






In questo articolo imparerete a scalare in modo proattivo i carichi di lavoro prima di un picco di traffico utilizzando KEDA e lo scaler cron.
Quando si progetta un cluster Kubernetes, potrebbe essere necessario rispondere a domande quali:
- Quanto tempo ci vuole per scalare il cluster?
- Quanto tempo devo aspettare prima che venga creato un nuovo Pod?
Ci sono quattro fattori significativi che influenzano il ridimensionamento:
- Tempo di reazione dell'Autoscaler Pod orizzontale;
- Tempo di reazione del Cluster Autoscaler;
- tempo di approvvigionamento dei nodi; e
- Tempo di creazione del pod.
Analizziamoli uno per uno.
Per impostazione predefinita, l'uso della CPU dei pod viene analizzato da kubelet ogni 10 secondi e ottenuto da kubelet da Metrics Server ogni 1 minuto.
Il Pod Autoscaler orizzontale controlla le metriche di CPU e memoria ogni 30 secondi.
Se le metriche superano la soglia, l'autoscaler aumenterà il numero di repliche e si fermerà per 3 minuti prima di intraprendere ulteriori azioni. Nel peggiore dei casi, possono passare fino a 3 minuti prima che i pod vengano aggiunti o eliminati, ma in media si dovrebbe aspettare 1 minuto prima che l'Horizontal Pod Autoscaler attivi il ridimensionamento.

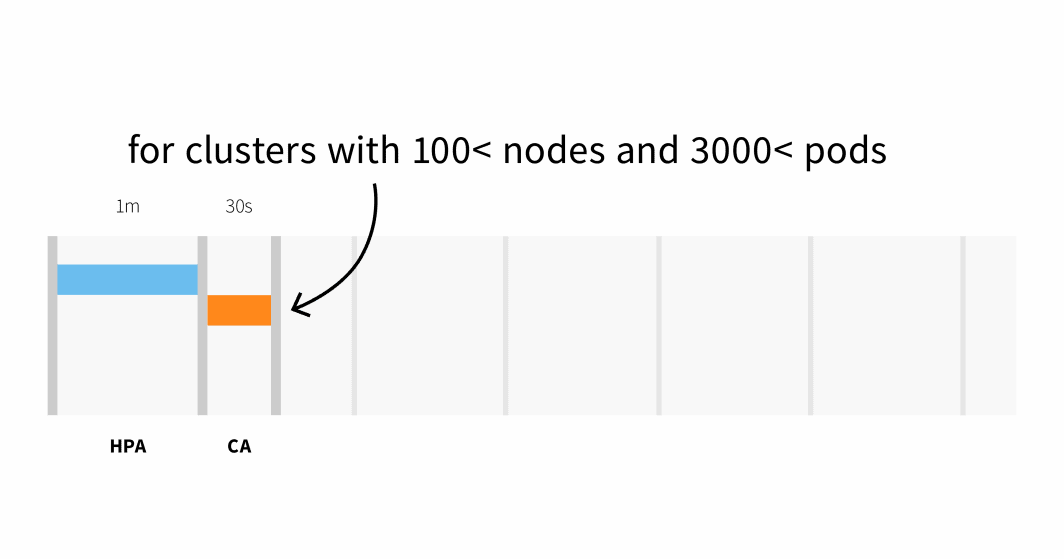
Il Cluster Autoscaler controlla se ci sono pod in attesa e aumenta le dimensioni del cluster. Il rilevamento della necessità di scalare il cluster potrebbe richiedere:
- Fino a 30 secondi su cluster con meno di 100 nodi e 3000 pod, con una latenza media di circa cinque secondi; oppure
- Latenza fino a 60 secondi su cluster con più di 100 nodi, con una latenza media di circa 15 secondi.
Il provisioning dei nodi su Linode richiede di solito 3-4 minuti da quando il Cluster Autoscaler attiva il processo di provisioning dei nodi. API a quando i pod possono essere pianificati sui nodi appena creati.
