

Abbiamo recentemente rilasciato Flow-IPC - un toolkit per la comunicazione tra processi in C++ - come open source sotto le licenze Apache 2.0 e MIT. Flow-IPC sarà utile per i progetti in C++ che trasmettono dati tra processi applicativi e hanno bisogno di ottenere una latenza prossima allo zero senza dover rinunciare a un codice semplice e riutilizzabile.
Nell'annuncio abbiamo dimostrato che Flow-IPC è in grado di trasmettere payload di strutture dati grandi 1 GB con la stessa velocità di un payload da 100K, e in meno di 100 microsecondi. Con l'IPC classico, la latenza dipende dalle dimensioni del payload e può raggiungere 1 secondo. Il miglioramento può quindi essere di tre o quattro ordini di grandezza.
In questo post mostriamo il codice sorgente che ha prodotto questi numeri. Il nostro esempio, incentrato sull'integrazione con Cap'n Proto, dimostra che Flow-IPC è veloce e facile da usare. (Si noti che l'API di Flow-IPC è completa e supporta la trasmissione di vari tipi di payload, ma la trasmissione di payload basata su Cap'n Proto è una funzione specifica). Cap'n Proto è un progetto open source non affiliato ad Akamai il cui utilizzo è soggetto alla licenza, alla data di pubblicazione di questo blog, che si trova qui.
Cosa è incluso?
Flow-IPC è una libreria con un'API C++17 estensibile. È ospitato su GitHub insieme a una documentazione completa, test e demo automatizzati e una pipeline CI. L'esempio che esploriamo qui di seguito è il perf_demo applicazione di prova. Flow-IPC supporta attualmente Linux in esecuzione su x86-64. Abbiamo in programma di estendere il supporto a macOS e ARM64, quindi a Windows e ad altre varianti del sistema operativo, a seconda della domanda. Siete benvenuti a contribuire e porto.
L'API di Flow-IPC si ispira allo spirito della libreria standard C++ e di Boost, concentrandosi sull'integrazione di vari concetti e delle loro implementazioni in modo modulare. È progettata per essere estensibile. La nostra pipeline CI esegue test su un'ampia gamma di versioni di compilatori GCC e Clang e di configurazioni di compilazione, compreso l'hardening tramite sanificatori di runtime: ASAN (contro l'uso improprio della memoria), TSAN (contro le condizioni di gara) e UBSAN (contro vari comportamenti non definiti).
Al momento, Flow-IPC è destinato alla comunicazione locale: attraversa i confini del processo ma non quelli della macchina. Tuttavia, il progetto è estensibile e l'espansione a IPC in rete è un passo successivo naturale. Riteniamo che l'uso di Remote Direct Memory Access (RDMA) offra una possibilità interessante per ottenere prestazioni ultraveloci su LAN.
Chi dovrebbe usarlo?
Flow-IPC è un toolkit pragmatico per la comunicazione tra processi. Nel progettarlo, ci siamo mossi dal punto di vista del moderno sviluppatore di sistemi C++, adattandolo specificamente ai compiti IPC che si devono affrontare ripetutamente, in particolare nello sviluppo di applicazioni server. Molti di noi hanno dovuto mettere insieme un Unix-domain-socket, un named-pipe o un protocollo locale basato su HTTP per trasmettere qualcosa da un processo all'altro. A volte, per evitare la copia che tali soluzioni comportano, si ricorre alla memoria condivisa (SHM), una tecnica notoriamente difficile da riutilizzare. Flow-IPC può aiutare qualsiasi sviluppatore C++ che si trovi ad affrontare compiti di questo tipo, da quelli più comuni a quelli più avanzati.
I punti salienti includono:
- Integrazione con Cap'n Proto: Gli strumenti per la serializzazione basata su schema in-place come Cap'n Proto, che è il migliore della categoria, sono molto utili per il lavoro inter-processo. Tuttavia, senza Flow-IPC, è necessario copiare i bit in un socket o in una pipe, e così via, per poi copiarli di nuovo al momento della ricezione. Flow-IPC fornisce una trasmissione end-to-end a copia zero di strutture codificate da Cap'n Proto utilizzando la memoria condivisa.
