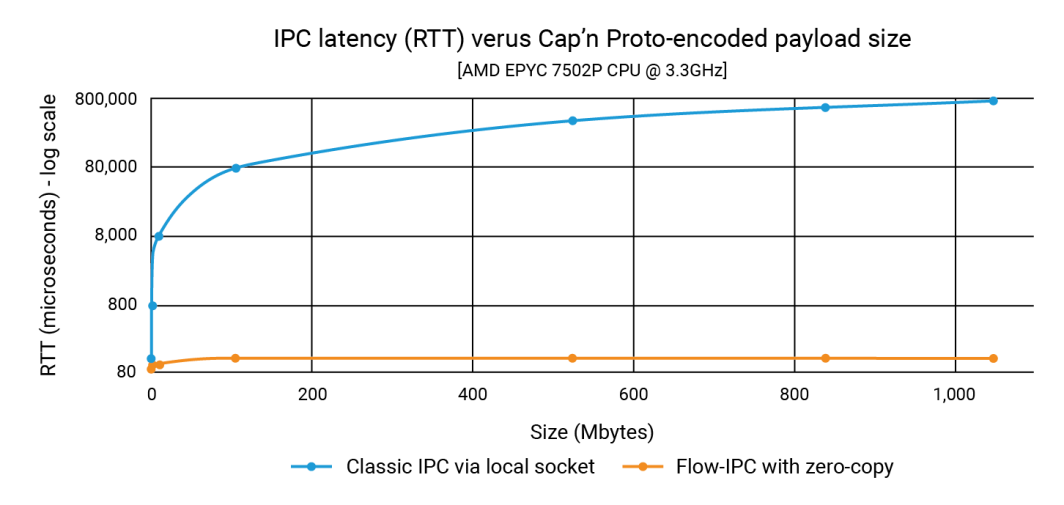
下图显示了延迟时间,其中 x 轴上的每个点代表所有延迟时间的总和。 filePart.data 的大小。蓝线显示的是基本方法的延迟时间,其中应用程序 1 使用 ::write()而应用程序 2 读取它们时 ::read().橙色线表示使用 Flow-IPC 的代码的延迟时间,如上所述。
如何捐款
有关功能请求和缺陷报告,请查看Flow-IPC GitHub 网站上的问题数据库。根据需要提交问题。
要贡献更改和新功能,请查阅贡献指南。您可以通过 GitHub 上的Flow-IPC 讨论板与我们取得联系。
下一步是什么?
我们试图在上述示例中提供一个真实的实验,在所示代码中没有跳过任何重要内容。我们特意选择了一个缺乏异步性和回调的场景。因此,会出现一些问题,比如 "如何将 Flow-IPC 与我的事件循环集成?"或者 "如何处理会话和通道关闭?我能否只打开一个简单的流套接字,而不使用所有会话功能?
这些问题在完整的文档中都有解答。文档包括由代码中的 API 注释生成的参考资料、学习曲线较为平缓的指导手册以及安装说明。主资源库的 README将为您指出所有这些资源。手册介绍和API 简介涵盖了可用功能的广度。
资源
- 公告博文
- GitHub 上的 Flow-IPC 项目
安装、阅读文档、提交功能/变更请求或作出贡献。 - Flow-IPC 讨论
联系我们和社区其他成员的好方法。


注释