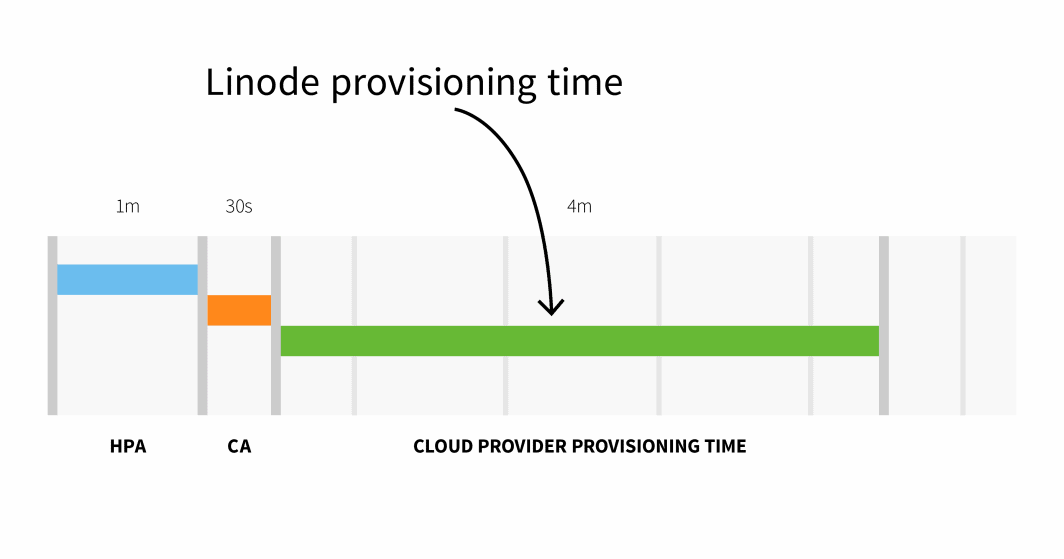
In sintesi, con un cluster di piccole dimensioni, si ha:
```
HPA delay: 1m +
CA delay: 0m30s +
Cloud provider: 4m +
Container runtime: 0m30s +
=========================
Total 6m
```
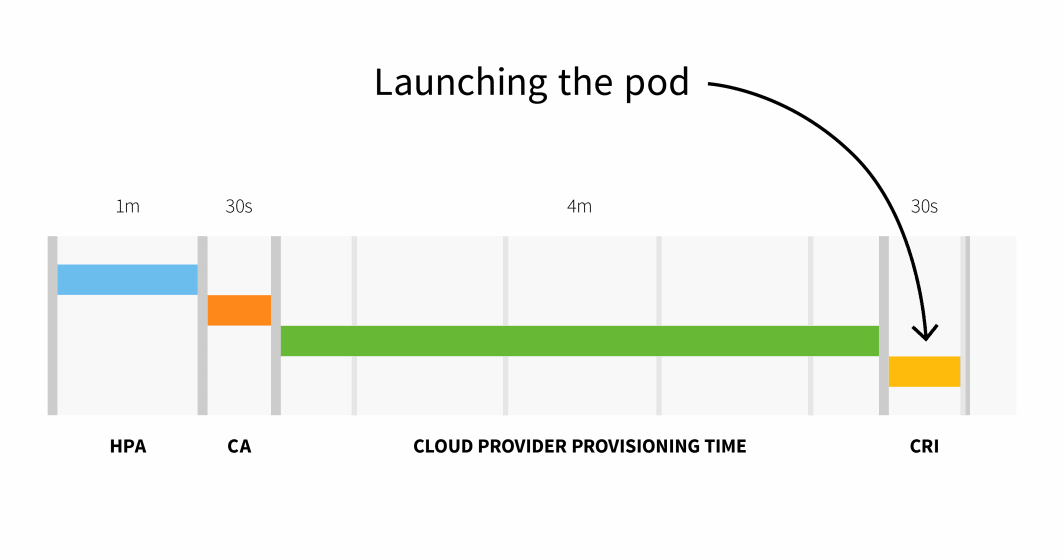
Con un cluster con più di 100 nodi, il ritardo totale potrebbe essere di 6 minuti e 30 secondi... è un tempo lungo, quindi come si può risolvere questo problema?
