

Recentemente, lançamos o Flow-IPC - um kit de ferramentas de comunicação entre processos em C++ - como código aberto sob as licenças Apache 2.0 e MIT. O Flow-IPC será útil para projetos em C++ que transmitem dados entre processos de aplicativos e precisam obter latência próxima de zero sem comprometer o código simples e reutilizável.
No anúncio, mostramos que o Flow-IPC pode transmitir cargas úteis de estruturas de dados de até 1 GB com a mesma rapidez de uma carga útil de 100 K, e em menos de 100 microssegundos. Com o IPC clássico, a latência depende do tamanho da carga útil e pode chegar à faixa de 1 segundo. Assim, a melhoria pode chegar a três ou quatro ordens de magnitude.
Nesta postagem, mostramos o código-fonte que produziu esses números. Nosso exemplo, que se concentra na integração do Cap'n Proto, mostra que o Flow-IPC é rápido e fácil de usar. (Observe que o Flow-IPC API é abrangente, pois suporta a transmissão de vários tipos de cargas úteis, mas a transmissão de cargas úteis com base no Cap'n Proto é um recurso específico). O Cap'n Proto é um projeto de código aberto não afiliado à Akamai, cujo uso está sujeito à licença, a partir da data de publicação deste blog, encontrada aqui.
O que está incluído?
O Flow-IPC é uma biblioteca com um sistema extensível C++17 API. Ela é hospedado no GitHub juntamente com documentação completa, testes e demonstrações automatizados e um pipeline de CI. O exemplo que exploraremos a seguir é o perf_demo aplicativo de teste. Atualmente, o Flow-IPC oferece suporte ao Linux em execução no x86-64. Temos planos de expandir isso para o macOS e o ARM64, seguido pelo Windows e outras variantes de sistema operacional, dependendo da demanda. Você está bem-vindo a contribuir e porta.
O Flow-IPC API segue o espírito da biblioteca padrão C++ e do Boost, concentrando-se na integração de vários conceitos e suas implementações de forma modular. Ele foi projetado para ser extensível. Nosso pipeline de CI testa em uma variedade de versões de compiladores GCC e Clang e configurações de compilação, incluindo reforço por meio de sanitizadores de tempo de execução: ASAN (endurece contra o uso indevido da memória), TSAN (contra condições de corrida) e UBSAN (contra comportamentos indefinidos diversos).
No momento, o Flow-IPC destina-se à comunicação local: cruzando os limites do processo, mas não os limites da máquina. No entanto, ele tem um design extensível, portanto, expandi-lo para IPC em rede é uma próxima etapa natural. Acreditamos que o uso do Remote Direct Memory Access (RDMA) oferece uma possibilidade intrigante de desempenho ultrarrápido da LAN.
Quem deve usá-lo?
O Flow-IPC é um kit de ferramentas pragmático de comunicação entre processos. Ao projetá-lo, partimos da perspectiva do desenvolvedor de sistemas C++ moderno, adaptando-o especificamente às tarefas de IPC que enfrentamos repetidamente, principalmente no desenvolvimento de aplicativos de servidor. Muitos de nós já tivemos que montar um protocolo baseado em HTTP local, named-pipe ou Unix-domain-socket para transmitir algo de um processo para outro. Às vezes, para evitar a cópia envolvida em tais soluções, pode-se recorrer à memória compartilhada (SHM), uma técnica notoriamente sensível e difícil de reutilizar. O Flow-IPC pode ajudar qualquer desenvolvedor de C++ que se depare com essas tarefas, das mais comuns às mais avançadas.
Os destaques incluem:
- Integração com o Cap'n Proto: As ferramentas para serialização baseada em esquema no local, como o Cap'n Proto, que é o melhor da categoria, são muito úteis para o trabalho entre processos. No entanto, sem o Flow-IPC, você ainda teria que copiar os bits em um soquete ou canal, etc., e copiá-los novamente no recebimento. O Flow-IPC oferece transmissão de ponta a ponta com cópia zero de estruturas codificadas pelo Cap'n Proto usando memória compartilhada.
