

A seconda di chi lo chieda, il boom dell'AI significa che accedere a potenti GPU nel cloud è un gioco da ragazzi, oppure è quasi impossibile. Il problema è trovare il giusto GPU sul giusto provider senza pagare troppo per risorse hardware di cui non si ha realisticamente bisogno, e che saranno disponibili solo quando se ne ha bisogno, senza doversi impegnare in prenotazioni prepagate o in contratti troppo onerosi.
Si tratta di un ordine elevato e siamo stati lieti di accettare la sfida. Dopo test e ottimizzazioni rigorose, le nuove GPU di Akamai sono ora disponibili per tutti i clienti. Alimentate dalle schede RTX 4000 Ada Generation di NVIDIA , queste GPU sono ottimizzate per i casi d'uso dei media, ma sono adatte a una vasta gamma di carichi di lavoro e applicazioni. I piani RTX 4000 Ada Generation partono da 0,52 dollari l'ora per 1 GPU, 4 CPU e 16 GB di RAM in sei regioni di calcolo core:
- Chicago, IL
- Seattle, WA
- Francoforte, DE Espansione
- Parigi, FR
- Osaka, JP
- Singapore, espansione SG
- Espansione di Mumbai, IN (in arrivo!)
Caso d'uso in evidenza
Attraverso il nostro programma beta, i nostri clienti e i partner ISV (Independent Software Vendor) hanno potuto mettere alla prova le nostre nuove GPU, anche per casi d'uso chiave che sapevamo avrebbero beneficiato delle specifiche del piano GPU che abbiamo progettato: transcodifica dei media e AI leggera.
Cambria Stream, il codificatore cloud-hosted di Capella Systems, gestisce la codifica live, l'inserimento degli annunci, la crittografia e il packaging per gli eventi live più impegnativi. È necessaria la giusta tecnologia e la configurazione dietro le quinte per consentire agli utenti finali di guardare gli eventi in diretta streaming da tutti i dispositivi diversi e attraverso le infrastrutture di rete.
"Utilizzando il nuovo NVIDIA RTX 4000 Ada Generation Dual GPU di Akamai, un singolo Cambria Stream può elaborare fino a 25 canali di codifica multistrato contemporaneamente, riducendo in modo significativo il costo totale di elaborazione rispetto alla codifica basata su CPU."
Leggi il comunicato stampa completo.
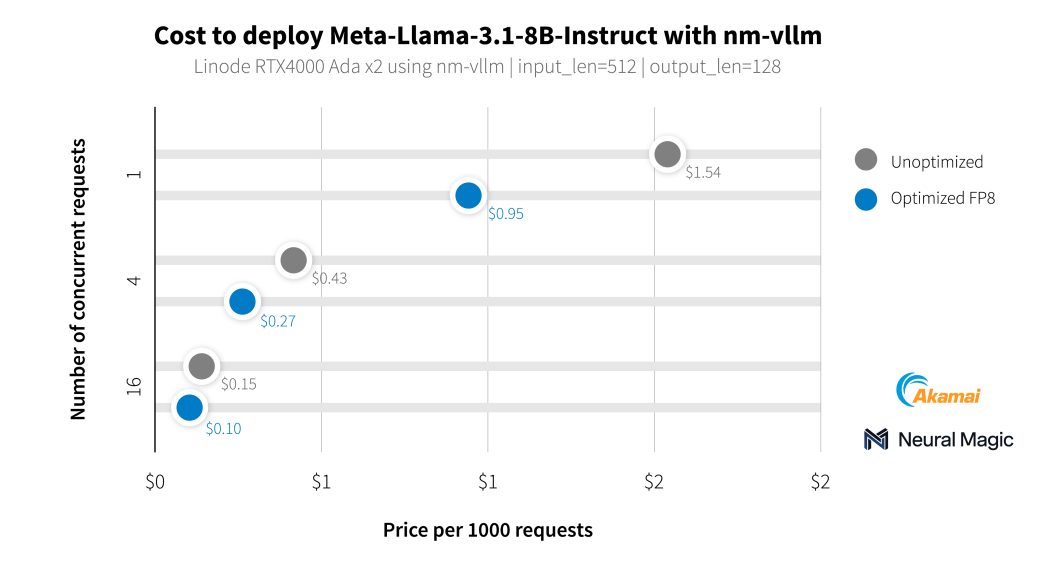
Oltre ai nostri clienti del settore dei media, abbiamo collaborato con Neural Magic per effettuare un benchmark delle capacità di intelligenza artificiale delle nostre nuove GPU utilizzando nm-vllm, il loro motore di serving LLM pronto per le aziende. Hanno utilizzato il loro toolkit di compressione open source per LLM, LLM Compressor, per produrre implementazioni molto più efficienti con una conservazione della precisione del 99,9%. Durante il test degli ultimi modelli Llama 3.1, Neural Magic ha utilizzato le proprie ottimizzazioni software per ottenere un costo medio di 0,27 dollari per 1.000 richieste di riepilogo utilizzando le GPU RTX 4000, con una riduzione dei costi del 60% rispetto all'implementazione di riferimento.
