
 (1)")
I modelli linguistici di grandi dimensioni (LLM) sono di gran moda, soprattutto grazie ai recenti sviluppi di OpenAI. Il fascino degli LLM deriva dalla loro capacità di comprendere, interpretare e generare il linguaggio umano in un modo che un tempo si pensava fosse di dominio esclusivo degli esseri umani. Strumenti come CoPilot si stanno rapidamente integrando nella vita quotidiana degli sviluppatori, mentre le applicazioni alimentate da ChatGPT stanno diventando sempre più mainstream.
La popolarità degli LLM deriva anche dalla loro accessibilità per lo sviluppatore medio. Con molti modelli open-source disponibili, ogni giorno compaiono nuove startup tecnologiche con una qualche soluzione a un problema basata su un LLM.
I dati sono stati definiti il "nuovo petrolio". Nell'apprendimento automatico, i dati sono la materia prima utilizzata per addestrare, testare e validare i modelli. Dati di alta qualità, diversificati e rappresentativi sono essenziali per creare LLM accurati, affidabili e robusti.
Costruire il proprio LLM può essere impegnativo, soprattutto quando si tratta di raccogliere e archiviare i dati. La gestione di grandi volumi di dati non strutturati, l'archiviazione e la gestione degli accessi sono solo alcune delle sfide che si possono affrontare. In questo post esploreremo queste sfide di gestione dei dati. In particolare, esamineremo:
- Come funzionano gli LLM e come scegliere tra i modelli esistenti
- I tipi di dati utilizzati nelle LLM
- Pipeline di dati e ingestione per LLM
Il nostro obiettivo è quello di fornirvi una chiara comprensione del ruolo critico che i dati svolgono nei LLM, dotandovi delle conoscenze necessarie per gestire efficacemente i dati nei vostri progetti di LLM.
Per iniziare, gettiamo una base di comprensione per gli LLM.
Come funzionano gli LLM e come scegliere tra i modelli esistenti
Ad alto livello, un LLM funziona convertendo le parole (o le frasi) in rappresentazioni numeriche chiamate embeddings. Questi embeddings catturano il significato semantico e le relazioni tra le parole, consentendo al modello di comprendere il linguaggio. Ad esempio, un LLM imparerebbe che le parole "cane" e "cucciolo" sono correlate e le collocherebbe più vicine nello spazio numerico, mentre la parola "albero" sarebbe più distante.

La parte più critica di un LLM è la rete neurale, che è un modello di calcolo ispirato al funzionamento del cervello umano. La rete neurale può apprendere queste incorporazioni e le loro relazioni dai dati su cui viene addestrata. Come per la maggior parte delle applicazioni di apprendimento automatico, i modelli LLM necessitano di grandi quantità di dati. In genere, maggiore è il numero di dati e la loro qualità per l'addestramento del modello, maggiore sarà la precisione del modello stesso, il che significa che è necessario un buon metodo di gestione dei dati per i LLM.
Considerazioni sulla valutazione dei modelli esistenti
Fortunatamente per gli sviluppatori, sono attualmente disponibili molte opzioni open-source per gli LLM, con diverse opzioni popolari che consentono l'uso commerciale, tra cui:
- Dolly (pubblicato da Databricks)
- Aprire LLaMA (metaproduzione)
- Molti, molti di più
Con un elenco così ampio tra cui scegliere, la selezione del giusto modello LLM open-source da utilizzare può essere complicata. È importante capire le risorse di calcolo e di memoria necessarie per un modello LLM. La dimensione del modello, ad esempio 3 miliardi di parametri di input contro 7 miliardi, influisce sulla quantità di risorse necessarie per eseguire ed esercitare il modello. Considerate questo aspetto rispetto alle vostre capacità. Ad esempio, diversi modelli DLite sono stati resi disponibili appositamente per essere eseguiti su computer portatili piuttosto che richiedere risorse cloud ad alto costo.
Durante la ricerca di ogni LLM, è importante notare come il modello è stato addestrato e a quale tipo di attività è generalmente orientato. Anche queste distinzioni influenzeranno la vostra scelta. Per pianificare il vostro lavoro di LLM dovrete passare al setaccio le opzioni di modelli open-source, capire dove ciascun modello si distingue meglio e prevedere le risorse che dovrete utilizzare per ciascun modello.
A seconda dell'applicazione o del contesto in cui è necessario un LLM, si può iniziare con un LLM esistente o scegliere di addestrare un LLM da zero. Con un LLM esistente, è possibile utilizzarlo così com'è, oppure perfezionare il modello con dati aggiuntivi rappresentativi del compito che si ha in mente.
La scelta dell'approccio migliore per le proprie esigenze richiede una forte comprensione dei dati utilizzati per l'addestramento dei LLM.