- Suporte a Socket/FD: Qualquer mensagem transmitida via Flow-IPC pode incluir um identificador de E/S nativo (também conhecido como descritor de arquivo ou FD). Por exemplo, em uma arquitetura de servidor da Web, você poderia dividir o servidor em dois processos: um processo para gerenciar endpoints e um processo para processar solicitações. Depois que o processo de endpoint concluir a negociação TLS, ele poderá passar o identificador do soquete TCP conectado diretamente para o processo de processamento de solicitações.
- Suporte nativo à estrutura C++: Muitos algoritmos exigem trabalho direto em C++
structs, na maioria das vezes envolvendo vários níveis de contêineres e/ou ponteiros STL. Dois threads que colaboram em uma estrutura desse tipo são comuns e fáceis de codificar, enquanto dois processos Fazer isso por meio da memória compartilhada é bastante difícil, mesmo com ferramentas inteligentes como Boost.interprocess. O Flow-IPC simplifica isso ao permitir o compartilhamento de estruturas compatíveis com STL, como contêineres, ponteiros e dados simples. - jemalloc mais SHM: uma linha de código permite alocar todos os dados necessários na memória compartilhada, seja para operações nos bastidores, como a transmissão do Cap'n Proto, ou diretamente para dados nativos do C++. Essas tarefas podem ser delegadas ao jemalloc, o mecanismo de heap por trás do FreeBSD e do Meta. Esse recurso pode ser particularmente valioso para projetos que exigem alocação intensiva de memória compartilhada, semelhante à alocação regular de heap.
- Sem dores de cabeça com nomes ou limpeza: Com o Flow-IPC, você não precisa nomear soquetes de servidor, segmentos SHM ou pipes, nem se preocupar com vazamento de RAM persistente. Em vez disso, estabeleça uma sessão do Flow-IPC entre processos: esse é o seu contexto de IPC. A partir desse objeto de sessão única, os canais de comunicação podem ser abertos à vontade, sem necessidade de nomeação adicional. Para tarefas que exigem acesso direto à memória compartilhada (SHM), uma arena SHM dedicada está disponível. O Flow-IPC realiza a limpeza automática, mesmo no caso de uma saída anormal, e evita conflitos entre os nomes dos recursos.
- Uso para RPC: O Flow-IPC foi projetado para complementar, e não competir com estruturas de comunicação de nível superior, como gRPC e Cap'n Proto RPC. Não há necessidade de escolher entre eles e o Flow-IPC. De fato, o uso dos recursos de cópia zero do Flow-IPC geralmente pode melhorar o desempenho desses protocolos.
Exemplo: Envio de um arquivo com várias partes
Embora o Flow-IPC possa transmitir dados de vários tipos, decidimos nos concentrar em uma estrutura de dados descrita por um esquema Cap'n Proto (capnp). Este exemplo será particularmente claro para aqueles que estão familiarizados com capnp e Protocol Buffers, mas daremos bastante contexto para aqueles que não estão tão familiarizados com essas ferramentas.
Neste exemplo, há dois aplicativos que se envolvem em um cenário de solicitação-resposta.
- Aplicativo 1 (servidor): Esse é um servidor de cache de memória que tem arquivos pré-carregados que variam de 100kb a 1GB na RAM. Ele está pronto para lidar com as solicitações de arquivo get-cached e emitir respostas.
- Aplicativo 2 (cliente): Esse cliente solicita um arquivo de um determinado tamanho. O aplicativo 1 (servidor) envia os dados do arquivo em uma única mensagem dividida em uma série de partes. Cada bloco inclui os dados junto com seu hash.
# Cap'n Proto schema (.capnp file, generates .h and .c++ source code
# using capnp compiler tool):
$Cxx.namespace("cache_demo::schema");
struct Body
{
union
{
getCacheReq @0 :GetCacheReq;
getCacheRsp @1 :GetCacheRsp;
}
}
struct GetCacheReq
{
fileName @0 :Text;
}
struct GetCacheRsp
{
# We simulate the server returning file multiple parts,
# each (~equally) sized at its discretion.
struct FilePart
{
data @0 :Data;
dataSizeToVerify @1 :UInt64;
# Recipient can verify that `data` blob's size is indeed this.
dataHashToVerify @2 :Hash;
# Recipient can hash `data` and verify it is indeed this.
}
fileParts @0 :List(FilePart);
}Nosso objetivo neste experimento é emitir uma solicitação para um arquivo de tamanho N, receber a resposta, medir o tempo que levou para ser processado e verificar a integridade de uma parte do arquivo. Essa interação ocorre por meio de um canal de comunicação.
