






人工智能的蓬勃发展意味着在云端访问功能强大的 GPU 变得轻而易举,或者说几乎不可能,这取决于你问的是谁。问题在于如何在合适的提供商那里找到合适的 GPU ,而不需要为实际并不需要的硬件资源支付过高的费用,并且只 在需要时才 提供,而不需要承诺预付预订或签订苛刻的合同。
这是一项艰巨的任务,我们很高兴能够接受挑战。经过严格的测试和优化,Akamai的新型GPU现已面向所有客户推出。这些GPU由NVIDIA RTX 4000 Ada Generation显卡提供支持,针对媒体用例进行了优化,但大小适中,适合各种工作负载和应用。RTX 4000 Ada Generation 计划起价为每小时 0.52 美元,适用于 1GPU 、4 个 CPU 和 16GB 内存的六个核心计算区域:
- 伊利诺斯州,芝加哥
- 华盛顿州,西雅图
- 法兰克福,德国 扩展
- 巴黎,法国
- 大阪,JP
- 新加坡, SG 扩建
- 孟买,IN 扩展(即将推出)
使用案例要点
通过我们的测试计划,我们的客户和独立软件供应商 (ISV) 合作伙伴能够对我们的新 GPU 进行测试,包括我们知道将受益于我们设计的GPU 计划规格的关键用例:媒体转码和轻量级人工智能。
Capella Systems的云托管编码器Cambria Stream可为要求最严格的直播活动处理直播编码、广告插入、加密和打包。需要正确的技术和幕后配置,最终用户才能从所有不同的设备和跨网络基础设施观看流媒体直播活动。
