






Recientemente hemos publicado Flow-IPC, un conjunto de herramientas de comunicación entre procesos en C++, como código abierto bajo las licencias Apache 2.0 y MIT. Flow-IPC será útil para proyectos en C++ que transmitan datos entre procesos de aplicación y necesiten alcanzar una latencia cercana a cero sin renunciar a un código sencillo y reutilizable.
En el anuncio, demostramos que Flow-IPC puede transmitir cargas útiles de estructuras de datos de hasta 1 GB con la misma rapidez que una carga útil de 100 K, y en menos de 100 microsegundos. Con el IPC clásico, la latencia depende del tamaño de la carga útil y puede alcanzar el rango de 1 segundo. Por tanto, la mejora puede ser de hasta tres o cuatro órdenes de magnitud.
En este post, mostramos el código fuente que produjo esos números. Nuestro ejemplo, que se centra en la integración de Cap'n Proto, muestra que Flow-IPC es rápido y fácil de usar. (Tenga en cuenta que la API de Flow-IPC es completa en el sentido de que admite la transmisión de varios tipos de cargas útiles, pero la transmisión de cargas útiles basada en Cap'n Proto es una característica específica). Cap'n Proto es un proyecto de código abierto no afiliado a Akamai cuyo uso está sujeto a la licencia, a fecha de publicación de este blog, que se encuentra aquí.
¿Qué incluye?
Flow-IPC es una biblioteca con una API C++17 extensible. Es alojado en GitHub junto con documentación completa, pruebas automatizadas y demos, y una canalización CI. El ejemplo que exploramos a continuación es el perf_demo aplicación de prueba. Flow-IPC actualmente soporta Linux corriendo en x86-64. Tenemos planes para ampliarlo a macOS y ARM64, seguido de Windows y otras variantes del sistema operativo en función de la demanda. Estás bienvenido a contribuir y puerto.
La API de Flow-IPC sigue el espíritu de la biblioteca estándar de C++ y Boost, centrándose en la integración de varios conceptos y sus implementaciones de forma modular. Está diseñada para ser extensible. Nuestro CI pipeline prueba a través de una gama de versiones de compiladores GCC y Clang y configuraciones de compilación, incluyendo el endurecimiento a través de sanitizadores en tiempo de ejecución: ASAN (endurecimiento contra el uso indebido de la memoria), TSAN (contra condiciones de carrera) y UBSAN (contra comportamientos indefinidos diversos).
En este momento, Flow-IPC es para comunicación local: cruza los límites del proceso pero no los de la máquina. Sin embargo, su diseño es extensible, por lo que su ampliación a IPC en red es un paso natural. Creemos que el uso de Acceso Remoto Directo a Memoria (RDMA ) ofrece una interesante posibilidad para obtener un rendimiento ultrarrápido en LAN.
¿Quién debe utilizarlo?
Flow-IPC es un conjunto de herramientas pragmáticas de comunicación entre procesos. Al diseñarlo, lo hicimos desde la perspectiva del desarrollador de sistemas C++ moderno, adaptándolo específicamente a las tareas IPC a las que uno se enfrenta repetidamente, particularmente en el desarrollo de aplicaciones de servidor. Muchos de nosotros hemos tenido que montar un Unix-dominio-socket, named-pipe, o un protocolo local basado en HTTP para transmitir algo de un proceso a otro. A veces, para evitar las copias que implican estas soluciones, se recurre a la memoria compartida (SHM), una técnica muy delicada y difícil de reutilizar. Flow-IPC puede ayudar a cualquier desarrollador C++ que se enfrente a este tipo de tareas, desde las más comunes hasta las más avanzadas.
Destacan:
- Integración de Cap'n Proto: Las herramientas para la serialización in situ basada en esquemas como Cap'n Proto, que es la mejor de su clase, son muy útiles para el trabajo entre procesos. Sin embargo, sin Flow-IPC, todavía tendría que copiar los bits en un socket o tubería, etc., y luego copiarlos de nuevo en la recepción. Flow-IPC proporciona una transmisión de extremo a extremo sin copia de estructuras codificadas Cap'n Proto utilizando memoria compartida.