Para isso, precisamos primeiro estabelecer esse canal. Embora o Flow-IPC permita que você estabeleça manualmente um canal a partir de suas partes constituintes de baixo nível (soquete local, fila de mensagens POSIX e outros), é muito mais fácil usar as sessões do Flow-IPC. Uma sessão é simplesmente o contexto de comunicação entre dois processos ativos. Uma vez estabelecidos, os canais ficam prontamente disponíveis.
Em uma visão geral, veja como o processo funciona.
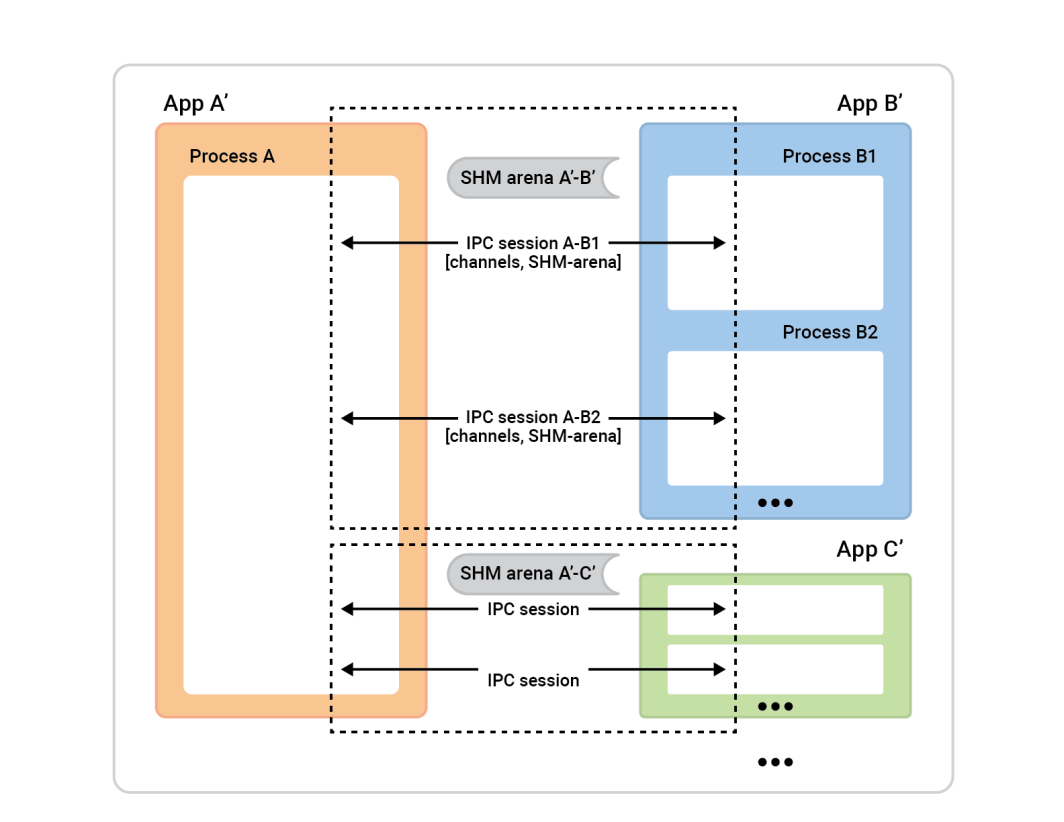
O processo A , à esquerda, é chamado de servidor de sessão. As caixas de processo à direita - clientes de sessão - conectam-se ao processo A para estabelecer sessões. Em geral, qualquer sessão é completamente simétrica, portanto, não importa quem iniciou a conexão. Ambos os lados são igualmente capazes e podem receber qualquer função algorítmica. No entanto, antes que a sessão esteja pronta, precisaremos atribuir funções. Um lado será o cliente da sessão e executará uma conexão instantânea de uma única sessão, e o outro lado, o servidor da sessão, aceitará quantas sessões quiser.
