






私たちは最近、C++によるプロセス間通信ツールキットFlow-IPCを、Apache 2.0およびMITライセンスの下でオープンソースとしてリリースした。Flow-IPCは、アプリケーション・プロセス間でデータを伝送し、シンプルで再利用可能なコードとトレードオフすることなく、ほぼゼロのレイテンシーを達成する必要があるC++プロジェクトに有用である。
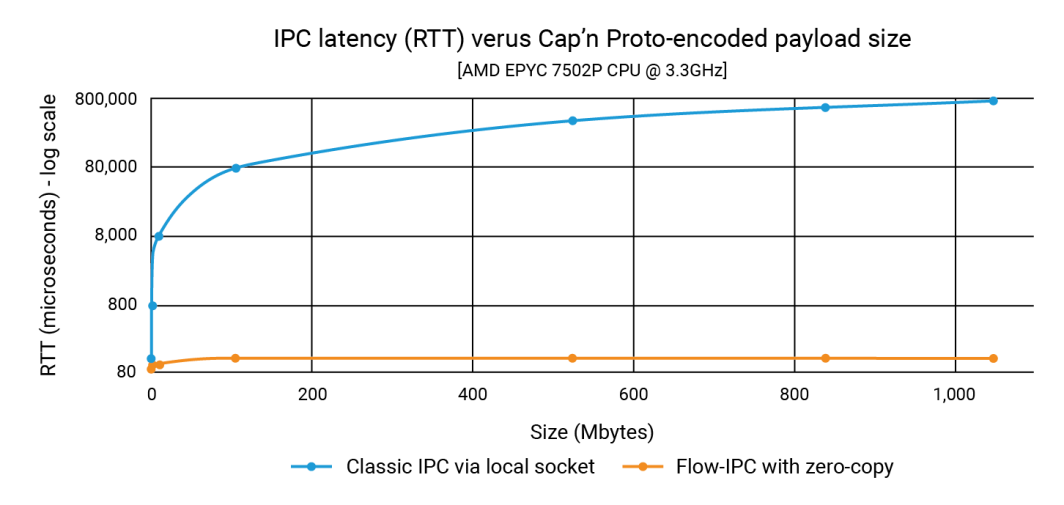
この発表では、Flow-IPCが1GBものデータ構造のペイロードを100Kのペイロードと同じ速さで、しかも100マイクロ秒以下で伝送できることを示しました。従来のIPCでは、レイテンシはペイロードサイズに依存し、1秒の範囲に達することもある。そのため、3桁から4桁の改善が可能です。
この投稿では、これらの数字を生み出したソースコードを紹介する。Cap'n Protoとの統合を中心としたこの例は、Flow-IPCが高速で使いやすいことを示している。(Flow-IPCのAPIは、様々な種類のペイロードの送信をサポートするという点で包括的であるが、Cap'n Protoベースのペイロード送信は特定の機能であることに注意)Cap'n Proto はアカマイとは関係のないオープンソースプロジェクトであり、その使用は、このブログの公開日現在、ここに記載されているライセンスに従うものとします。
何が含まれる?
Flow-IPCは、拡張可能なC++17 APIを備えたライブラリです。それは GitHubにホストされている 完全なドキュメント、自動化されたテストとデモ、CIパイプラインとともに。以下に紹介するのは perf_demo テスト・アプリケーション。Flow-IPCは現在、x86-64上で動作するLinuxをサポートしています。今後、macOSやARM64にも対応し、需要に応じてWindowsやその他のOSにも対応する予定です。あなたは 投稿歓迎 と港。
Flow-IPC APIは、C++標準ライブラリーと Boostの精神を受け継ぎ、さまざまな概念とその実装をモジュール方式で統合することに重点を置いている。拡張できるように設計されている。私たちのCIパイプラインは、ランタイム・サニタイザーによるハードニングを含め、GCCとClangコンパイラーのバージョンとビルド構成の範囲にわたってテストします:ASAN(メモリの誤用に対するハードニング)、TSAN(競合状態に対するハードニング)、UBSAN(未定義の雑多な振る舞いに対するハードニング)。
現時点では、Flow-IPCはローカル通信用であり、プロセス境界は越えるがマシン境界は越えない。しかし、Flow-IPCは拡張可能な設計であるため、ネットワークIPCへの拡張は自然な次のステップである。リモートダイレクトメモリアクセス(RDMA)の使用は、超高速LANパフォーマンスの興味深い可能性を提供すると考えています。
誰が使うべきか?