- Supporto Socket/FD: Qualsiasi messaggio trasmesso tramite Flow-IPC può includere un handle I/O nativo (noto anche come descrittore di file o FD). Ad esempio, in un'architettura di server web, è possibile dividere il server in due processi: un processo per la gestione degli endpoint e un processo per l'elaborazione delle richieste. Dopo che il processo di endpoint ha completato la negoziazione TLS, può passare l'handle del socket TCP connesso direttamente al processo di elaborazione delle richieste.
- Supporto nativo delle strutture C++: Molti algoritmi richiedono di lavorare direttamente su C++
structil più delle volte si tratta di strutture che coinvolgono più livelli di contenitori STL e/o di puntatori. Due thread che collaborano su una struttura di questo tipo sono comuni e facili da codificare, mentre due processi farlo attraverso la memoria condivisa è abbastanza difficile, anche con strumenti intelligenti come Boost.interprocess. Flow-IPC semplifica questo aspetto consentendo la condivisione di strutture conformi a STL, come contenitori, puntatori e semplici dati. - jemalloc più SHM: una riga di codice permette di allocare qualsiasi dato necessario nella memoria condivisa, sia per operazioni dietro le quinte come la trasmissione di Cap'n Proto, sia direttamente per i dati nativi del C++. Questi compiti possono essere delegati a jemalloc, il motore heap di FreeBSD e Meta. Questa funzione può essere particolarmente preziosa per i progetti che richiedono un'allocazione intensiva della memoria condivisa, simile alla normale allocazione dell'heap.
- Nessun problema di denominazione o di pulizia: Con Flow-IPC, non è necessario assegnare nomi a server-socket, segmenti SHM o pipe, né preoccuparsi di perdite di RAM persistente. È sufficiente stabilire una sessione Flow-IPC tra i processi: questo è il contesto IPC. Da questo singolo oggetto di sessione, i canali di comunicazione possono essere aperti a piacere, senza ulteriori nomi. Per i compiti che richiedono l'accesso diretto alla memoria condivisa (SHM), è disponibile un'arena SHM dedicata. Flow-IPC esegue una pulizia automatica, anche in caso di uscita anomala, ed evita i conflitti tra i nomi delle risorse.
- Utilizzo per RPC: Flow-IPC è stato progettato per integrare, non per competere con framework di comunicazione di livello superiore come gRPC e Cap'n Proto RPC. Non è necessario scegliere tra questi e Flow-IPC. Anzi, l'uso delle funzioni zero-copy di Flow-IPC può generalmente migliorare le prestazioni di questi protocolli.
Esempio: Invio di un file in più parti
Sebbene Flow-IPC possa trasmettere dati di vario tipo, abbiamo deciso di concentrarci su una struttura di dati descritta da uno schema Cap'n Proto (capnp). Questo esempio sarà particolarmente chiaro per coloro che hanno familiarità con capnp e con i buffer di protocollo, ma forniremo un ampio contesto per coloro che hanno meno familiarità con questi strumenti.
In questo esempio, ci sono due applicazioni che si impegnano in uno scenario di richiesta-risposta.
- App 1 (server): Si tratta di un server di cache di memoria che ha precaricato nella RAM file che vanno da 100kb a 1GB. È pronto a gestire le richieste di file nella cache e a fornire risposte.
- App 2 (client): Questo client richiede un file di una certa dimensione. L'App 1 (server) invia i dati del file in un unico messaggio suddiviso in una serie di chunk. Ogni chunk comprende i dati e il loro hash.
# Cap'n Proto schema (.capnp file, generates .h and .c++ source code
# using capnp compiler tool):
$Cxx.namespace("cache_demo::schema");
struct Body
{
union
{
getCacheReq @0 :GetCacheReq;
getCacheRsp @1 :GetCacheRsp;
}
}
struct GetCacheReq
{
fileName @0 :Text;
}
struct GetCacheRsp
{
# We simulate the server returning file multiple parts,
# each (~equally) sized at its discretion.
struct FilePart
{
data @0 :Data;
dataSizeToVerify @1 :UInt64;
# Recipient can verify that `data` blob's size is indeed this.
dataHashToVerify @2 :Hash;
# Recipient can hash `data` and verify it is indeed this.
}
fileParts @0 :List(FilePart);
}Il nostro obiettivo in questo esperimento è quello di inviare una richiesta per un file di dimensioni N, ricevere la risposta, misurare il tempo di elaborazione e verificare l'integrità di una parte del file. Questa interazione avviene attraverso un canale di comunicazione.
