

AI 붐으로 인해 클라우드에서 강력한 GPU에 액세스하는 것은 매우 쉬워졌거나 거의 불가능에 가까워졌습니다. 문제는 현실적으로 필요하지 않은 하드웨어 리소스에 대해 과다한 비용을 지불하지 않고, 선불 예약이나 가파른 계약 없이 필요할 때만 사용할 수 있는 적절한 공급업체에서 적절한GPU 을 찾는 것입니다.
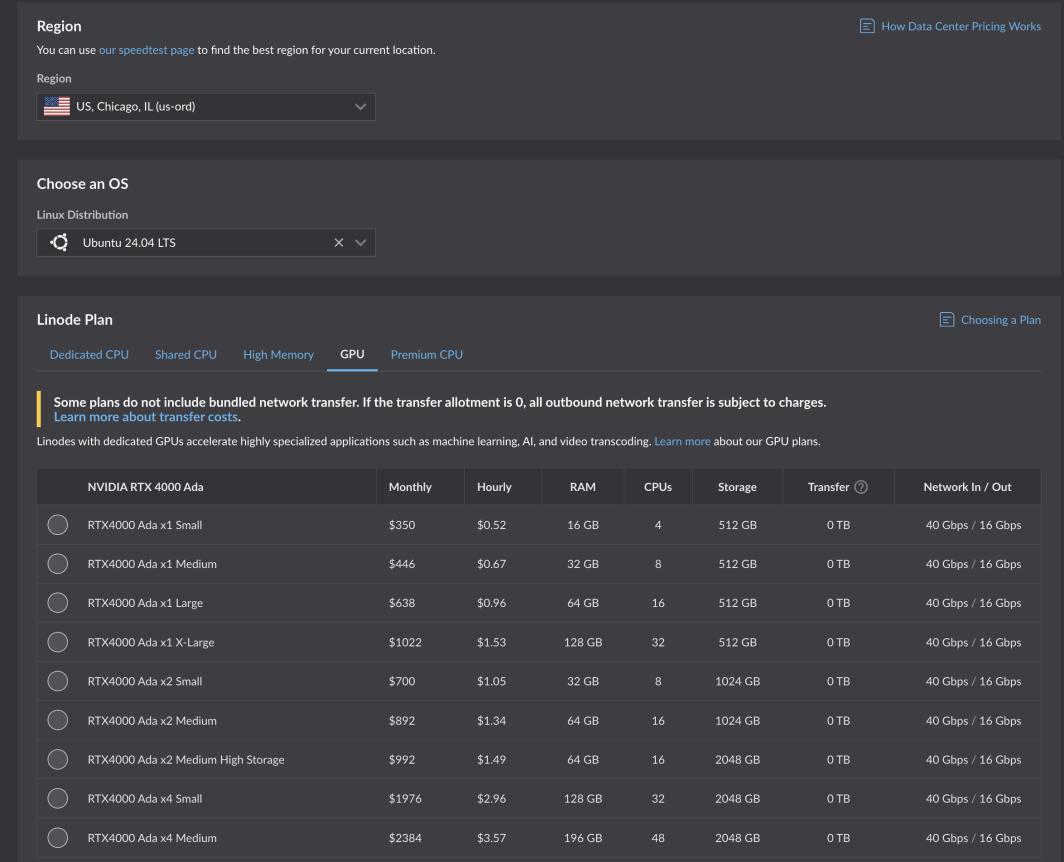
쉽지 않은 도전이었지만 기꺼이 받아들였습니다. 엄격한 테스트와 최적화를 거쳐 이제 모든 고객이 Akamai의 새로운 GPU를 사용할 수 있습니다. NVIDIA RTX 4000 Ada 세대 카드로 구동되는 이 GPU는 미디어 사용 사례에 최적화되어 있지만 다양한 워크로드 및 애플리케이션에 적합한 크기입니다. RTX 4000 Ada 세대의 요금제는 6개의 코어 컴퓨팅 영역에서 1개의 GPU, 4개의 CPU, 16GB RAM에 대해 시간당 $0.52부터 시작합니다:
- 시카고, 일리노이
- 시애틀, 워싱턴 주
- 프랑크푸르트, 독일 확장
- 파리, 프랑스
- 오사카, 일본
- 싱가포르, 싱가포르 확장
- 뭄바이, 인도 확장(출시 예정!)