Flow-IPCは、実用的なプロセス間通信ツールキットです。このツールキットを設計するにあたり、私たちは現代のC++システム開発者の視点に立ち、特にサーバー・アプリケーション開発で繰り返し直面するIPCタスク向けにカスタマイズしました。私たちの多くは、あるプロセスから別のプロセスへ何かを送信するために、Unixドメイン・ソケット、名前付きパイプ、またはローカルのHTTPベースのプロトコルを組み合わせなければなりませんでした。時には、そのようなソリューションに含まれるコピーを回避するために、共有メモリ(SHM)に頼るかもしれません。Flow-IPCは、一般的なものから高度なものまで、このようなタスクに直面するC++開発者を支援します。
ハイライトは以下の通り:
- Cap'n Protoとの統合:Cap'n Protoのようなスキーマベースのインプレースシリアライゼーションツールは、プロセス間の作業に非常に役立つ。しかし、Flow-IPCがなければ、ビットをソケットやパイプなどにコピーし、受信時に再度コピーする必要があります。Flow-IPCは、共有メモリを使用して、Cap'n Protoエンコードされた構造体のエンドツーエンドのゼロコピー伝送を提供します。
- ソケット/FDのサポート:Flow-IPCを介して送信されるメッセージはすべて、ネイティブI/Oハンドル(ファイルディスクリプタまたはFDとしても知られる)を含むことができる。例えば、ウェブサーバーアーキテクチャでは、サーバーを2つのプロセス(エンドポイントを管理するプロセスとリクエストを処理するプロセス)に分けることができる。エンドポイントプロセスが TLS ネゴシエーションを完了すると、 接続された TCP ソケットハンドルをリクエスト処理プロセスに 直接渡すことができます。
- ネイティブのC++構造体をサポート: 多くのアルゴリズムは、C++で直接作業する必要がある
struct多くの場合、複数レベルのSTLコンテナやポインタを含むものである。このような構造で2つのスレッドが共同作業することは一般的であり、コーディングも容易である。 プロセス のような思慮深いツールを使っても、共有メモリ経由でこれを行うのはかなり難しい。 Boost.インタープロセス.Flow-IPCは、コンテナ、ポインタ、プレーンオールドデータなどのSTL準拠の構造体の共有を可能にすることで、これを簡素化する。 - jemalloc plus SHM:1行のコードで、Cap'n Proto伝送のような舞台裏の操作であろうと、C++のネイティブデータに対して直接であろうと、必要なデータを共有メモリに割り当てることができます。これらのタスクは、FreeBSDやMetaを支えるヒープエンジンであるjemallocに任せることができます。この機能は、通常のヒープ割り当てと同様に、集中的な共有メモリ割り当てを必要とするプロジェクトでは特に価値があります。
- 名前付けやクリーンアップに頭を悩ませることはありません:Flow-IPCでは、サーバーソケット、SHMセグメント、パイプに名前を付ける必要はなく、リークした永続RAMを心配する必要もありません。その代わりに、プロセス間でFlow-IPCセッションを 確立します:これがIPCコンテキストです。これがIPCコンテキストです。この単一のセッションオブジェクトから、追加の名前を付けることなく、通信チャネルを自由に開くことができます。直接共有メモリー(SHM)アクセスが必要なタスクでは、専用のSHMアリーナが利用できます。Flow-IPCは、異常終了の場合でも自動クリーンアップを実行し、リソース名の競合を回避します。