- Soporte Socket/FD: Cualquier mensaje transmitido a través de Flow-IPC puede incluir un manejador de E/S nativo (también conocido como descriptor de fichero o FD). Por ejemplo, en una arquitectura de servidor web, podría dividir el servidor en dos procesos: un proceso para gestionar los puntos finales y un proceso para procesar las solicitudes. Después de que el proceso de punto final complete la negociación TLS, puede pasar el manejador de socket TCP conectado directamente al proceso de procesamiento de peticiones.
- Soporte nativo de estructuras C++: Muchos algoritmos requieren trabajar directamente en C++
structLa mayoría de las veces se trata de múltiples niveles de contenedores STL y/o punteros. Dos subprocesos que colaboran en una estructura de este tipo son comunes y fáciles de codificar, mientras que dos subprocesos que colaboran en una estructura de procesa hacerlo a través de memoria compartida es bastante difícil, incluso con herramientas como Boost.interproceso. Flow-IPC simplifica esta tarea permitiendo compartir estructuras compatibles con STL, como contenedores, punteros y datos simples. - jemalloc más SHM: Una línea de código permite asignar cualquier dato necesario en la memoria compartida, ya sea para operaciones entre bastidores como la transmisión de Cap'n Proto o directamente para datos nativos de C++. Estas tareas pueden delegarse a jemalloc, el motor de heap detrás de FreeBSD y Meta. Esta característica puede ser particularmente valiosa para proyectos que requieren una asignación intensiva de memoria compartida, similar a la asignación regular de heap.
- Sin problemas de nombres ni de limpieza: Con Flow-IPC, no necesitas nombrar servidores-sockets, segmentos SHM, o tuberías, o preocuparte por la RAM persistente filtrada. En su lugar, establece una sesión Flow-IPC entre procesos: este es tu contexto IPC. Desde este único objeto de sesión, los canales de comunicación pueden ser abiertos a voluntad, sin nombres adicionales. Para tareas que requieren acceso directo a memoria compartida (SHM), se dispone de una arena SHM dedicada. Flow-IPC realiza una limpieza automática, incluso en el caso de una salida anormal, y evita conflictos entre nombres de recursos.
- Uso para RPC: Flow-IPC está diseñado para complementar, no para competir con frameworks de comunicación de más alto nivel como gRPC y Cap'n Proto RPC. No hay necesidad de elegir entre ellos y Flow-IPC. De hecho, el uso de las características de copia cero de Flow-IPC generalmente puede mejorar el rendimiento de estos protocolos.
Ejemplo: Envío de un archivo de varias partes
Aunque Flow-IPC puede transmitir datos de varios tipos, hemos decidido centrarnos en una estructura de datos descrita por un esquema Cap'n Proto (capnp). Este ejemplo será particularmente claro para aquellos familiarizados con capnp y Protocol Buffers, pero daremos mucho contexto para aquellos que estén menos familiarizados con estas herramientas.
En este ejemplo, hay dos aplicaciones que participan en un escenario de solicitud-respuesta.
- App 1 (servidor): Se trata de un servidor de memoria caché que ha precargado en la RAM archivos de entre 100kb y 1GB. Está preparado para gestionar las solicitudes de archivos almacenados en caché y emitir respuestas.
- Aplicación 2 (cliente): Este cliente solicita un archivo de un tamaño determinado. La aplicación 1 (servidor) envía los datos del archivo en un único mensaje dividido en una serie de trozos. Cada trozo incluye los datos junto con su hash.
# Cap'n Proto schema (.capnp file, generates .h and .c++ source code
# using capnp compiler tool):
$Cxx.namespace("cache_demo::schema");
struct Body
{
union
{
getCacheReq @0 :GetCacheReq;
getCacheRsp @1 :GetCacheRsp;
}
}
struct GetCacheReq
{
fileName @0 :Text;
}
struct GetCacheRsp
{
# We simulate the server returning file multiple parts,
# each (~equally) sized at its discretion.
struct FilePart
{
data @0 :Data;
dataSizeToVerify @1 :UInt64;
# Recipient can verify that `data` blob's size is indeed this.
dataHashToVerify @2 :Hash;
# Recipient can hash `data` and verify it is indeed this.
}
fileParts @0 :List(FilePart);
}Nuestro objetivo en este experimento es emitir una petición de un fichero de tamaño N, recibir la respuesta, medir el tiempo que ha tardado en procesarse y comprobar la integridad de una parte del fichero. Esta interacción tiene lugar a través de un canal de comunicación.