Per fare ciò, dobbiamo prima stabilire questo canale. Sebbene Flow-IPC consenta di stabilire manualmente un canale dai suoi componenti di basso livello (socket locale, coda di messaggi POSIX e altro), è molto più semplice utilizzare le sessioni di Flow-IPC. Una sessione è semplicemente il contesto di comunicazione tra due processi attivi. Una volta creata, i canali sono immediatamente disponibili.
Ecco come funziona il processo da una prospettiva a volo d'uccello.
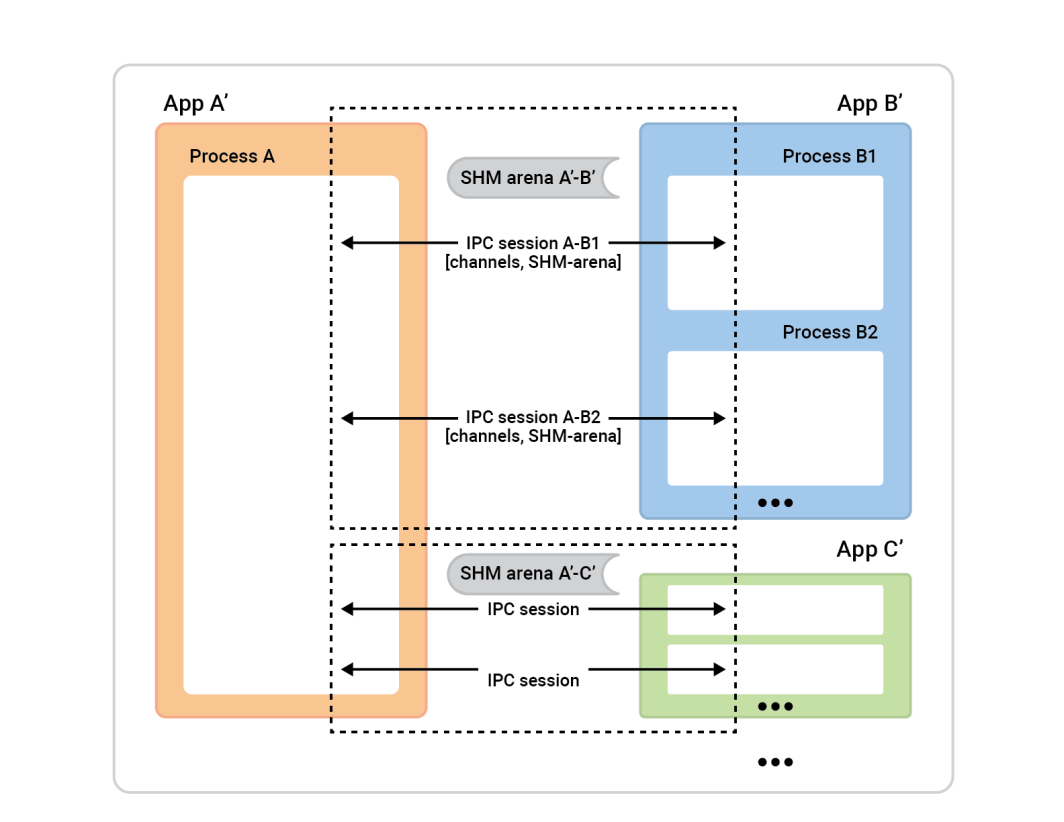
Il processo A a sinistra è chiamato session-server. Le caselle di processo a destra - i client di sessione - si connettono al processo A per stabilire le sessioni. In genere, ogni sessione è completamente simmetrica, quindi non importa chi ha iniziato la connessione. Entrambe le parti sono ugualmente capaci e possono essere assegnate a qualsiasi ruolo algoritmico. Prima che la sessione sia pronta, però, è necessario assegnare i ruoli. Una parte sarà il session-client ed eseguirà una connessione istantanea di una singola sessione, mentre l'altra parte, il session-server, accetterà tutte le sessioni che desidera.
