






誰に尋ねるかにもよるが、人工知能 のブームは、クラウド上の強力なGPUにアクセスするのが簡単であることを意味する。問題は、現実的に必要としないハードウェア・リソースに過剰な支払いをすることなく、適切な プロバイダーで適切な GPU 。
これは大変な挑戦でしたが、喜んで引き受けました。厳密なテストと最適化を経て、アカマイの新しい GPU はすべてのお客様にご利用いただけるようになりました。NVIDIA RTX 4000 Ada Generation カードを搭載したこれらの GPU は、メディアのユースケース向けに最適化されていますが、さまざまなワークロードやアプリケーションに適したサイズとなっています。RTX 4000 Ada Generationプランは、6つのコア・コンピュート・リージョンで1GPU 、4CPU、16GBのRAMを1時間あたり0.52ドルからご利用いただけます:
- シカゴ、イリノイ州(米国)
- シアトル、WA
- フランクフルト、DE エクスパンション
- パリ、フランス
- 大阪, JP
- シンガポール、SG進出
- ムンバイ(インディアナ州)進出(近日発表
ユースケース・ハイライト
ベータ・プログラムを通じて、当社の顧客と独立系ソフトウェア・ベンダー(ISV)パートナーは、当社が設計したGPU プラン仕様の恩恵を受けるとわかっていた主な使用例(メディア・トランスコーディングと軽量人工知能 )を含め、当社の新しいGPUをテストすることができました。
カペラシステムズのクラウドホスト型エンコーダー、Cambria Streamは、最も要求の厳しいライブイベントのライブエンコーディング、広告挿入、暗号化、パッケージングを行います。エンドユーザーがあらゆるデバイスやネットワークインフラからライブストリーミングイベントを視聴するためには、舞台裏で適切な技術と設定が必要です。