È possibile scalare i carichi di lavoro in modo proattivo o, se si conoscono bene i modelli di traffico, si può scalare in anticipo.
Scala preventiva con KEDA
Se il traffico viene servito con schemi prevedibili, ha senso scalare i carichi di lavoro (e i nodi) prima dei picchi e ridurli quando il traffico diminuisce.
Kubernetes non fornisce alcun meccanismo per scalare i carichi di lavoro in base a date o orari, quindi in questa parte si utilizzerà KEDA,il Kubernetes Event Driven Autoscaler.
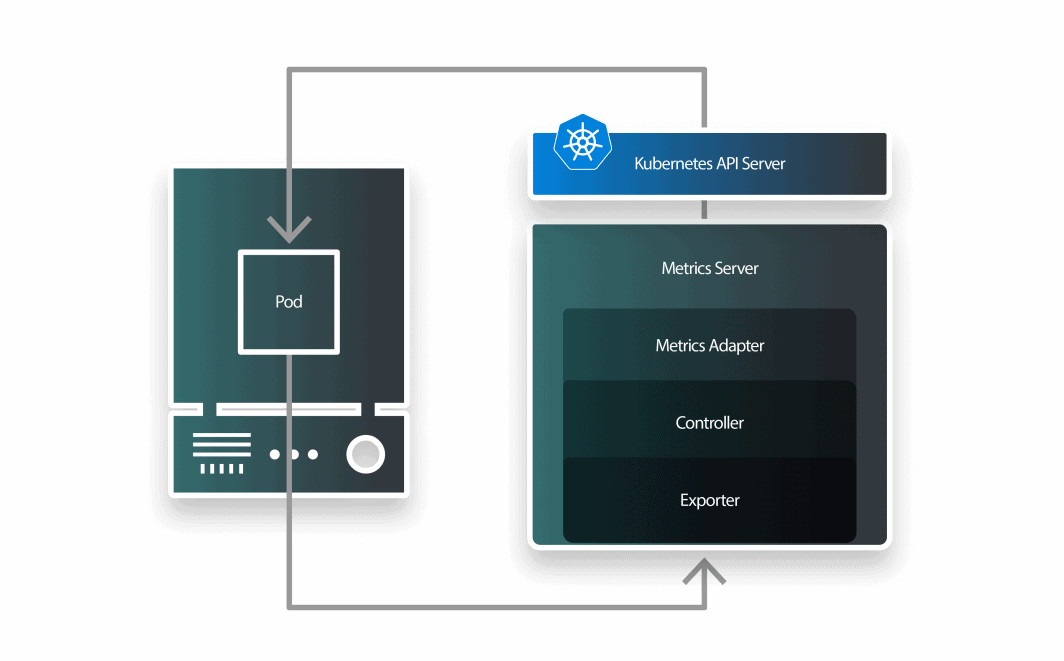
KEDA è un autoscaler composto da tre componenti:
- uno scaler;
- un adattatore di metriche; e
- un controllore.
È possibile installare KEDA con Helm:
```bash
$ helm repo add kedacore https://kedacore.github.io/charts
$ helm install keda kedacore/keda
```Ora che Prometheus e KEDA sono installati, creiamo un deployment.
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
name: podinfo
spec:
replicas: 1
selector:
matchLabels:
app: podinfo
template:
metadata:
labels:
app: podinfo
spec:
containers:
- name: podinfo
image: stefanprodan/podinfoÈ possibile inviare la risorsa al cluster con:
```bash
$ kubectl apply -f deployment.yaml
```KEDA lavora sopra il Pod Autoscaler orizzontale esistente e lo avvolge con una definizione di risorsa personalizzata chiamata ScaleObject.