Para ello, primero tenemos que establecer este canal. Mientras que Flow-IPC te permite establecer manualmente un canal desde sus partes constituyentes de bajo nivel (socket local, cola de mensajes POSIX, y más), es mucho más fácil usar sesiones Flow-IPC en su lugar. Una sesión es simplemente el contexto de comunicación entre dos procesos vivos. Una vez establecidos, los canales están fácilmente disponibles.
A vista de pájaro, así es como funciona el proceso.
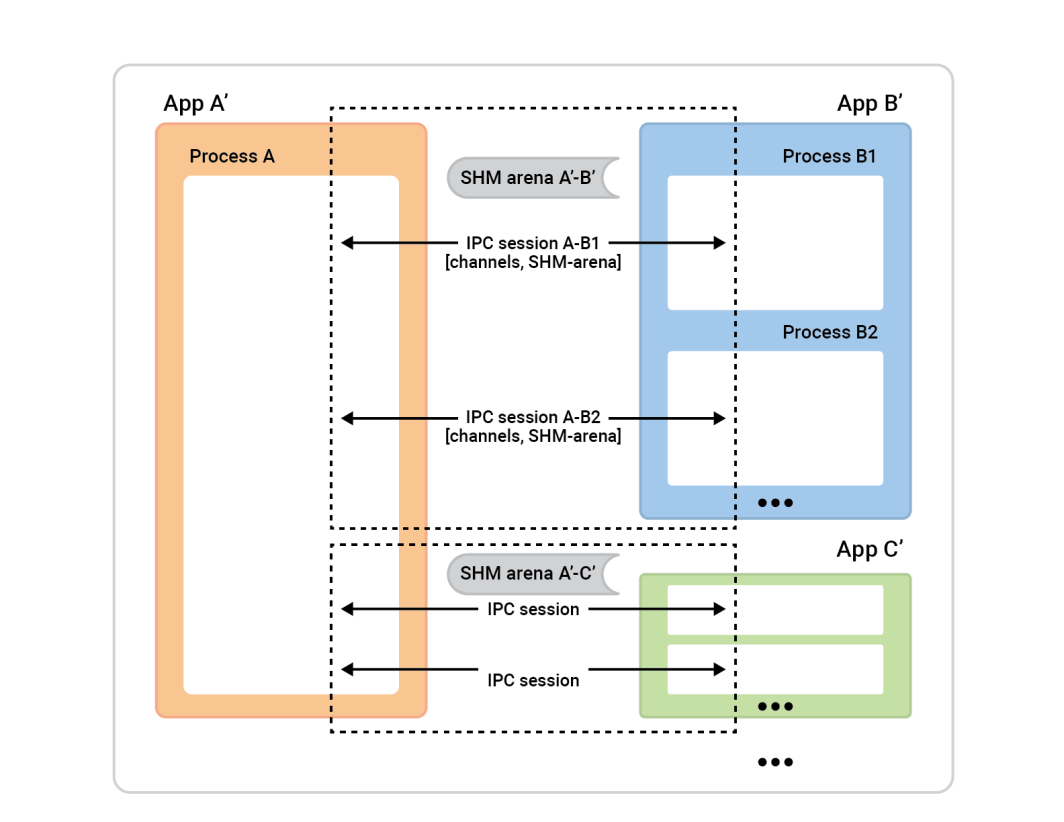
El proceso A de la izquierda se denomina servidor de sesión. Los cuadros de proceso de la derecha -clientes de sesión - se conectan al proceso A para establecer sesiones. Generalmente, cualquier sesión es completamente simétrica, por lo que no importa quién inició la conexión. Ambas partes son igualmente capaces y se les puede asignar cualquier función algorítmica. Sin embargo, antes de que la sesión esté lista, tendremos que asignar roles. Un lado será el cliente-sesión y realizará una conexión instantánea de una única sesión, y el otro lado, el servidor-sesión, aceptará tantas sesiones como quiera.