- RPCに使用する:Flow-IPCは、gRPCや Cap'n Proto RPCのような高レベルの通信フレームワークと競合するのではなく、補完するように設計されています。これらとFlow-IPCのどちらかを選択する必要はありません。実際、Flow-IPCのゼロコピー機能を使用することで、一般的にこれらのプロトコルのパフォーマンスを向上させることができます。
例マルチパートファイルの送信
Flow-IPCは様々な種類のデータを伝送することができるが、我々はCap'n Proto (capnp)スキーマによって記述されたデータ構造に焦点を当てることにした。この例は、capnpとProtocol Buffersに詳しい人には特にわかりやすいだろうが、これらのツールにあまり詳しくない人のために、十分な背景を説明する。
この例では、リクエストとレスポンスのシナリオを実行する2つのアプリがある。
- アプリ1(サーバー):100kbから1GBまでのファイルをあらかじめRAMにロードしておくメモリ・キャッシュ・サーバー。キャッシュされたファイルの取得リクエストを処理し、レスポンスを発行するために待機している。
- アプリ2(クライアント):このクライアントはあるサイズのファイルを要求する。アプリ1(サーバー)は、ファイルデータを一連のチャンクに分割した単一のメッセージで送信する。各チャンクにはハッシュとともにデータが含まれる。
# Cap'n Proto schema (.capnp file, generates .h and .c++ source code
# using capnp compiler tool):
$Cxx.namespace("cache_demo::schema");
struct Body
{
union
{
getCacheReq @0 :GetCacheReq;
getCacheRsp @1 :GetCacheRsp;
}
}
struct GetCacheReq
{
fileName @0 :Text;
}
struct GetCacheRsp
{
# We simulate the server returning file multiple parts,
# each (~equally) sized at its discretion.
struct FilePart
{
data @0 :Data;
dataSizeToVerify @1 :UInt64;
# Recipient can verify that `data` blob's size is indeed this.
dataHashToVerify @2 :Hash;
# Recipient can hash `data` and verify it is indeed this.
}
fileParts @0 :List(FilePart);
}この実験の目的は、Nサイズのファイルに対するリクエストを発行し、レスポンスを受け取り、処理にかかった時間を測定し、ファイルの一部の完全性をチェックすることである。この相互作用は通信チャネルを通じて行われる。
そのためには、まずこのチャネルを確立する必要がある。Flow-IPCでは、低レベルの構成要素(ローカルソケット、POSIXメッセージキューなど)から手動でチャネルを確立することができるが、代わりにFlow-IPCセッションを 使用する方がはるかに簡単である。セッションは、単に2つのライブプロセス間の通信コンテキストである。一度確立されれば、チャネルはすぐに利用できる。
俯瞰してみると、そのプロセスはこうだ。