Il seguente ScaledObject utilizza il Cron Scaler per definire una finestra temporale in cui modificare il numero di repliche:
```yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 1
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 23 * * * *
end: 28 * * * *
desiredReplicas: "5"
```È possibile inviare l'oggetto con:
```bash
$ kubectl apply -f scaled-object.yaml
```Cosa succederà dopo? Niente. L'autoscala si attiverà solo tra 23 * * * * e 28 * * * *. Con l'aiuto di Guru di Cronè possibile tradurre le due espressioni di cron in:
- Iniziare al minuto 23 (ad es. 2:23, 3:23, ecc.).
- Fermarsi al minuto 28 (ad es. 2:28, 3:28, ecc.).
Se si attende la data di inizio, si noterà che il numero di repliche aumenta a 5.
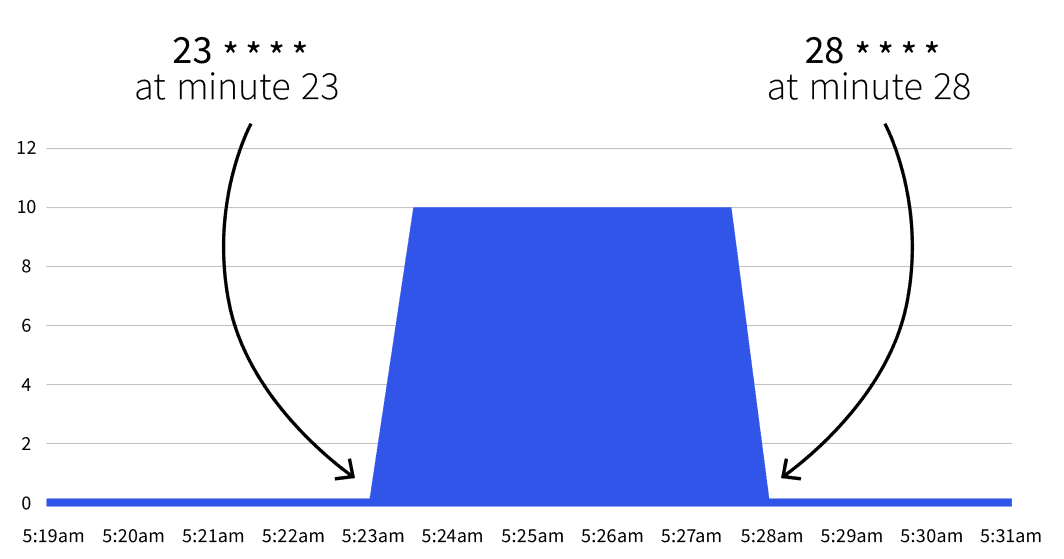
Il numero torna a 1 dopo il 28° minuto? Sì, l'autoscaler torna al conteggio delle repliche specificato in minReplicaCount.
Cosa succede se si incrementa il numero di repliche tra uno degli intervalli? Se, tra i minuti 23 e 28, si scala l'implementazione a 10 repliche, KEDA sovrascrive la modifica e imposta il conteggio. Se si ripete lo stesso esperimento dopo il 28° minuto, il conteggio delle repliche sarà impostato a 10. Ora che conoscete la teoria, analizziamo alcuni casi d'uso pratici.
Riduzione durante l'orario di lavoro
Avete un deployment in un ambiente di sviluppo che deve essere attivo durante le ore di lavoro e deve essere spento durante la notte.
Si può utilizzare il seguente oggetto scalare:
```yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 0
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 0 9 * * *
end: 0 17 * * *
desiredReplicas: "10"
```Il conteggio predefinito delle repliche è pari a zero, ma durante l'orario di lavoro (dalle 9.00 alle 17.00) le repliche vengono scalate a 10.