"使用Akamai的新型NVIDIA RTX 4000 Ada Generation DualGPU ,一个Cambria Stream可以同时处理多达25个频道的多层编码,与基于CPU的编码相比,大大降低了总计算成本。"
阅读新闻稿全文。
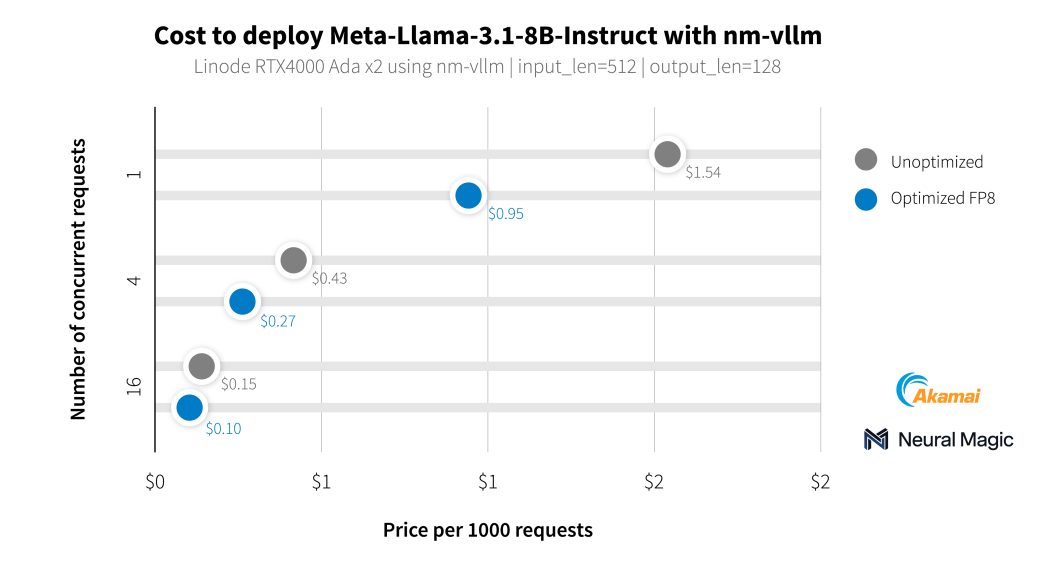
除了我们的媒体客户,我们还与Neural Magic合作,使用其企业就绪的 LLM 服务引擎nm-vllm,对我们新 GPU 的人工智能功能进行基准测试。他们利用其 LLM 开源压缩工具包LLM Compressor 实现了更高效的部署,准确率保持在 99.9%。在测试最新的Llama 3.1 模型时,Neural Magic 利用其软件优化功能,使用 RTX 4000 GPU 实现了每千次摘要请求的平均成本为 0.27 美元,与参考部署相比降低了 60%。
立即启用
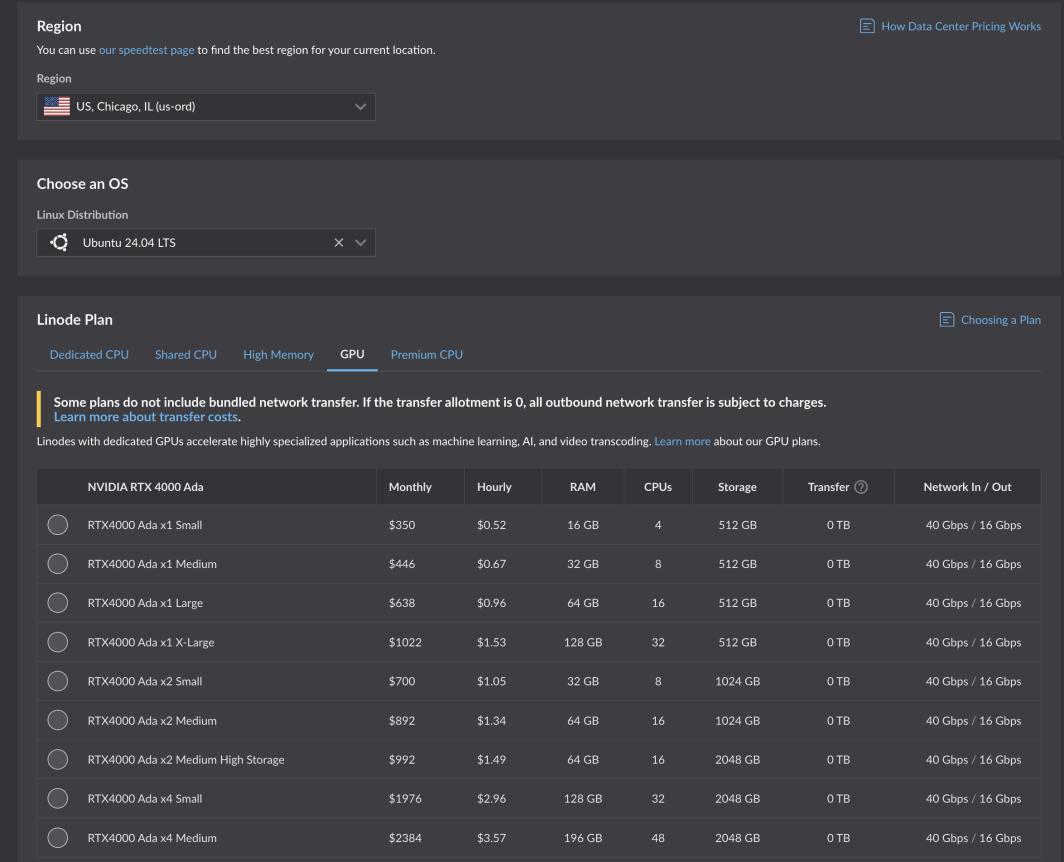
如果您已经拥有账户,则可以立即开始使用。只需选择一个受支持的地区,然后导航到计算实例计划表上的GPU 选项卡。
从我们的文档开始。
我们鼓励构建和管理业务应用程序的开发人员联系我们的云计算顾问团队。
注意: 使用AkamaiGPU 实例要求您的账户有正面的账单记录,不包括促销代码。如果您无法部署并需要访问GPU ,请开立支持票据。





注释