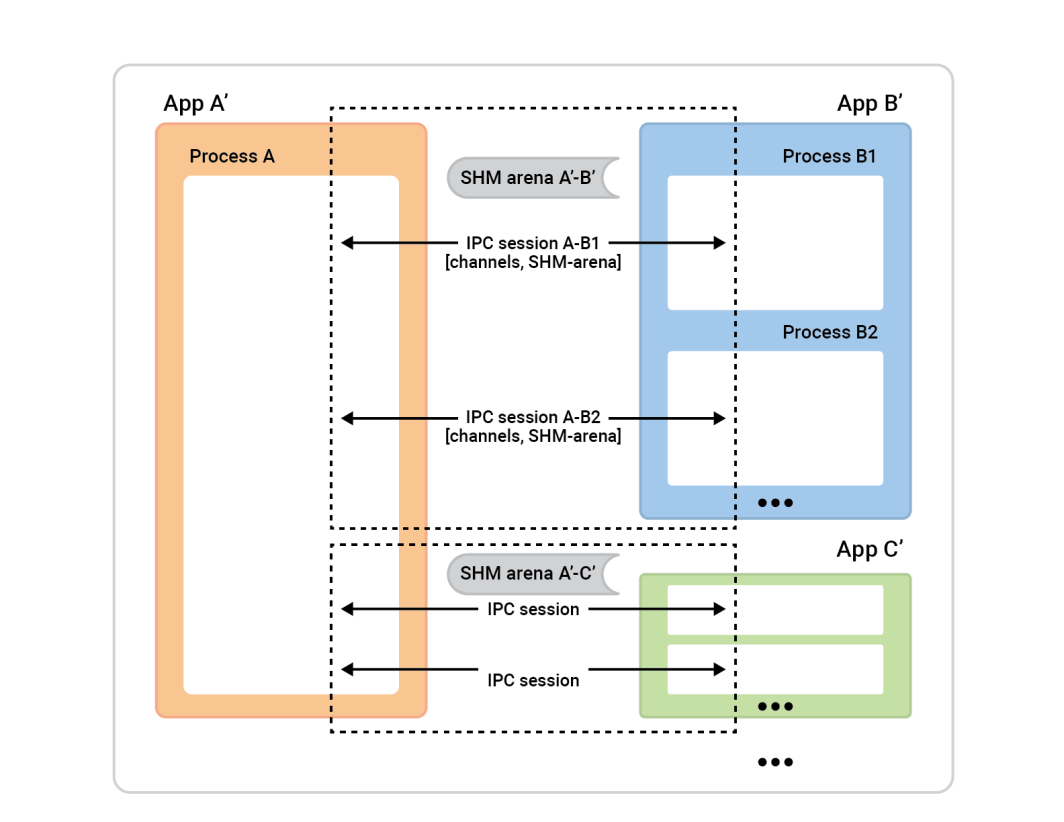
左側のプロセスAは セッションサーバーと呼ばれる。右側のプロセスボックス(セッ ションクライアント)は、セッションを確立するためにプロセスAに接続する。一般に、どのセッションも完全に対称なので、誰が接続を開始したかは問題ではない。双方が等しく能力を持ち、どのようなアルゴリズミックな役割も割り当てることができる。しかしセッションの準備ができる前に、役割を割り当てる必要がある。一方はセッションクライアントとなり、1つのセッションを瞬時に接続し、 もう一方はセッションサーバーとなり、望むだけのセッションを受け入れる 。
この例では、セットアップは簡単だ。2つのアプリの間に1つのセッションがあり、そのセッションに1つのチャネルがある。キャッシュクライアント(App 2)がセッションクライアントの役割を果たし、セッションサーバーの役割 はApp 1が担う。しかし、その逆でもうまくいくだろう。
これをセットアップするには、各アプリケーション(キャッシュ・クライアントとキャッシュ・サーバー)が同じIPCユニバースを理解しなければならない。
その理由はこうだ:
- クライアントは、セッションを開始するためにサーバーを見つける方法を知る必要がある。コネクティングアプリ(クライアント)であれば、アクセプティングアプリの名前を知る必要がある。Flow-IPCはサーバーの名前を使って、この名前に基づいてソケットアドレスや共有メモリセグメント名などの詳細を割り出す。
- サーバーアプリは、セキュリティ上の理由から、誰が接続を許可されているかを知っている必要があります。Flow-IPCは、ユーザー/グループや実行可能パスのようなクライアントの詳細をオペレーティングシステムと照合し、すべてが一致していることを確認します。
- OSの標準的な安全メカニズム(オーナー、パーミッション)は、さまざまなIPCトランスポート(ソケット、MQ、SHM)に適用される。単一のセレクタ
enumは使用するハイレベルポリシーを設定し、Flow-IPCはその選択を尊重しながら、可能な限り制限的にパーミッションを設定する。
私たちの場合、2つのアプリケーションのそれぞれで以下を実行するだけでよい。これは単一の .cpp ファイルは、キャッシュ・サーバーとキャッシュ・クライアントの両方のアプリにリンクされている。
// IPC app universe: simple structs naming the 2 apps.
// The applications should share this code.
const ipc::session::Client_app
CLI_APP{ "cacheCli", // Name the app uniquely.
// From where it will run (for safety).
"/usr/bin/cache_client.exec",
CLI_UID, GID }; // The user and group ID (for safety).
const ipc::session::Server_app
SRV_APP{ { "cacheSrv", "/usr/bin/cache_server.exec", SRV_UID, GID },
// For the server, provide similar details --^.
// Plus a few server-specific settings:
// Safety: List client-app names that can connect to server-app.
