

Dependendo de quem você perguntar, o boom da IA significa que o acesso a GPUs avançadas na nuvem é muito fácil - ou quase impossível. O problema é encontrar aGPU certa no provedor certo sem pagar a mais por recursos de hardware de que você não precisa realisticamente e que estarão disponíveis somente quando você precisar, sem a necessidade de se comprometer com reservas pré-pagas ou contratos muito altos.
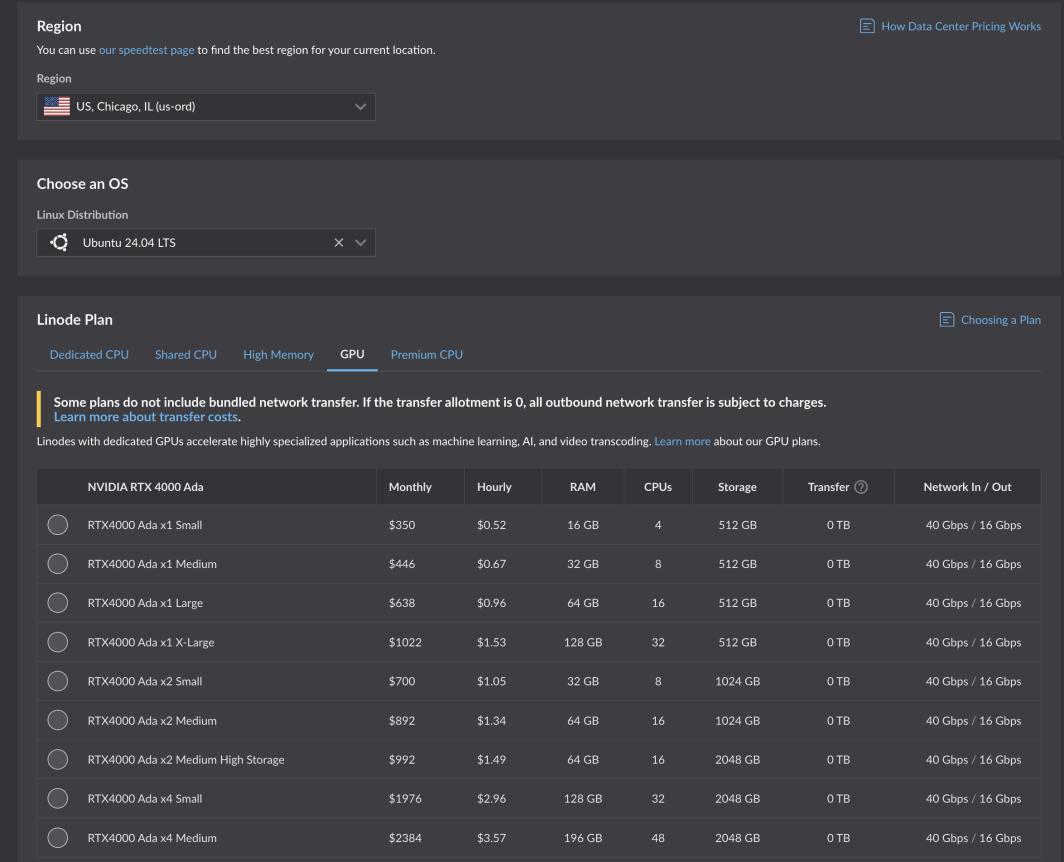
É uma tarefa difícil, e ficamos felizes em aceitar o desafio. Após rigorosos testes e otimização, as novas GPUs da Akamai já estão disponíveis para todos os clientes. Alimentadas pelas placas NVIDIA RTX 4000 Ada Generation, essas GPUs são otimizadas para casos de uso de mídia, mas têm o tamanho certo para uma variedade de cargas de trabalho e aplicações. Os planos do RTX 4000 Ada Generation começam em US$ 0,52 por hora para 1 GPU, 4 CPUs e 16 GB de RAM em seis regiões de computação central:
- Chicago, IL
- Seattle, WA
- Frankfurt, DE Expansão
- Paris, FR
- Osaka, JP
- Cingapura, SG Expansão
- Expansão em Mumbai, IN (em breve!)