사용 사례 하이라이트
베타 프로그램을 통해 고객과 독립 소프트웨어 공급업체(ISV) 파트너는 미디어 트랜스코딩 및 경량 AI와 같이 저희가 설계한 GPU 요금제 사양의 혜택을 받을 수 있는 주요 사용 사례를 포함하여 새로운 GPU를 테스트해 볼 수 있었습니다.
Capella Systems의 클라우드 호스팅 인코더인 Cambria Stream은 가장 까다로운 라이브 이벤트를 위한 라이브 인코딩, 광고 삽입, 암호화 및 패키징을 처리합니다. 최종 사용자가 다양한 디바이스와 네트워크 인프라에서 라이브 스트리밍 이벤트를 시청하려면 적절한 기술과 구성이 필요합니다.
"Akamai의 새로운 NVIDIA RTX 4000 Ada 세대 듀얼 GPU 을 사용하면 단일 캠브리아 스트림으로 최대 25개 채널의 멀티 레이어 인코딩을 한 번에 처리할 수 있어 CPU 기반 인코딩에 비해 총 컴퓨팅 비용을 크게 절감할 수 있습니다."
보도 자료 전문을 읽어보세요.
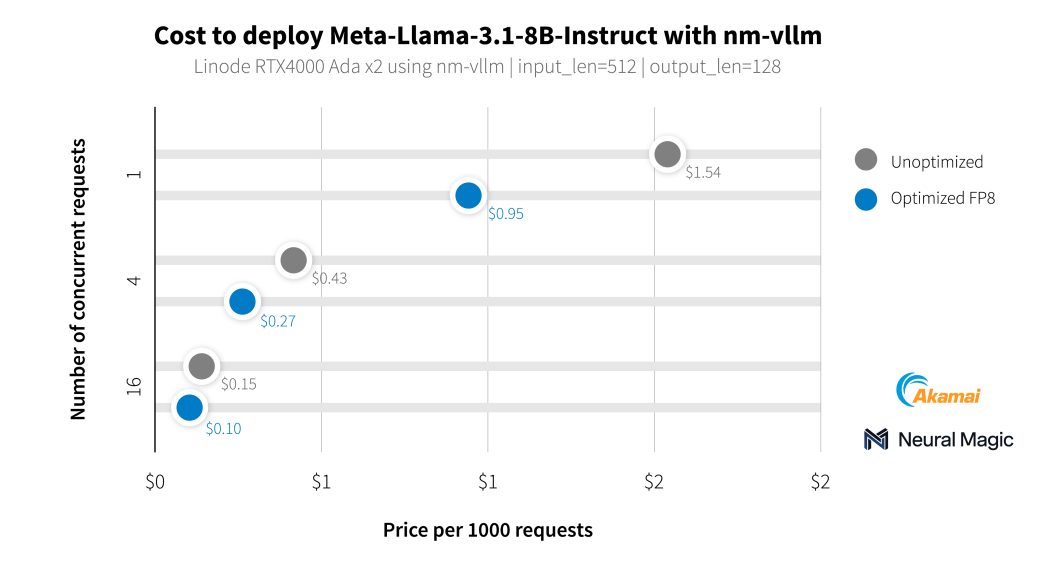
미디어 고객 외에도 Neural Magic과 협력하여 엔터프라이즈용 LLM 서비스 엔진인 nm-vllm을 사용해 새로운 GPU의 AI 기능을 벤치마킹했습니다. 이들은 LLM용 오픈 소스 압축 툴킷인 LLM 압축기를 사용하여 99.9%의 정확도를 유지하면서 훨씬 더 효율적인 배포를 생성했습니다. 최신 Llama 3.1 모델을 테스트하는 동안 Neural Magic은 소프트웨어 최적화를 활용하여 RTX 4000 GPU를 사용하여 1,000건의 요약 요청당 평균 0.27달러의 비용을 달성하여 레퍼런스 배포에 비해 60%의 비용을 절감했습니다.
시작하기
이미 계정이 있는 경우 바로 시작할 수 있습니다. 지원되는 지역을 선택하고 컴퓨팅 인스턴스 요금제 표의 GPU 탭으로 이동하기만 하면 됩니다.
문서로 시작하세요.
비즈니스 애플리케이션을 구축하고 관리하는 개발자는 Cloud 컨설턴트 팀에 문의하시기 바랍니다.
참고: Akamai GPU 인스턴스를 사용하려면 프로모션 코드를 제외하고 계정에 긍정적인 청구 내역이 있어야 합니다. 배포할 수 없고 GPU 접속이 필요한 경우 지원 티켓을 개설하세요.





내용