I tipi di dati utilizzati negli LLM
Quando si tratta di formare un LLM, i dati utilizzati sono tipicamente testuali. Tuttavia, la natura di questi dati testuali può variare notevolmente e la comprensione dei diversi tipi di dati che si possono incontrare è essenziale. In generale, i dati LLM possono essere classificati in due tipi: dati semi-strutturati e non strutturati. È improbabile che i dati strutturati, ovvero quelli rappresentati in forma tabellare, vengano utilizzati nei LLM.
Dati semi-strutturati
I dati semi-strutturati sono organizzati in modo predefinito e seguono un certo modello. Questa organizzazione consente una ricerca e un'interrogazione semplice dei dati. Nel contesto dei LLM, un esempio di dati semi-strutturati potrebbe essere un corpus di testi in cui ogni voce è associata a determinati tag o metadati. Esempi di dati semi-strutturati sono:
- Articoli di cronaca, ciascuno associato a una categoria (come sport, politica o tecnologia).
- Recensioni dei clienti, con ogni recensione associata a una valutazione e a informazioni sul prodotto.
- Post sui social media, con ogni post associato all'utente che lo ha pubblicato, all'ora di pubblicazione e ad altri metadati.
In questi casi, un LLM potrebbe imparare a prevedere la categoria in base all'articolo di cronaca, la valutazione in base al testo della recensione o il sentiment di un post sui social media in base al suo contenuto.
Dati non strutturati
I dati non strutturati, invece, non hanno un'organizzazione o un modello predefinito. Questi dati sono spesso ricchi di testo e possono contenere anche date, numeri e fatti, rendendo più complicata la loro elaborazione e analisi. Nel contesto dei LLM, i dati non strutturati sono molto comuni. Esempi di dati non strutturati sono:
- Libri, articoli e altri contenuti di lunga durata
- Trascrizioni tratte da interviste o podcast
- Pagine web o documenti
Senza etichette esplicite o tag organizzativi, i dati non strutturati sono più impegnativi per la formazione di LLM. Tuttavia, possono anche produrre modelli più generali. Ad esempio, un modello addestrato su un ampio corpus di libri potrebbe imparare a generare una prosa realistica, come nel caso di GPT-3.

Abbiamo visto che i dati sono al centro degli LLM, ma come fanno questi dati a passare dallo stato grezzo a un formato utilizzabile da un LLM? Spostiamo l'attenzione sui processi chiave coinvolti.
Pipeline di dati e ingestione per i LLM
Gli elementi costitutivi dell'acquisizione e dell'elaborazione dei dati per un LLM risiedono nei concetti di pipeline di dati e di ingestione dei dati.
Che cos'è una pipeline di dati?
Le pipeline di dati costituiscono il passaggio tra i dati grezzi e non strutturati e un LLM completamente addestrato. Esse assicurano che i dati siano raccolti, elaborati e preparati in modo appropriato, rendendoli pronti per le fasi di formazione e convalida del processo di creazione del LLM.
Una pipeline di dati è un insieme di processi che sposta i dati dalla loro origine a una destinazione dove possono essere archiviati e analizzati. In genere, si tratta di:
- Estrazione dei dati: I dati vengono estratti dalla loro fonte, che può essere un database, un data warehouse o persino un'API esterna.
- Trasformazione dei dati: I dati grezzi devono essere puliti e trasformati in un formato adatto all'analisi. La trasformazione comprende la gestione dei valori mancanti, la correzione dei dati incoerenti, la conversione dei tipi di dati o la codifica di variabili categoriali.
- Caricamento dei dati: I dati trasformati vengono caricati in un sistema di archiviazione, come un database o un data warehouse. Questi dati sono quindi prontamente disponibili per essere utilizzati in un modello di apprendimento automatico.
Quando parliamo di ingestione dei dati, ci riferiamo al front-end di questi processi di pipeline, che si occupa dell'acquisizione dei dati e della loro preparazione per l'uso.
Che aspetto ha una pipeline di dati nel contesto di un LLM?
Sebbene una pipeline di dati per un LLM possa sovrapporsi in generale alla maggior parte delle pipeline utilizzate dai team di dati, gli LLM introducono alcune sfide uniche nella gestione dei dati per gli LLM. Ad esempio:
- Estrazione dei dati: L'estrazione dei dati per un LLM è spesso più complessa, variegata e pesante dal punto di vista informatico. Poiché le fonti di dati possono essere siti web, libri, trascrizioni o social media, ogni fonte ha le sue sfumature e richiede un approccio unico.