In questo esempio, la configurazione è semplice. Ci sono due applicazioni con una sessione tra loro e un canale in quella sessione. Il cache-client (App 2) svolge il ruolo di session-client e il ruolo di session-server è assunto dall'App 1. Tuttavia, anche il contrario funzionerebbe bene. Tuttavia, anche l'inverso funzionerebbe bene.
Per configurare questo sistema, ogni applicazione (il cache-client e il cache-server) deve comprendere lo stesso universo IPC, il che significa che devono conoscere le informazioni di base sulle applicazioni coinvolte.
Ecco perché:
- Il client deve sapere come individuare il server per avviare una sessione. Se si è la connecting-app (il client), è necessario conoscere il nome dell'accepting-app. Flow-IPC utilizza il nome del server per determinare dettagli come gli indirizzi dei socket e i nomi dei segmenti di memoria condivisa in base a questo nome.
- Per motivi di sicurezza, l'applicazione server deve sapere chi è autorizzato a connettersi. Flow-IPC controlla i dettagli del client, come utente/gruppo e percorso dell'eseguibile, rispetto al sistema operativo per assicurarsi che tutto corrisponda.
- I meccanismi di sicurezza standard del sistema operativo (proprietari, permessi) si applicano ai vari trasporti IPC (socket, MQ, SHM). Un singolo selettore
enumimposterà il criterio di alto livello da utilizzare e Flow-IPC imposterà i permessi nel modo più restrittivo possibile, rispettando tale scelta.
Per noi sarà sufficiente eseguire quanto segue in ciascuna delle due applicazioni. Questo può avvenire in un singolo .cpp collegato a entrambe le applicazioni cache-server e cache-client.
// IPC app universe: simple structs naming the 2 apps.
// The applications should share this code.
const ipc::session::Client_app
CLI_APP{ "cacheCli", // Name the app uniquely.
// From where it will run (for safety).
"/usr/bin/cache_client.exec",
CLI_UID, GID }; // The user and group ID (for safety).
const ipc::session::Server_app
SRV_APP{ { "cacheSrv", "/usr/bin/cache_server.exec", SRV_UID, GID },
// For the server, provide similar details --^.
// Plus a few server-specific settings:
// Safety: List client-app names that can connect to server-app.
// So in our case this will just be { "cacheCli" }.
{ CLI_APP.m_name },
"", // An optional path override; don't worry about it here.
// Safety/permissions selector:
// We've decided to run the two apps as different users
// in the same group - so we indicate that here.
ipc::util::Permissions_level::S_GROUP_ACCESS }; Si noti che le configurazioni più complesse possono avere più definizioni.
Dopo aver eseguito questo codice in ciascuna delle nostre applicazioni, passeremo semplicemente questi oggetti nel costruttore dell'oggetto sessione, in modo che il server sappia cosa aspettarsi quando accetta le sessioni e il client sappia a quale server connettersi.
Apriamo quindi la sessione. Nell'App 2 (il cache-client), vogliamo solo aprire una sessione e un canale al suo interno. Sebbene Flow-IPC consenta di aprire istantaneamente i canali in qualsiasi momento (dato un oggetto sessione), è tipico avere bisogno di un certo numero di canali pronti all'uso all'inizio della sessione. Poiché vogliamo aprire un solo canale, possiamo lasciare che Flow-IPC crei il canale durante la creazione della sessione. In questo modo si evitano inutili asincronie. Quindi, all'inizio della sessione del nostro client cache main() possiamo connettere e aprire un canale con una singola funzione .sync_connect() chiamata:
// Specify that we *do* want zero-copy behavior, by merely choosing our
// backing-session type.
// In other words, setting this alias says, “be fast about Cap’n Proto things.”
//
// Different (subsequent) capnp-serialization-backing and SHM-related behaviors
// are available; just change this alias. E.g., omit `::shm::classic` to disable
// SHM entirely; or specify `::shm::arena_lend::jemalloc` to employ
// jemalloc-based SHM. Subsequent code remains the same!
// This demonstrates a key design tenet of Flow-IPC.
using Session = ipc::session::shm::classic::Client_session<...>;
// Tell Session object about the applications involved.
Session session{ CLI_APP, SRV_APP, /* detail omitted */ };
// Ask for 1 *channel* to be available on both sides
// from the very start of the session.