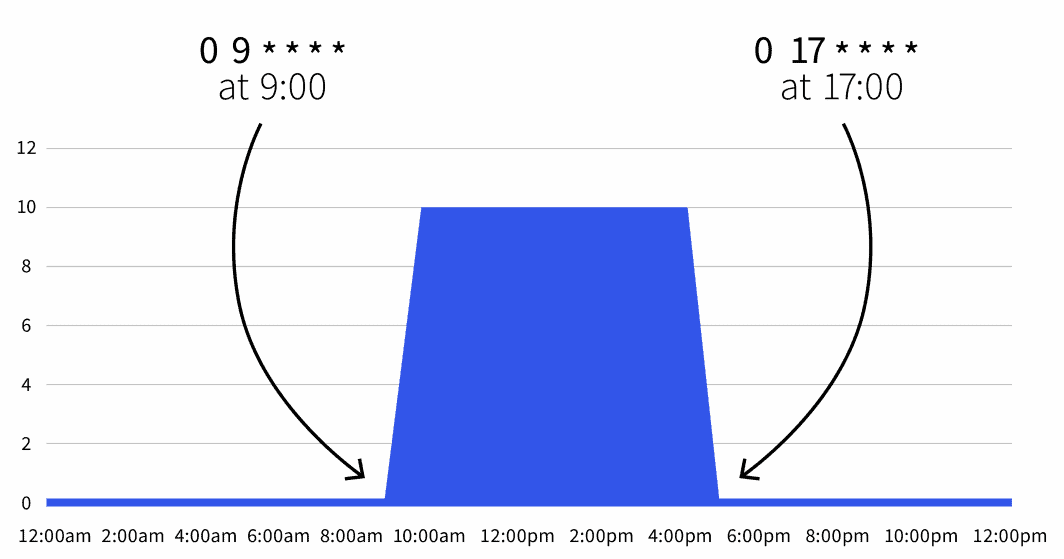
È anche possibile espandere l'oggetto scalare per escludere il fine settimana:
```yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 0
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 0 9 * * 1-5
end: 0 17 * * 1-5
desiredReplicas: "10"
```Ora il carico di lavoro è attivo solo dalle 9 alle 5 dal lunedì al venerdì. Poiché è possibile combinare diversi trigger, si possono includere anche delle eccezioni.
Riduzione della spesa durante i fine settimana
Ad esempio, se si prevede di mantenere attivi i carichi di lavoro più a lungo il mercoledì, si può utilizzare la seguente definizione:
```yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: cron-scaledobject
namespace: default
spec:
maxReplicaCount: 10
minReplicaCount: 0
scaleTargetRef:
name: podinfo
triggers:
- type: cron
metadata:
timezone: Europe/London
start: 0 9 * * 1-5
end: 0 17 * * 1-5
desiredReplicas: "10"
- type: cron
metadata:
timezone: Europe/London
start: 0 17 * * 3
end: 0 21 * * 3
desiredReplicas: "10"
```In questa definizione, il carico di lavoro è attivo tra le 9 e le 5 dal lunedì al venerdì, tranne il mercoledì, che va dalle 9 alle 21.
Sintesi
L'autoscaler KEDA cron consente di definire un intervallo di tempo in cui si desidera scalare i carichi di lavoro.
Ciò consente di scalare i pod prima dei picchi di traffico, attivando in anticipo il Cluster Autoscaler.
In questo articolo, avete imparato:
- Come funziona il Cluster Autoscaler.
- Quanto tempo occorre per scalare orizzontalmente e aggiungere nodi al cluster.
- Come scalare le applicazioni in base alle espressioni cron con KEDA.
Volete saperne di più? Registratevi per vederlo in azione durante il nostro webinar in collaborazione con i servizi di cloud computing di Akamai.





Commenti