- Trasformazione dei dati: Con una gamma così ampia di fonti di dati LLM, ogni fase di trasformazione per ogni tipo di dati sarà diversa, richiedendo una logica unica per elaborare i dati in un formato più standard che un LLM possa utilizzare per la formazione.
- Caricamento dei dati: In molti casi, la fase finale del caricamento dei dati può richiedere tecnologie di archiviazione dei dati fuori dalla norma. I dati testuali non strutturati possono richiedere l'uso di database NoSQL, in contrasto con i data store relazionali utilizzati da molte pipeline di dati.
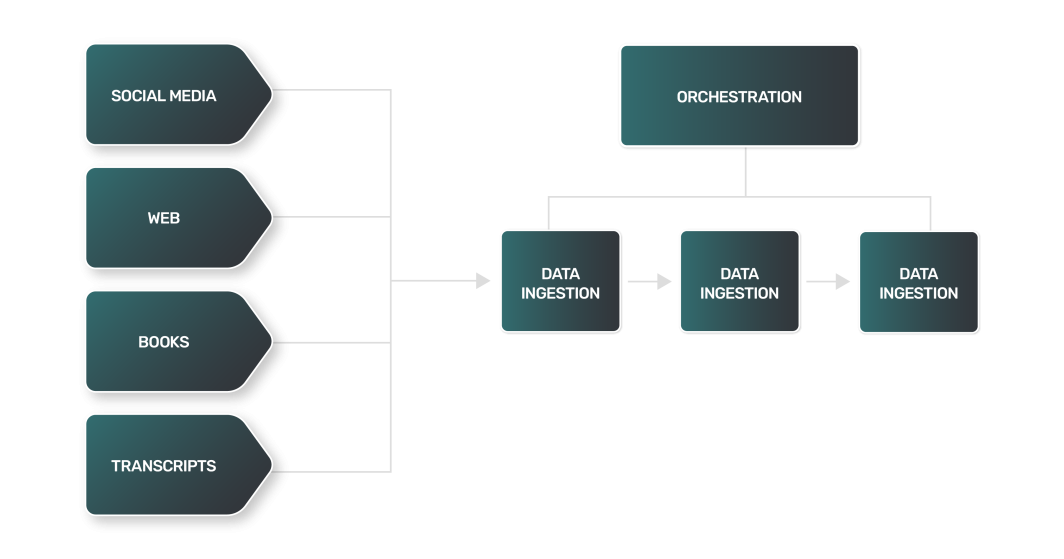
Il processo di trasformazione dei dati per i LLM include tecniche simili a quelle che si trovano nell'elaborazione del linguaggio naturale (NLP):
- Tokenizzazione: Scomposizione del testo in singole parole o "token".
- Rimozione delle parole chiuse: Eliminazione di parole di uso comune come "e", "il" e "è". Tuttavia, a seconda del compito per il quale il LLM è stato addestrato, le stop words possono essere mantenute per preservare importanti informazioni sintattiche e semantiche.
- Lemmatizzazione: Ridurre le parole alla loro forma base o radice.
Come si può immaginare, la combinazione di tutti questi passaggi per ingerire quantità massicce di dati da un'ampia gamma di fonti può dare origine a una pipeline di dati incredibilmente complicata e di grandi dimensioni. Per aiutarvi nel vostro compito, avrete bisogno di buoni strumenti e risorse.
Strumenti comuni utilizzati per l'ingestione dei dati
Diversi strumenti estremamente diffusi nell'ambito dell'ingegneria dei dati possono aiutarvi a gestire i complessi processi di ingestione dei dati che fanno parte della vostra pipeline di dati. Se state costruendo il vostro LLM, la maggior parte del vostro tempo di sviluppo sarà dedicato alla raccolta, alla pulizia e all'archiviazione dei dati utilizzati per l'addestramento. Gli strumenti che aiutano a gestire i dati per gli LLM possono essere classificati come segue:
- Orchestrazione della pipeline: Piattaforme per monitorare e gestire i processi della pipeline di dati.
- Calcolo: Risorse per elaborare i dati su scala.
- Archiviazione: Database per archiviare la grande quantità di dati necessari per una formazione LLM efficace.
Analizziamo ciascuno di essi in modo più dettagliato.
Orchestrazione della pipeline
Apache Airflow è una popolare piattaforma open-source per la creazione, la programmazione e il monitoraggio programmatico di flussi di lavoro di dati. Consente di creare pipeline di dati complesse grazie all'interfaccia di codifica basata su Python, versatile e facile da usare. I task in Airflow sono organizzati in grafi aciclici diretti (DAG), dove ogni nodo rappresenta un task e gli spigoli rappresentano le dipendenze tra i task.