Destaques do caso de uso
Por meio do nosso programa beta, nossos clientes e parceiros fornecedores independentes de software (ISV) puderam testar nossas novas GPUs, inclusive em casos de uso importantes que sabíamos que se beneficiariam das especificações do plano GPU que projetamos: transcodificação de mídia e IA leve.
O codificador hospedado na nuvem da Capella Systems, Cambria Stream, lida com codificação ao vivo, inserção de anúncios, criptografia e empacotamento para os eventos ao vivo mais exigentes. É necessária a tecnologia e a configuração corretas nos bastidores para que os usuários finais assistam a eventos transmitidos ao vivo em todos os dispositivos diferentes e em todas as infraestruturas de rede.
"Usando o novo NVIDIA RTX 4000 Ada Generation Dual da Akamai GPU, um único Cambria Stream pode processar até 25 canais de codificação multicamadas de uma só vez, reduzindo significativamente o custo total de computação em comparação com a codificação baseada em CPU."
Leia o comunicado à imprensa na íntegra.
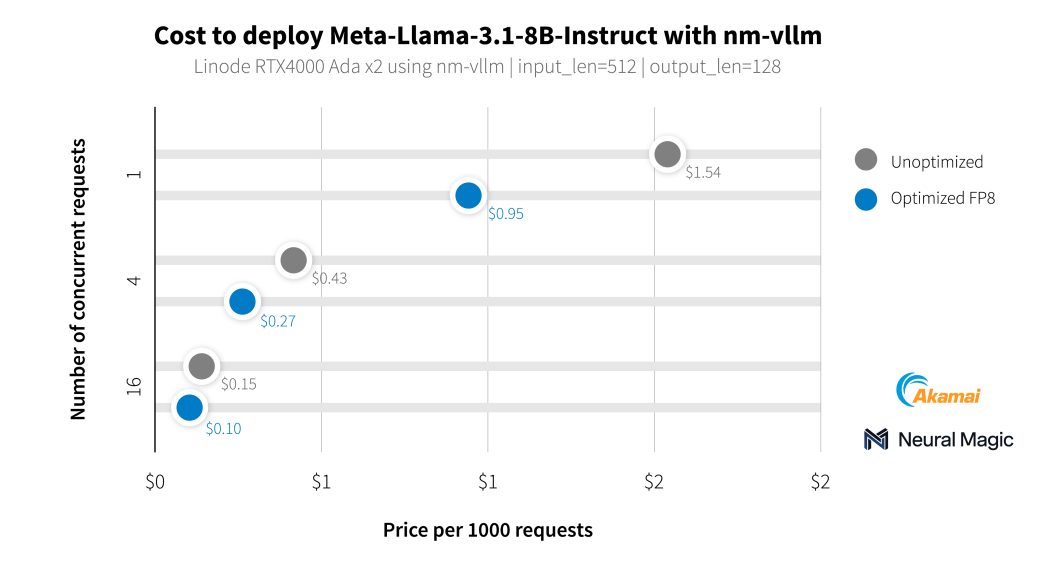
Além de nossos clientes de mídia, trabalhamos com a Neural Magic para avaliar os recursos de IA de nossas novas GPUs usando o nm-vllm, seu mecanismo de serviço LLM pronto para empresas. Eles usaram seu kit de ferramentas de compactação de código aberto para LLMs, o LLM Compressor, para produzir implementações muito mais eficientes com 99,9% de preservação da precisão. Ao testar os modelos mais recentes do Llama 3.1, a Neural Magic utilizou suas otimizações de software para atingir um custo médio de US$ 0,27 por 1.000 solicitações de compactação usando GPUs RTX 4000, uma redução de 60% no custo em comparação com a implantação de referência.
Começar agora
Se você já tiver uma conta, poderá começar imediatamente. Basta selecionar uma região compatível e navegar até a guia GPU na tabela de planos de instâncias de computação.
Comece a usar nossa documentação.
Os desenvolvedores que criam e gerenciam aplicativos de negócios são incentivados a entrar em contato com nossas equipes de consultores de nuvem.
Observação: o uso de instâncias da Akamai GPU requer um histórico de faturamento positivo em sua conta, não incluindo códigos promocionais. Se você não conseguir implantar e precisar de acesso a GPU , abra um tíquete de suporte.





Comentários