En este ejemplo, la configuración es sencilla. Hay dos aplicaciones con una sesión entre ellas y un canal en esa sesión. El cliente de caché (aplicación 2) desempeña el papel de cliente de sesión y la aplicación 1 el de servidor de sesión. Sin embargo, también funcionaría a la inversa.
Para configurar esto, cada aplicación (el cache-cliente y el cache-servidor) debe entender el mismo universo IPC, lo que sólo significa que necesitan conocer datos básicos sobre las aplicaciones implicadas.
He aquí por qué:
- El cliente necesita saber cómo localizar el servidor para iniciar una sesión. Si eres la aplicación conectora (el cliente), necesitas saber el nombre de la aplicación receptora. Flow-IPC utiliza el nombre del servidor para averiguar detalles como las direcciones de los sockets y los nombres de los segmentos de memoria compartida basándose en este nombre.
- Por razones de seguridad, la aplicación del servidor debe saber quién puede conectarse a ella. Flow-IPC comprueba los datos del cliente, como el usuario/grupo y la ruta del ejecutable, con el sistema operativo para asegurarse de que todo coincide.
- Los mecanismos de seguridad estándar del SO (propietarios, permisos) se aplican a varios transportes IPC (sockets, MQs, SHM). Un único selector
enumestablecerá la política de alto nivel a utilizar y Flow-IPC establecerá los permisos de la forma más restrictiva posible respetando dicha elección.
En nuestro caso, sólo tendremos que ejecutar lo siguiente en cada una de las dos aplicaciones. Esto puede ser en una sola .cpp vinculado a las aplicaciones cache-server y cache-client.
// IPC app universe: simple structs naming the 2 apps.
// The applications should share this code.
const ipc::session::Client_app
CLI_APP{ "cacheCli", // Name the app uniquely.
// From where it will run (for safety).
"/usr/bin/cache_client.exec",
CLI_UID, GID }; // The user and group ID (for safety).
const ipc::session::Server_app
SRV_APP{ { "cacheSrv", "/usr/bin/cache_server.exec", SRV_UID, GID },
// For the server, provide similar details --^.
// Plus a few server-specific settings:
// Safety: List client-app names that can connect to server-app.
// So in our case this will just be { "cacheCli" }.
{ CLI_APP.m_name },
"", // An optional path override; don't worry about it here.
// Safety/permissions selector:
// We've decided to run the two apps as different users
// in the same group - so we indicate that here.
ipc::util::Permissions_level::S_GROUP_ACCESS }; Tenga en cuenta que las configuraciones más complejas pueden tener más de estas definiciones.
Una vez ejecutado ese código en cada una de nuestras aplicaciones, simplemente pasaremos estos objetos al constructor del objeto de sesión para que el servidor sepa qué esperar cuando acepte sesiones y el cliente sepa a qué servidor conectarse.
Así que vamos a abrir la sesión. En la Aplicación 2 (el cliente caché), sólo queremos abrir una sesión y un canal dentro de ella. Aunque Flow-IPC permite abrir canales instantáneamente en cualquier momento (dado un objeto de sesión), es típico necesitar un cierto número de canales listos al inicio de la sesión. Como queremos abrir un canal, podemos dejar que Flow-IPC cree el canal al crear la sesión. Esto evita cualquier asincronía innecesaria. Así, al principio de la sesión de nuestro cache-client main() podemos conectar y abrir un canal con una única función .sync_connect() llamar:
// Specify that we *do* want zero-copy behavior, by merely choosing our
// backing-session type.
// In other words, setting this alias says, “be fast about Cap’n Proto things.”
//
// Different (subsequent) capnp-serialization-backing and SHM-related behaviors
// are available; just change this alias. E.g., omit `::shm::classic` to disable
// SHM entirely; or specify `::shm::arena_lend::jemalloc` to employ
// jemalloc-based SHM. Subsequent code remains the same!
// This demonstrates a key design tenet of Flow-IPC.
using Session = ipc::session::shm::classic::Client_session<...>;
// Tell Session object about the applications involved.