Neste exemplo, a configuração é simples. Há dois aplicativos com uma sessão entre eles e um canal nessa sessão. O cliente de cache (Aplicativo 2) desempenha a função de cliente de sessão, e a função de servidor de sessão é assumida pelo Aplicativo 1. No entanto, o inverso também funcionaria bem.
Para configurar isso, cada aplicativo (o cache-cliente e o cache-servidor) deve entender o mesmo universo IPC, o que significa apenas que eles precisam conhecer fatos básicos sobre os aplicativos envolvidos.
Veja por quê:
- O cliente precisa saber como localizar o servidor para iniciar uma sessão. Se você for o aplicativo de conexão (o cliente), precisará saber o nome do aplicativo de aceitação. O Flow-IPC usa o nome do servidor para descobrir detalhes como os endereços de soquete e os nomes de segmentos de memória compartilhada com base nesse nome.
- O aplicativo servidor deve saber quem tem permissão para se conectar a ele, por motivos de segurança. O Flow-IPC verifica os detalhes do cliente, como usuário/grupo e caminho do executável, em relação ao sistema operacional para garantir que tudo esteja correto.
- Os mecanismos de segurança padrão do sistema operacional (proprietários, permissões) se aplicam a vários transportes IPC (soquetes, MQs, SHM). Um único seletor
enumdefinirá a política de alto nível a ser usada e o Flow-IPC definirá as permissões da forma mais restritiva possível, respeitando essa escolha.
Para nós, precisaremos apenas executar o seguinte em cada um dos dois aplicativos. Isso pode ser feito em um único .cpp vinculado aos aplicativos cache-server e cache-client.
// IPC app universe: simple structs naming the 2 apps.
// The applications should share this code.
const ipc::session::Client_app
CLI_APP{ "cacheCli", // Name the app uniquely.
// From where it will run (for safety).
"/usr/bin/cache_client.exec",
CLI_UID, GID }; // The user and group ID (for safety).
const ipc::session::Server_app
SRV_APP{ { "cacheSrv", "/usr/bin/cache_server.exec", SRV_UID, GID },
// For the server, provide similar details --^.
// Plus a few server-specific settings:
// Safety: List client-app names that can connect to server-app.
// So in our case this will just be { "cacheCli" }.
{ CLI_APP.m_name },
"", // An optional path override; don't worry about it here.
// Safety/permissions selector:
// We've decided to run the two apps as different users
// in the same group - so we indicate that here.
ipc::util::Permissions_level::S_GROUP_ACCESS }; Observe que as configurações mais complexas podem ter mais dessas definições.
Depois de executar esse código em cada um de nossos aplicativos, simplesmente passaremos esses objetos para o construtor do objeto de sessão para que o servidor saiba o que esperar ao aceitar sessões e o cliente saiba a qual servidor se conectar.
Então, vamos abrir a sessão. No aplicativo 2 (o cliente de cache), queremos apenas abrir uma sessão e um canal dentro dela. Embora o Flow-IPC permita a abertura instantânea de canais a qualquer momento (dado um objeto de sessão), é comum precisar de um determinado número de canais prontos para uso no início da sessão. Como queremos abrir um canal, podemos permitir que o Flow-IPC crie o canal ao criar a sessão. Isso evita qualquer assincronia desnecessária. Portanto, no início da sessão do nosso cliente de cache main() podemos conectar e abrir um canal com uma única função .sync_connect() ligar:
// Specify that we *do* want zero-copy behavior, by merely choosing our
// backing-session type.
// In other words, setting this alias says, “be fast about Cap’n Proto things.”
//
// Different (subsequent) capnp-serialization-backing and SHM-related behaviors
// are available; just change this alias. E.g., omit `::shm::classic` to disable
// SHM entirely; or specify `::shm::arena_lend::jemalloc` to employ
// jemalloc-based SHM. Subsequent code remains the same!
// This demonstrates a key design tenet of Flow-IPC.
using Session = ipc::session::shm::classic::Client_session<...>;
// Tell Session object about the applications involved.
