

Selon les personnes interrogées, le boom de l'IA signifie que l'accès à des GPU puissants dans le cloud est un jeu d'enfant - ou qu'il est presque impossible. Le problème est de trouver le bon siteGPU chez le bon fournisseur sans surpayer des ressources matérielles dont vous n'avez pas réellement besoin et qui seront disponibles uniquement lorsque vous en aurez besoin, sans avoir à vous engager dans des réservations prépayées ou des contrats importants.
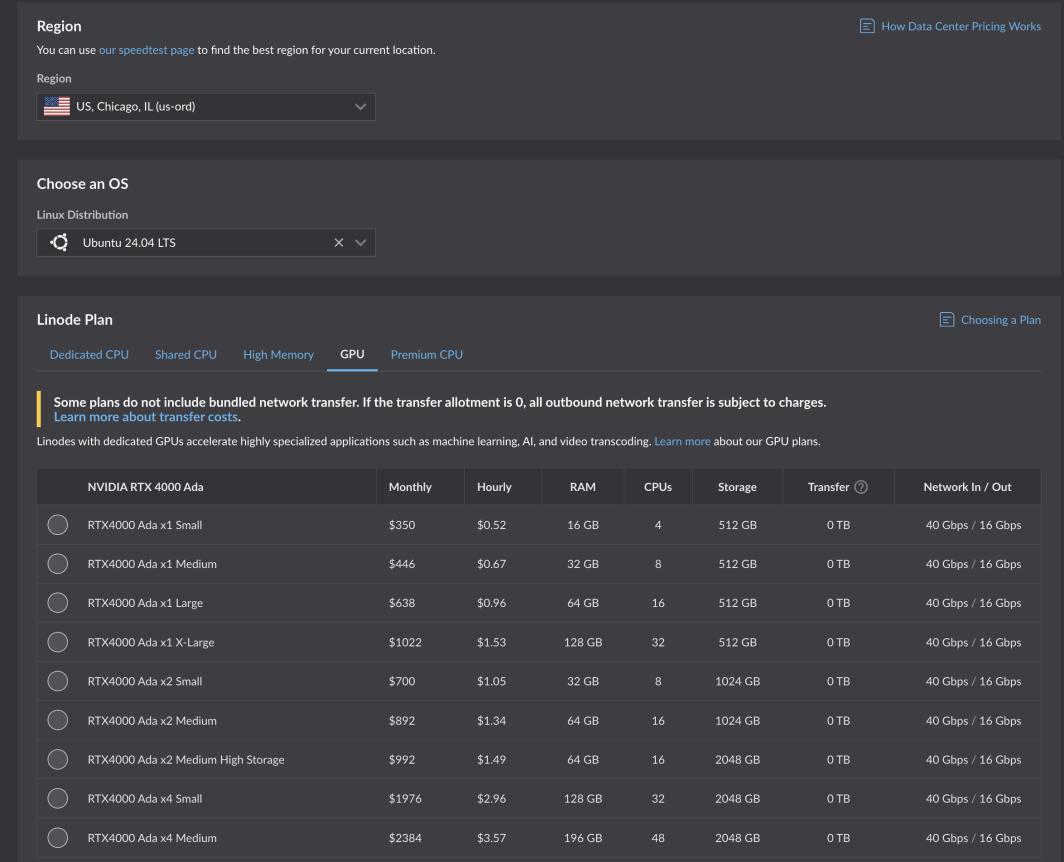
C'est un défi de taille, et nous avons été heureux de l'accepter". Après des tests et une optimisation rigoureux, les nouveaux GPU d'Akamai sont désormais disponibles pour tous les clients. Alimentés par les cartes RTX 4000 Ada Generation de NVIDIA , ces GPU sont optimisés pour les cas d'utilisation des médias, mais sont adaptés à une gamme de charges de travail et d'applications. Les plans RTX 4000 Ada Generation commencent à 0,52 $ par heure pour 1 GPU, 4 CPU et 16 Go de RAM dans six régions de calcul :
- Chicago, IL
- Seattle, WA
- Francfort, DE Expansion
- Paris, FR
- Osaka, JP
- Singapour, SG Expansion
- Mumbai, IN Expansion (bientôt disponible !)