Session session{ CLI_APP, SRV_APP, /* detail omitted */ };
// Ask for 1 *channel* to be available on both sides
// from the very start of the session.
Session::Channels ipc_raw_channels(1);
// Instantly open session - and the 1 channel.
// (Fail if server is not running at this time.)
session.sync_connect(session.mdt_builder(), &ipc_raw_channels);
auto& ipc_raw_channel = ipc_raw_channels[0];
// (Can also instantly open more channel(s) anytime:
// `session.open_channel(&channel)`.)
Deberíamos tener un ipc_raw_channel now, que es un objeto de canal básico. Dependiendo de la configuración específica, esto podría representar un socket stream de dominio Unix, un POSIX MQ, u otros tipos de canales. Si quisiéramos, podríamos usarlo en sin estructurar de forma inmediata, lo que significa que podríamos usarlo para transmitir blobs binarios (con los límites preservados) y/o manejadores nativos (FDs). También podríamos acceder directamente a una arena SHM a través de session.session_shm()->construct<T>(...). Esto queda fuera de nuestro ámbito de discusión aquí, pero es una potente capacidad que merece la pena mencionar.
Por ahora, sólo queremos hablar el Cap'n Proto cache_demo::schema::Body (de nuestro archivo .capnp). Así que actualizar el objeto canal en bruto a un canal estructurado objeto así:
// Template arg indicates capnp schema. (Take a look at the .capnp file above.)
Session::Structured_channel<cache_demo::schema::Body>
ipc_channel
{ nullptr, std::move(ipc_raw_channel), “Eat” the raw channel: take over it.
ipc::transport::struc::Channel_base::S_SERIALIZE_VIA_SESSION_SHM,
&session }; Eso es todo para nuestra configuración. Ahora estamos listos para intercambiar mensajes capnp sobre el canal. Note que hemos evitado lidiar con detalles específicos del sistema operativo como nombres de objetos, valores de permisos Unix, y demás. Nuestro enfoque fue simplemente nombrar nuestras dos aplicaciones. También hemos optado por la transmisión de extremo a extremo sin copia para maximizar el rendimiento aprovechando la memoria compartida sin una sola copia. ::shm_open() o ::mmap() a la vista.
Ahora estamos listos para la parte divertida: emitir el GetCacheReq solicitud, recibiendo el GetCacheRsp y acceder a varias partes de esa respuesta, en concreto las partes del archivo y sus hashes.
Aquí está el código:
// Issue request and process response. TIMING FOR LATENCY GRAPH STARTS HERE -->
auto req_msg = ipc_channel.create_msg();
req_msg.body_root() // Vanilla capnp code: call Cap'n Proto-generated mutator API.
->initGetCacheReq().setFileName("huge-file.bin");
// Send message; get ~instant reply.
const auto rsp_msg = ipc_channel.sync_request(req_msg);
// More vanilla capnp work: accessors.
const auto rsp_root = rsp_msg->body_root().getGetCacheRsp();
// <-- TIMING FOR LATENCY GRAPH STOPS HERE.
// ...
verify_hash(rsp_root, some_file_chunk_idx);
// ...
// More vanilla Cap'n Proto accessor code.
void verify_hash(const cache_demo::schema::GetCacheRsp::Reader& rsp_root,
size_t idx)
{
const auto file_part = rsp_root.getFileParts()[idx];
if (file_part.getHashToVerify() != compute_hash(file_part.getData()))
{
throw Bad_hash_exception(...);
}
} En el código anterior hemos utilizado el sencillo .sync_request() que envía un mensaje y espera una respuesta concreta. La dirección ipc::transport::struc::Channel API proporciona una serie de sutilezas para hacer que los protocolos de código natural, incluyendo la recepción asíncrona, demultiplexación a las funciones de controlador por tipo de mensaje, la notificación frente a la solicitud, y no solicitada-mensaje frente a la respuesta. No se imponen restricciones al esquema (cache_demo::schema::Body en nuestro caso). Si es expresable en capnp, puede utilizarlo con canales estructurados Flow-IPC.
Ya está. La parte del servidor es similar en espíritu y nivel de dificultad. En perf_demo El código fuente está disponible.