Inizia
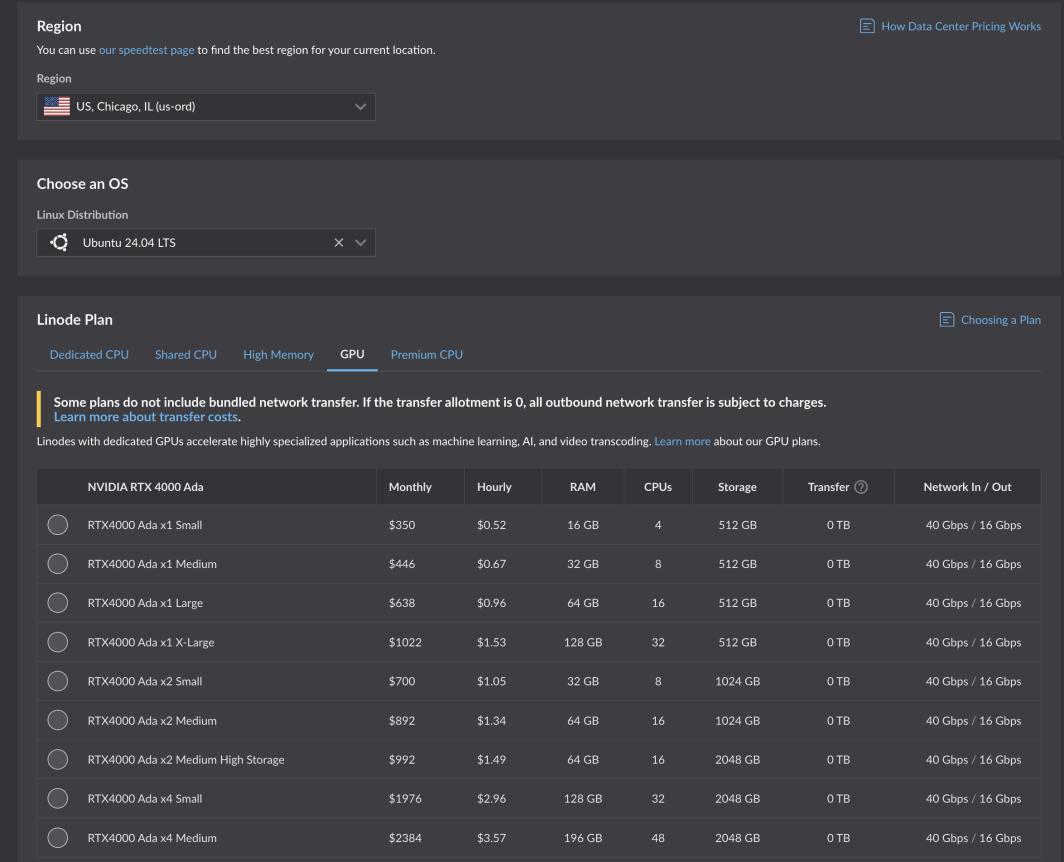
Se avete già un account, potete iniziare subito. È sufficiente selezionare una regione supportata e accedere alla scheda GPU nella tabella dei piani delle istanze di calcolo.
Iniziate con la nostra documentazione.
Gli sviluppatori che costruiscono e gestiscono applicazioni aziendali sono invitati a contattare i nostri team di consulenti cloud.
Nota: L'uso delle istanze Akamai GPU richiede uno storico di fatturazione positivo sul proprio account, esclusi i codici promozionali. Se non si riesce a distribuire e si richiede l'accesso a GPU , aprire un ticket di assistenza.





Commenti