Session::Channels ipc_raw_channels(1);
// Instantly open session - and the 1 channel.
// (Fail if server is not running at this time.)
session.sync_connect(session.mdt_builder(), &ipc_raw_channels);
auto& ipc_raw_channel = ipc_raw_channels[0];
// (Can also instantly open more channel(s) anytime:
// `session.open_channel(&channel)`.)
Dovremmo avere un ipc_raw_channel ora, che è un oggetto canale di base. A seconda delle impostazioni specifiche, potrebbe rappresentare uno stream socket di dominio Unix, un MQ POSIX o altri tipi di canali. Se volessimo, potremmo usarlo in non strutturato immediatamente, il che significa che possiamo usarlo per trasmettere blob binari (con i confini preservati) e/o handle nativi (FD). Si può anche accedere direttamente a un'arena SHM tramite session.session_shm()->construct<T>(...). Questo aspetto esula dalla nostra discussione, ma è una funzionalità potente che merita di essere menzionata.
Per ora, vogliamo solo parlare del Cap'n Proto cache_demo::schema::Body (dal nostro file .capnp). Quindi aggiornamento l'oggetto canale grezzo a un oggetto canale strutturato come segue:
// Template arg indicates capnp schema. (Take a look at the .capnp file above.)
Session::Structured_channel<cache_demo::schema::Body>
ipc_channel
{ nullptr, std::move(ipc_raw_channel), “Eat” the raw channel: take over it.
ipc::transport::struc::Channel_base::S_SERIALIZE_VIA_SESSION_SHM,
&session }; Questo è tutto per la nostra configurazione. Ora siamo pronti a scambiare messaggi capnp sul canale. Si noti che abbiamo evitato di occuparci di dettagli specifici del sistema operativo, come i nomi degli oggetti, i valori dei permessi Unix e così via. Il nostro approccio è stato semplicemente quello di dare un nome alle nostre due applicazioni. Abbiamo anche optato per una trasmissione end-to-end zero-copy per massimizzare le prestazioni sfruttando la memoria condivisa senza un singolo ::shm_open() o ::mmap() in vista.
Ora siamo pronti per la parte più divertente: l'emissione del file GetCacheReq richiesta, ricevendo il GetCacheRsp e accedere a varie parti della risposta, in particolare alle parti dei file e ai loro hash.
Ecco il codice:
// Issue request and process response. TIMING FOR LATENCY GRAPH STARTS HERE -->
auto req_msg = ipc_channel.create_msg();
req_msg.body_root() // Vanilla capnp code: call Cap'n Proto-generated mutator API.
->initGetCacheReq().setFileName("huge-file.bin");
// Send message; get ~instant reply.
const auto rsp_msg = ipc_channel.sync_request(req_msg);
// More vanilla capnp work: accessors.
const auto rsp_root = rsp_msg->body_root().getGetCacheRsp();
// <-- TIMING FOR LATENCY GRAPH STOPS HERE.
// ...
verify_hash(rsp_root, some_file_chunk_idx);
// ...
// More vanilla Cap'n Proto accessor code.
void verify_hash(const cache_demo::schema::GetCacheRsp::Reader& rsp_root,
size_t idx)
{
const auto file_part = rsp_root.getFileParts()[idx];
if (file_part.getHashToVerify() != compute_hash(file_part.getData()))
{
throw Bad_hash_exception(...);
}
} Nel codice precedente abbiamo utilizzato il semplice metodo .sync_request() che invia un messaggio e attende una risposta specifica. Il ipc::transport::struc::Channel L'API fornisce una serie di accorgimenti per rendere i protocolli naturali per il codice, tra cui la ricezione asincrona, il demultiplexing alle funzioni di gestione per tipo di messaggio, la notifica rispetto alla richiesta e il messaggio non richiesto rispetto alla risposta. Non ci sono restrizioni allo schema (cache_demo::schema::Body nel nostro caso). Se è esprimibile in capnp, è possibile utilizzarlo con i canali strutturati Flow-IPC.
Tutto qui! Il lato server è simile per spirito e livello di difficoltà. Il perf_demo è disponibile il codice sorgente.