Airflow è ampiamente utilizzato per le operazioni di estrazione, trasformazione e caricamento dei dati, il che lo rende uno strumento prezioso nel processo di ingestione dei dati. Marketplace di Linode offre Apache Airflow per una facile configurazione e utilizzo.
Elaborazione
Oltre alla gestione della pipeline con strumenti come Airflow, avrete bisogno di risorse di calcolo adeguate che possano funzionare in modo affidabile su scala. Quando si ingeriscono grandi quantità di dati testuali e si esegue l'elaborazione a valle da molte fonti, è necessario disporre di risorse di calcolo in grado di scalare, possibilmente in modo orizzontale, in base alle necessità.
Una scelta popolare per l'elaborazione scalabile è Kubernetes. Kubernetes offre flessibilità e si integra bene con molti strumenti, tra cui Airflow. Sfruttando Kubernetes gestito, è possibile attivare risorse di calcolo flessibili in modo rapido e semplice.
Archiviazione
Un database è parte integrante del processo di ingestione dei dati e funge da destinazione principale per i dati ingeriti dopo che sono stati puliti e trasformati. È possibile utilizzare diversi tipi di database. La scelta del tipo dipende dalla natura dei dati e dai requisiti specifici del caso d'uso:
- I database relazionali utilizzano una struttura tabellare per memorizzare e rappresentare i dati. Sono una buona scelta per i dati che hanno relazioni chiare e dove l'integrità dei dati è fondamentale. Anche se il vostro LLM dipenderà da dati non strutturati, un database relazionale come PostgreSQL può funzionare anche con tipi di dati non strutturati.
- Database NoSQL: I database NoSQL includono database orientati ai documenti, che non utilizzano una struttura tabellare per memorizzare i dati. Sono una buona scelta per gestire grandi volumi di dati non strutturati, offrendo prestazioni elevate, alta disponibilità e facile scalabilità.
In alternativa ai database per l'archiviazione dei dati LLM, alcuni ingegneri preferiscono utilizzare file system distribuiti. Ne sono un esempio AWS S3 o Hadoop. Sebbene un file system distribuito possa essere una buona opzione per archiviare grandi quantità di dati non strutturati, richiede uno sforzo aggiuntivo per organizzare e gestire i grandi insiemi di dati.
Per quanto riguarda le opzioni di archiviazione, su Marketplace sono disponibili PostgreSQL e MySQL gestiti. Entrambe le opzioni sono facili da configurare e da inserire nella pipeline di dati LLM.
Mentre per gli LLM più piccoli è possibile addestrarsi con meno dati e cavarsela con database più piccoli (come un singolo nodo PostgreSQL), i casi d'uso più pesanti lavoreranno con quantità di dati molto elevate. In questi casi, probabilmente avrete bisogno di qualcosa come un cluster PostgreSQL per supportare il volume di dati con cui lavorerete, gestire i dati per gli LLM e fornire tali dati in modo affidabile.
Quando si sceglie un database per la gestione dei dati per i corsi di laurea magistrale, occorre considerare la natura dei dati e i requisiti del caso. Il tipo di dati ingeriti determinerà il tipo di database più adatto alle vostre esigenze. Anche i requisiti del caso d'uso, come le prestazioni, la disponibilità e la scalabilità, saranno considerazioni importanti.
L'ingestione dei dati in modo efficace e accurato è fondamentale per il successo di un LLM. Con l'uso appropriato degli strumenti, potete costruire processi di ingestione dei dati affidabili ed efficienti per la vostra pipeline, gestendo grandi quantità di dati e assicurando che il vostro LLM abbia ciò di cui ha bisogno per imparare e fornire risultati accurati.
Per concludere
L'aumento vertiginoso della popolarità degli LLM ha aperto nuove porte nello spazio tecnologico. La tecnologia è facilmente accessibile agli sviluppatori, ma la loro capacità di gestire i dati per gli LLM e di sfruttare i dati per addestrare nuovi LLM o perfezionare quelli esistenti determinerà il loro successo a lungo termine.
Se state iniziando a lavorare a un progetto di LLM, dovete capire le basi prima di buttarvi nella mischia. Per essere efficace, un LLM richiede l'ingestione di un grande volume di dati non strutturati, un processo che comprende l'estrazione dalle fonti, la preelaborazione, la trasformazione e l'importazione. L'esecuzione di questi compiti richiede strumenti come Airflow e Kubernetes per l'orchestrazione delle pipeline e risorse informatiche scalabili. Inoltre, la natura non strutturata dei dati comunemente utilizzati per la formazione LLM richiede un'opzione di archiviazione dei dati come PostgreSQL, che può essere utilizzata in modo affidabile su scala attraverso i cluster.




Commenti (1)
Artigo muito bom para quem quer se aprofundar em LLM! Parabéns!