Session session{ CLI_APP, SRV_APP, /* detail omitted */ };
// Ask for 1 *channel* to be available on both sides
// from the very start of the session.
Session::Channels ipc_raw_channels(1);
// Instantly open session - and the 1 channel.
// (Fail if server is not running at this time.)
session.sync_connect(session.mdt_builder(), &ipc_raw_channels);
auto& ipc_raw_channel = ipc_raw_channels[0];
// (Can also instantly open more channel(s) anytime:
// `session.open_channel(&channel)`.)
Devemos ter um ipc_raw_channel now, que é um objeto de canal básico. Dependendo das configurações específicas, ele pode representar um soquete de fluxo do domínio Unix, um MQ POSIX ou outros tipos de canais. Se quiséssemos, poderíamos usá-lo em não estruturado imediatamente, o que significa que poderíamos usá-lo para transmitir blobs binários (com limites preservados) e/ou handles nativos (FDs). Também poderíamos acessar diretamente uma arena SHM por meio de session.session_shm()->construct<T>(...). Isso está fora do escopo de nossa discussão aqui, mas é um recurso poderoso que vale a pena mencionar.
Por enquanto, queremos apenas falar sobre o Cap'n Proto cache_demo::schema::Body (do nosso arquivo .capnp). Assim, nós atualização o objeto de canal bruto para um canal estruturado objeto dessa forma:
// Template arg indicates capnp schema. (Take a look at the .capnp file above.)
Session::Structured_channel<cache_demo::schema::Body>
ipc_channel
{ nullptr, std::move(ipc_raw_channel), “Eat” the raw channel: take over it.
ipc::transport::struc::Channel_base::S_SERIALIZE_VIA_SESSION_SHM,
&session }; Isso é tudo em nossa configuração. Agora estamos prontos para trocar mensagens capnp pelo canal. Observe que deixamos de lidar com detalhes específicos do sistema operacional, como nomes de objetos, valores de permissões Unix e assim por diante. Nossa abordagem consistiu apenas em nomear nossos dois aplicativos. Também optamos pela transmissão de cópia zero de ponta a ponta para maximizar o desempenho, aproveitando a memória compartilhada sem um único ::shm_open() ou ::mmap() à vista.
Agora estamos prontos para a parte divertida: emitir o GetCacheReq recebendo a solicitação GetCacheRsp e acessando várias partes dessa resposta, ou seja, as partes do arquivo e seus hashes.
Aqui está o código:
// Issue request and process response. TIMING FOR LATENCY GRAPH STARTS HERE -->
auto req_msg = ipc_channel.create_msg();
req_msg.body_root() // Vanilla capnp code: call Cap'n Proto-generated mutator API.
->initGetCacheReq().setFileName("huge-file.bin");
// Send message; get ~instant reply.
const auto rsp_msg = ipc_channel.sync_request(req_msg);
// More vanilla capnp work: accessors.
const auto rsp_root = rsp_msg->body_root().getGetCacheRsp();
// <-- TIMING FOR LATENCY GRAPH STOPS HERE.
// ...
verify_hash(rsp_root, some_file_chunk_idx);
// ...
// More vanilla Cap'n Proto accessor code.
void verify_hash(const cache_demo::schema::GetCacheRsp::Reader& rsp_root,
size_t idx)
{
const auto file_part = rsp_root.getFileParts()[idx];
if (file_part.getHashToVerify() != compute_hash(file_part.getData()))
{
throw Bad_hash_exception(...);
}
} No código acima, usamos o simples .sync_request() que envia uma mensagem e aguarda uma resposta específica. O ipc::transport::struc::Channel API fornece vários recursos para tornar os protocolos naturais para o código, incluindo recebimento assíncrono, demultiplexação para funções de manipulador por tipo de mensagem, notificação versus solicitação e mensagem não solicitada versus resposta. Não há restrições impostas ao seu esquema (cache_demo::schema::Body no nosso caso). Se for possível expressá-lo em capnp, você poderá usá-lo com canais estruturados do Flow-IPC.
É isso aí! O lado do servidor é semelhante em espírito e nível de dificuldade. Os perf_demo o código-fonte está disponível.