Senza Flow-IPC, replicare questa configurazione per ottenere prestazioni end-to-end zero-copy comporterebbe una quantità significativa di codice difficile, compresa la gestione dei segmenti SHM i cui nomi e la cui pulizia dovrebbero essere coordinati tra le due applicazioni. Anche senza zero-copy, cioè semplicemente con ::write()una copia della serializzazione capnp di req_msg a e ::read()ing rsp_msg da un socket FD di dominio Unix: in confronto, la scrittura di codice sufficientemente robusto non sarebbe banale.
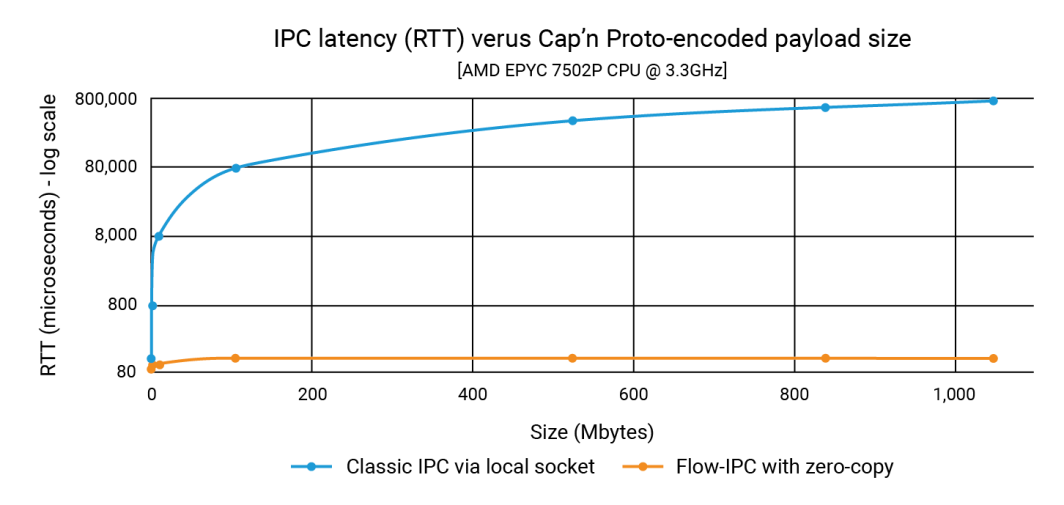
Il grafico seguente mostra le latenze, in cui ogni punto sull'asse delle ascisse rappresenta la somma di tutti i punti di filePart.data per ogni esecuzione del test. La linea blu mostra le latenze del metodo di base, in cui l'App 1 scrive serializzazioni capnp su un socket di dominio Unix usando ::write()e l'App 2 li legge con ::read(). La linea arancione rappresenta le latenze del codice che utilizza Flow-IPC, come discusso in precedenza.
Come contribuire
Per le richieste di funzionalità e le segnalazioni di difetti, consultare il database Issue sul sito GitHub di Flow-IPC. Depositare i problemi secondo le necessità.
Per contribuire a modifiche e nuove funzionalità, consultare la guida ai contributi. Siamo raggiungibili al forum di discussione Flow-IPC su GitHub.
Cosa c'è dopo?
Abbiamo cercato di fornire un esperimento realistico nell'esempio precedente, non saltando nulla di significativo nel codice mostrato. Abbiamo scelto deliberatamente uno scenario privo di asincronicità e callback. Di conseguenza, sorgeranno domande del tipo: "Come integro Flow-IPC nel mio ciclo di eventi?" o "Come gestisco la chiusura della sessione e del canale? Posso semplicemente aprire un semplice stream socket senza tutte queste cose di sessione?", ecc.
Tali domande sono affrontate nella documentazione completa. La documentazione include un riferimento generato dai commenti dell'API nel codice, un manuale guidato con una curva di apprendimento più dolce e istruzioni per l'installazione. Il README del repository principale indica tutte queste risorse. L'introduzione al manuale e la sinossi dell'API coprono l'ampiezza delle funzioni disponibili.
Risorse
- Annuncio del post sul blog
- Progetto Flow-IPC su GitHub
Per installare, leggere la documentazione, inoltrare richieste di modifica o contribuire. - Discussioni su Flow-IPC
Ottimo modo per raggiungere noi e il resto della comunità.


Commenti