Principaux cas d'utilisation
Grâce à notre programme bêta, nos clients et nos partenaires éditeurs de logiciels indépendants (ISV) ont pu tester nos nouveaux GPU, notamment pour des cas d'utilisation clés dont nous savions qu'ils bénéficieraient des spécifications du plan GPU que nous avons conçu : le transcodage des médias et l'intelligence artificielle légère.
Cambria Stream, l'encodeur hébergé dans le nuage de Capella Systems, gère l'encodage en direct, l'insertion de publicités, le cryptage et le conditionnement des événements en direct les plus exigeants. Il faut une technologie et une configuration adéquates en coulisses pour que les utilisateurs finaux puissent regarder des événements diffusés en direct à partir de tous les appareils différents et à travers les infrastructures de réseau.
"En utilisant le nouveau NVIDIA RTX 4000 Ada Generation Dual GPU d'Akamai, un seul Cambria Stream peut traiter jusqu'à 25 canaux d'encodage multicouche en même temps, ce qui réduit considérablement le coût total de calcul par rapport à l'encodage basé sur le CPU ".
Lire le communiqué de presse complet.
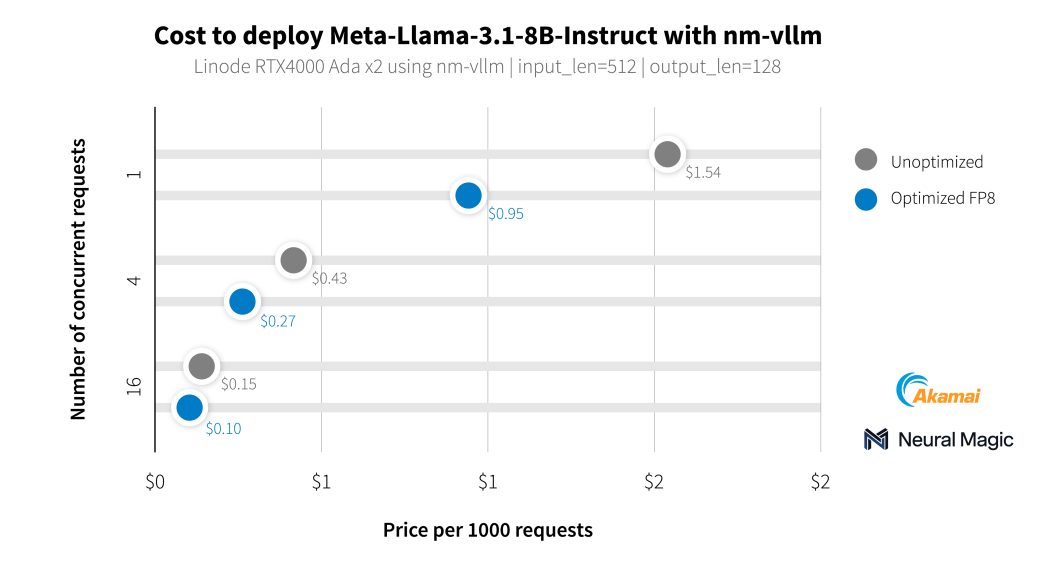
Outre nos clients du secteur des médias, nous avons travaillé avec Neural Magic pour évaluer les capacités d'IA de nos nouveaux GPU à l'aide de nm-vllm, leur moteur de service LLM prêt à l'emploi. Ils ont utilisé leur boîte à outils de compression open source pour les LLM, LLM Compressor, pour produire des déploiements beaucoup plus efficaces avec une préservation de la précision de 99,9 %. En testant les derniers modèles Llama 3.1, Neural Magic a utilisé ses optimisations logicielles pour atteindre un coût moyen de 0,27 $ pour 1 000 requêtes de résumé en utilisant des GPU RTX 4000, soit une réduction de 60 % du coût par rapport au déploiement de référence.
Commencer
Si vous avez déjà un compte, vous pouvez commencer tout de suite. Il vous suffit de sélectionner une région prise en charge et de vous rendre sur l'onglet GPU du tableau de planification des instances de calcul.
Commencez par consulter notre documentation.
Les développeurs qui créent et gèrent des applications professionnelles sont encouragés à contacter nos équipes de consultants en informatique dématérialisée.
Remarque : l'utilisation des instances Akamai GPU nécessite un historique de facturation positif sur votre compte, hors codes promotionnels. Si vous ne parvenez pas à déployer et avez besoin d'un accès à GPU , ouvrez un ticket d'assistance.





Commentaires