// So in our case this will just be { "cacheCli" }.
{ CLI_APP.m_name },
"", // An optional path override; don't worry about it here.
// Safety/permissions selector:
// We've decided to run the two apps as different users
// in the same group - so we indicate that here.
ipc::util::Permissions_level::S_GROUP_ACCESS }; より複雑なセットアップでは、これらの定義がより多くなる可能性があることに注意。
それぞれのアプリケーションでこのコードを実行した後、これらのオブジェクトをセッションオブジェクトのコンストラクタに渡すだけで、サーバーはセッションを受け入れるときに何を期待すればよいかがわかり、クライアントはどのサーバーに接続すればよいかがわかるようになります。
では、セッションを開いてみよう。アプリ2(キャッシュクライアント)では、セッションとその中のチャンネルを開きたいだけです。Flow-IPCでは、(セッションオブジェクトが与えられれば)いつでも即座にチャンネルを開くことができるが、セッションの開始時には、ある程度の数のすぐに使えるチャンネルが必要になるのが一般的である。私たちは1つのチャンネルを開きたいので、セッションを作成するときにFlow-IPCにチャンネルを作成させることができる。これにより、不必要な非同期性を避けることができる。したがって、キャッシュクライアントの main() 関数を使えば、1つの .sync_connect() コール:
// Specify that we *do* want zero-copy behavior, by merely choosing our
// backing-session type.
// In other words, setting this alias says, “be fast about Cap’n Proto things.”
//
// Different (subsequent) capnp-serialization-backing and SHM-related behaviors
// are available; just change this alias. E.g., omit `::shm::classic` to disable
// SHM entirely; or specify `::shm::arena_lend::jemalloc` to employ
// jemalloc-based SHM. Subsequent code remains the same!
// This demonstrates a key design tenet of Flow-IPC.
using Session = ipc::session::shm::classic::Client_session<...>;
// Tell Session object about the applications involved.
Session session{ CLI_APP, SRV_APP, /* detail omitted */ };
// Ask for 1 *channel* to be available on both sides
// from the very start of the session.
Session::Channels ipc_raw_channels(1);
// Instantly open session - and the 1 channel.
// (Fail if server is not running at this time.)
session.sync_connect(session.mdt_builder(), &ipc_raw_channels);
auto& ipc_raw_channel = ipc_raw_channels[0];
// (Can also instantly open more channel(s) anytime:
// `session.open_channel(&channel)`.)
を持つべきだ。 ipc_raw_channel これは基本的なチャネルオブジェクトである。特定の設定次第では、これはUnixドメインのストリームソケットやPOSIX MQ、あるいは他のタイプのチャネルを表すことができる。やろうと思えば、これを 不定形 つまり、(境界が保持された)バイナリー・ブロブやネイティブ・ハンドル(FD)を送信するために使うことができる。また、SHMアリーナに直接アクセスすることもできる。 session.session_shm()->construct<T>(...).これは今回の議論の範囲外だが、特筆すべき強力な能力だ。
とりあえず、キャプテン・プロトについて話したい。 cache_demo::schema::Body .capnpファイルから)。そこで アップグレード 生のチャンネルオブジェクトを 構造化チャネル オブジェクトのようなものだ:
// Template arg indicates capnp schema. (Take a look at the .capnp file above.)
Session::Structured_channel<cache_demo::schema::Body>
ipc_channel
{ nullptr, std::move(ipc_raw_channel), “Eat” the raw channel: take over it.
ipc::transport::struc::Channel_base::S_SERIALIZE_VIA_SESSION_SHM,
&session }; セットアップは以上だ。これで、チャネル上でcapnpメッセージを交換する準備ができた。オブジェクト名やUnixのパーミッションの値など、OS特有の詳細を扱うことを避けたことに注目してほしい。我々のアプローチは、単に2つのアプリケーションに名前をつけるだけである。また、エンド・ツー・エンドのゼロコピー転送を選択し、共有メモリーを活用することでパフォーマンスを最大化した。 ::shm_open() または ::mmap() が見える。
さて、お楽しみの準備は整った。 GetCacheReq リクエストを受信する。 GetCacheRsp レスポンスにアクセスし、そのレスポンスのさまざまな部分、すなわちファイル部分とそのハッシュにアクセスする。
これがコードだ:
// Issue request and process response. TIMING FOR LATENCY GRAPH STARTS HERE -->
auto req_msg = ipc_channel.create_msg();
req_msg.body_root() // Vanilla capnp code: call Cap'n Proto-generated mutator API.