Sem o Flow-IPC, replicar essa configuração para obter desempenho de cópia zero de ponta a ponta envolveria uma quantidade significativa de código difícil, incluindo o gerenciamento de segmentos SHM cujos nomes e limpeza teriam que ser coordenados entre os dois aplicativos. Mesmo sem cópia zero, ou seja, simplesmente ::write()uma cópia da serialização capnp de req_msg para e ::read()ing rsp_msg de um FD de soquete de domínio Unix - um código suficientemente robusto não seria trivial de escrever em comparação.
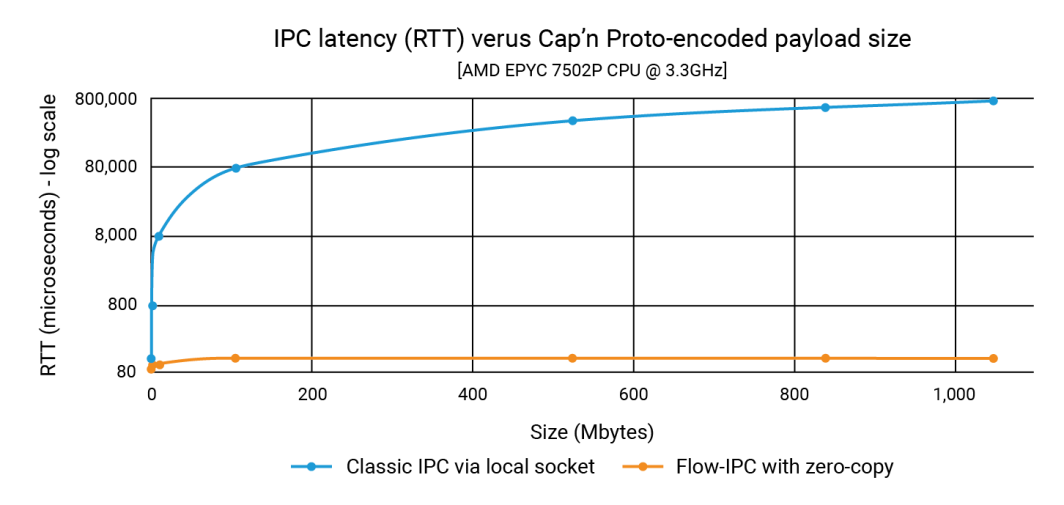
O gráfico abaixo mostra as latências, em que cada ponto no eixo x representa a soma de todos os filePart.data para cada execução de teste. A linha azul mostra as latências do método básico em que o Aplicativo 1 grava serializações capnp em um soquete de domínio Unix usando ::write()e o App 2 os lê com ::read(). A linha laranja representa as latências do código que usa o Flow-IPC, conforme discutido acima.
Como contribuir
Para solicitações de recursos e relatórios de defeitos, consulte o banco de dados de problemas no site do GitHub do Flow-IPC. Registre os problemas conforme necessário.
Para contribuir com alterações e novos recursos, consulte o guia de contribuição. Podemos entrar em contato no fórum de discussões do Flow-IPC no GitHub.
O que vem a seguir?
Tentamos fornecer um experimento realista no exemplo acima, sem pular nada significativo no código mostrado. Escolhemos deliberadamente um cenário que não tem assincronia e retornos de chamada. Assim, surgirão perguntas do tipo "como integrar o Flow-IPC ao meu loop de eventos?" ou "como lidar com o fechamento de sessões e canais? Posso simplesmente abrir um soquete de fluxo simples sem toda essa coisa de sessão?", etc.
Essas questões são abordadas na documentação completa. A documentação inclui uma referência gerada a partir de API comentários no código, um manual guiado com uma curva de aprendizado mais suave e instruções de instalação. O README do repositório principal o levará a todos esses recursos. A introdução do Manual e a sinopse do siteAPI abrangem a amplitude dos recursos disponíveis.
Recursos
- Anúncio de postagem no blog
- Projeto Flow-IPC no GitHub
Para instalar, ler a documentação, registrar solicitações de recursos/mudanças ou contribuir. - Discussões sobre o Flow-IPC
Ótima maneira de entrar em contato conosco e com o restante da comunidade.


Comentários