Sin Flow-IPC, replicar esta configuración para obtener un rendimiento de copia cero de extremo a extremo implicaría una cantidad significativa de código difícil, incluida la gestión de segmentos SHM cuyos nombres y limpieza tendrían que coordinarse entre las dos aplicaciones. Incluso sin copia cero, es decir, simplemente ::write()una copia de la serialización capnp de req_msg a y ::read()ing rsp_msg de un socket de dominio Unix FD - en comparación, no sería trivial escribir un código suficientemente robusto.
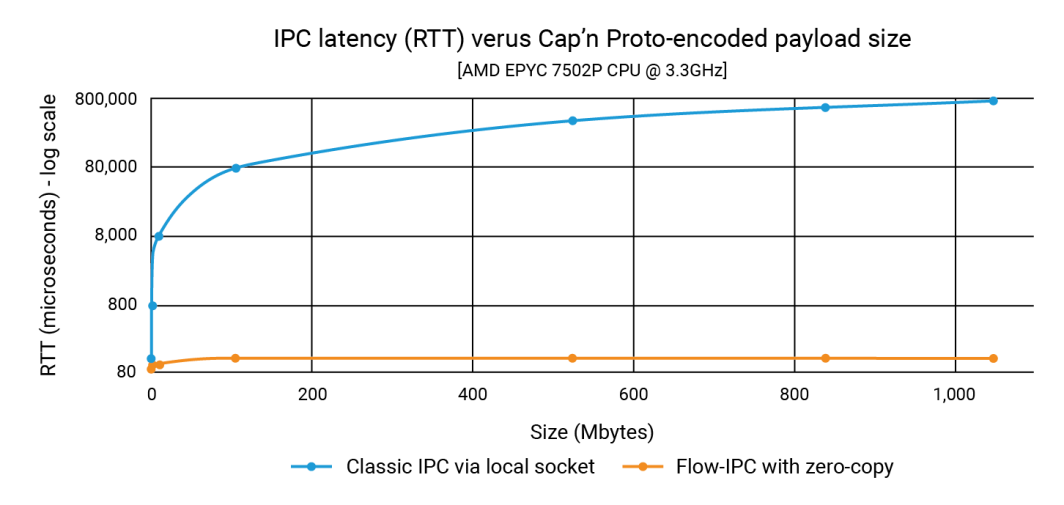
El siguiente gráfico muestra las latencias, donde cada punto del eje x representa la suma de todos los filePart.data para cada prueba. La línea azul muestra las latencias del método básico en el que App 1 escribe serializaciones capnp en un socket de dominio Unix utilizando ::write()y el apéndice 2 los lee con ::read(). La línea naranja representa las latencias del código que utiliza Flow-IPC, como se ha comentado anteriormente.
Cómo contribuir
Para solicitudes de funciones e informes de defectos, consulte la base de datos de problemas en el sitio GitHub de Flow-IPC. Presenta las incidencias que necesites.
Para contribuir con cambios y nuevas características, por favor consulte la guía de contribución. Puede ponerse en contacto con nosotros en el tablón de discusiones de Flow-IPC en GitHub.
¿Y ahora qué?
Hemos intentado ofrecer un experimento realista en el ejemplo anterior, sin omitir nada significativo en el código mostrado. Hemos elegido deliberadamente un escenario que carece de asincronía y callbacks. En consecuencia, surgirán preguntas como, "¿cómo integro Flow-IPC con mi bucle de eventos?" o, "¿cómo manejo el cierre de sesión y de canal? ¿Puedo abrir un simple stream socket sin todo este rollo de la sesión?", etc.
Estas cuestiones se abordan en la documentación completa. La documentación incluye una referencia generada a partir de los comentarios de la API en el código, un manual guiado con una curva de aprendizaje más suave e instrucciones de instalación. El archivo README del repositorio principal te dirigirá a todos estos recursos. La introducción del Manual y la sinopsis de la API cubren la amplitud de las funciones disponibles.
Recursos
- Anuncio de entrada en el blog
- Proyecto Flow-IPC en GitHub
Para instalar, leer la documentación, enviar solicitudes de características/cambios o contribuir. - Debates sobre Flow-IPC
Gran manera de llegar a nosotros - y el resto de la comunidad.


Comentarios