->initGetCacheReq().setFileName("huge-file.bin");
// Send message; get ~instant reply.
const auto rsp_msg = ipc_channel.sync_request(req_msg);
// More vanilla capnp work: accessors.
const auto rsp_root = rsp_msg->body_root().getGetCacheRsp();
// <-- TIMING FOR LATENCY GRAPH STOPS HERE.
// ...
verify_hash(rsp_root, some_file_chunk_idx);
// ...
// More vanilla Cap'n Proto accessor code.
void verify_hash(const cache_demo::schema::GetCacheRsp::Reader& rsp_root,
size_t idx)
{
const auto file_part = rsp_root.getFileParts()[idx];
if (file_part.getHashToVerify() != compute_hash(file_part.getData()))
{
throw Bad_hash_exception(...);
}
} 上のコードでは、単純な .sync_request() メッセージを送り、特定の応答を待つ。これは ipc::transport::struc::Channel 非同期受信、メッセージタイプによるハンドラ関数へのデマルチプレクス、notification対request、unsolicited-message対responseなどだ。スキーマに制限はありません (cache_demo::schema::Body 我々の場合)。capnpで表現可能であれば、Flow-IPCの構造化チャンネルで使用できる。
それだけだ!サーバーサイドも、その精神と難易度は似ている。その perf_demo ソースコードはこちら。
Flow-IPCがなければ、エンドツーエンドのゼロコピーのパフォーマンスのためにこのセットアップを複製することは、名前とクリーンアップを2つのアプリケーション間で調整する必要があるSHMセグメントの管理を含む、かなりの量の困難なコードを伴うことになる。ゼロコピーなしでも、つまり単に::write()のcapnpシリアライズのコピーを作成する。 req_msg そして ::read()イング rsp_msg それに比べれば、十分に堅牢なコードを書くことは容易ではない。
下のグラフは、X軸の各ポイントがすべてのレイテンシーの合計を表している。 filePart.data のサイズを示している。青い線は、アプリ1がcapnpシリアライゼーションをUnixドメインソケットに書き込む基本的な方法によるレイテンシを示しています。 ::write()で読み、App 2は ::read().オレンジの線は、前述したFlow-IPCを使用したコードのレイテンシを表している。
寄付の方法
機能リクエストや不具合報告については、Flow-IPC GitHubサイトのIssueデータベースをご覧ください。必要に応じてIssueをファイルしてください。
変更や新機能の投稿については、投稿ガイドをご参照ください。GitHubのFlow-IPCディスカッションボードまでご連絡ください。
次はどうする?
上記の例では、現実的な実験を提供するよう努め、示したコードの中で重要なものは何も省略していない。非同期性やコールバックがないシナリオを意図的に選んだ。従って、"Flow-IPCをイベントループにどのように統合すればよいのか"、"セッションとチャネルのクローズをどのように処理すればよいのか "といった疑問が生じるだろう。セッションのようなものを使わずに、単純なストリームソケットを開くことはできるのか?
そのような質問には、完全なドキュメントで対応している。ドキュメントには、コード中のAPIコメントから生成されたリファレンス、より穏やかな学習曲線を持つガイド付きマニュアル、インストール手順が含まれています。メインリポジトリのREADMEは、これらすべてのリソースを紹介しています。マニュアルのイントロと APIの概要は、利用可能な機能の幅をカバーしています。
リソース
- 発表ブログ記事
- GitHubのFlow-IPCプロジェクト
インストール、ドキュメントの閲覧、機能/変更リクエストの提出、貢献はこちらから。 - Flow-IPCディスカッション
私たち、そして他のコミュニティーに連絡する素晴らしい方法です。


コメント