"アカマイの新しいNVIDIA RTX 4000 Ada Generation DualGPU を使用することで、1 台の Cambria Stream で最大 25 チャンネルのマルチレイヤーエンコーディングを同時に処理することができ、CPU ベースのエンコーディングと比較して総コンピューティングコストを大幅に削減できます。"
プレスリリース全文を読む
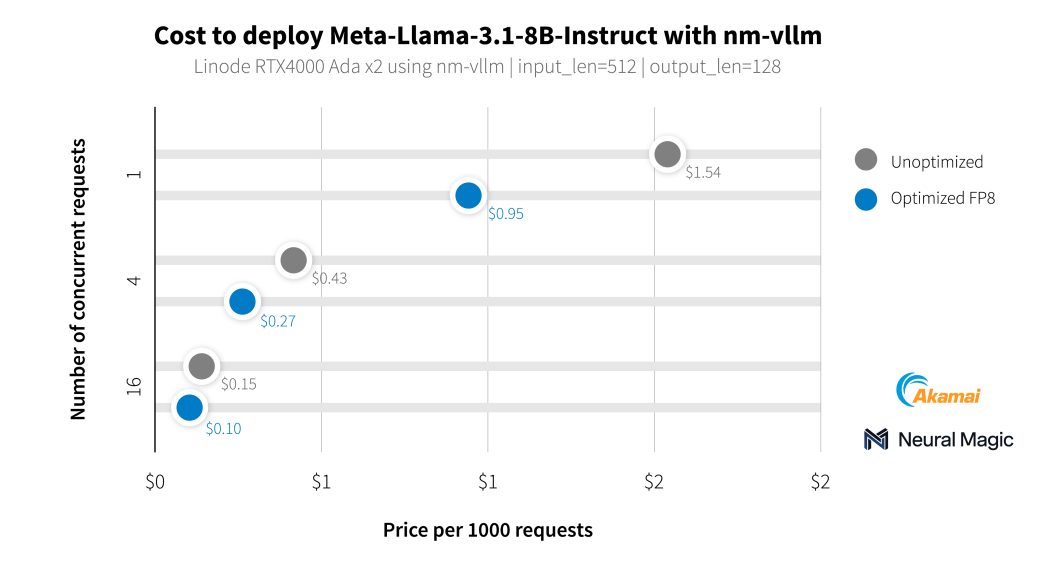
メディア関係者だけでなく、私たちはNeural Magic社と協力して、同社のエンタープライズ対応LLMサービングエンジンであるnm-vllmを使用して、新しいGPUの人工知能 機能のベンチマークを行いました。彼らは、彼らのLLM用オープンソース圧縮ツールキットであるLLM Compressorを利用し、99.9%の精度を維持した、より効率的なデプロイメントを行いました。最新のLlama 3.1モデルをテストしている間、Neural MagicはRTX 4000 GPUを使用して、1,000要約リクエストあたりの平均コスト0.27ドルを達成するために彼らのソフトウェアの最適化を利用しました。
始めてみる
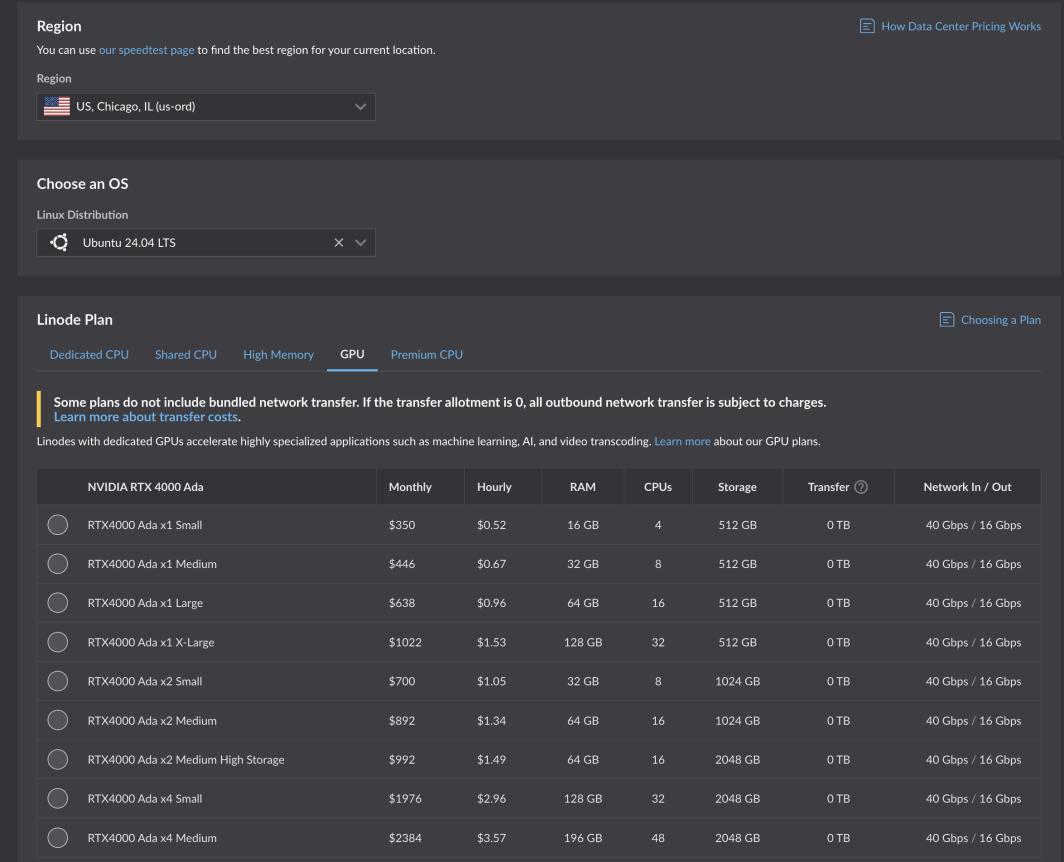
すでにアカウントをお持ちの場合は、すぐに始めることができます。サポートされているリージョンを選択し、コンピュート・インスタンス・プラン表のGPU タブに移動するだけです。
まずはドキュメントをご覧ください。
ビジネス・アプリケーションを構築・管理する開発者は、当社のクラウド・コンサルタント・チームにご相談ください。
注: アカマイGPU インスタンスのご利用には、プロモコードを含めず、お客様のアカウントにプラスの請求履歴があることが必要です。デプロイできず、GPU アクセスが必要な場合は、サポートチケットをご請求ください。





コメント