





 (1)")
Los grandes modelos lingüísticos (LLM) están de moda, especialmente con los recientes avances de OpenAI. El atractivo de los LLM radica en su capacidad para comprender, interpretar y generar lenguaje humano de una forma que antes se creía exclusiva de los humanos. Herramientas como CoPilot se están integrando rápidamente en el día a día de los desarrolladores, mientras que las aplicaciones basadas en ChatGPT son cada vez más habituales.
La popularidad de los LLM también se debe a su accesibilidad para el desarrollador medio. Con muchos modelos de código abierto disponibles, cada día aparecen nuevas startups tecnológicas con algún tipo de solución a un problema basada en LLM.
Se ha dicho que los datos son el "nuevo petróleo". En el aprendizaje automático, los datos sirven como materia prima para entrenar, probar y validar modelos. Los datos de alta calidad, diversos y representativos son esenciales para crear LLM precisos, fiables y sólidos.
Crear tu propio LLM puede ser todo un reto, especialmente cuando se trata de recopilar y almacenar datos. El manejo de grandes volúmenes de datos no estructurados, junto con su almacenamiento y la gestión del acceso, son sólo algunos de los retos a los que podrías enfrentarte. En esta entrada, exploraremos estos retos de gestión de datos. En concreto, veremos:
- Cómo funcionan los LLM y cómo elegir entre los modelos existentes
- Tipos de datos utilizados en los LLM
- Canalización e ingesta de datos para LLM
Nuestro objetivo es ofrecerle una comprensión clara del papel fundamental que desempeñan los datos en los LLM, dotándole de los conocimientos necesarios para gestionar los datos de forma eficaz en sus propios proyectos de LLM.
Para empezar, vamos a sentar unas bases básicas de comprensión de los LLM.
Cómo funcionan los LLM y cómo elegir entre los modelos existentes
A grandes rasgos, un LLM funciona convirtiendo palabras (u oraciones) en representaciones numéricas denominadas incrustaciones. Estas incrustaciones captan el significado semántico y las relaciones entre las palabras, lo que permite al modelo entender el lenguaje. Por ejemplo, un LLM aprendería que las palabras "perro" y "cachorro" están relacionadas, y las colocaría más cerca en su espacio numérico, mientras que la palabra "árbol" estaría más alejada.

La parte más crítica de un LLM es la red neuronal, que es un modelo informático inspirado en el funcionamiento del cerebro humano. La red neuronal puede aprender estas incrustaciones y sus relaciones a partir de los datos con los que se entrena. Como ocurre con la mayoría de las aplicaciones de aprendizaje automático, los modelos LLM necesitan grandes cantidades de datos. Normalmente, cuantos más datos y de mayor calidad sean para el entrenamiento del modelo, más preciso será el modelo, lo que significa que necesitarás un buen método para gestionar los datos para tus LLM.
Consideraciones al sopesar los modelos existentes
Afortunadamente para los desarrolladores, actualmente existen muchas opciones de código abierto para los LLM, con varias opciones populares que permiten el uso comercial, entre ellas:
- Dolly (publicado por Databricks)
- Open LLaMA (Meta reproducción)
- Muchos, muchos más
Con una lista tan extensa entre la que elegir, seleccionar el modelo LLM de código abierto adecuado puede resultar complicado. Es importante conocer los recursos informáticos y de memoria necesarios para un modelo LLM. El tamaño del modelo -por ejemplo, 3.000 millones de parámetros de entrada frente a 7.000 millones- influye en la cantidad de recursos que necesitará para ejecutar y ejercitar el modelo. Compárelo con sus capacidades. Por ejemplo, varios modelos DLite se han puesto a disposición específicamente para ser ejecutados en ordenadores portátiles en lugar de requerir recursos en la nube de alto coste.
Al investigar cada LLM, es importante tener en cuenta cómo se ha entrenado el modelo y a qué tipo de tarea está orientado en general. Estas distinciones también afectarán a su elección. La planificación de su trabajo de LLM implicará examinar las opciones de modelos de código abierto, comprender dónde brilla mejor cada modelo y anticipar los recursos que necesitará utilizar para cada modelo.
Dependiendo de la aplicación o el contexto en el que vaya a necesitar un LLM, puede empezar con un LLM existente o puede optar por entrenar un LLM desde cero. Con un LLM existente, puedes utilizarlo tal cual o afinar el modelo con datos adicionales que sean representativos de la tarea que tienes en mente.
La elección del mejor enfoque para sus necesidades requiere una sólida comprensión de los datos utilizados para el entrenamiento de los LLM.
Tipos de datos utilizados en los LLM
Cuando se trata de formar a un LLM, los datos utilizados suelen ser textuales. Sin embargo, la naturaleza de estos datos textuales puede variar mucho, por lo que es esencial comprender los distintos tipos de datos que pueden encontrarse. En general, los datos LLM pueden clasificarse en dos tipos: datos semiestructurados y datos no estructurados. Los datos estructurados, que son los representados en un conjunto de datos tabulares, es poco probable que se utilicen en los LLM.
Datos semiestructurados
Los datos semiestructurados se organizan de una manera predefinida y siguen un modelo determinado. Esta organización permite realizar búsquedas y consultas sencillas de los datos. En el contexto de los LLM, un ejemplo de datos semiestructurados podría ser un corpus de texto en el que cada entrada está asociada a ciertas etiquetas o metadatos. Algunos ejemplos de datos semiestructurados son
- Artículos de noticias, cada uno asociado a una categoría (como deportes, política o tecnología).
- Opiniones de clientes, con cada opinión asociada a una valoración e información sobre el producto.
- Publicaciones en redes sociales, con cada publicación asociada al usuario que la publicó, la hora de publicación y otros metadatos.
En estos casos, un LLM podría aprender a predecir la categoría basándose en el artículo de la noticia, la valoración basándose en el texto de la reseña o el sentimiento de una publicación en las redes sociales basándose en su contenido.
Datos no estructurados
En cambio, los datos no estructurados carecen de una organización o un modelo predefinidos. Estos datos suelen estar repletos de texto y también pueden contener fechas, números y hechos, lo que los hace más complicados de procesar y analizar. En el contexto de los LLM, los datos no estructurados son muy comunes. Algunos ejemplos de datos no estructurados son
- Libros, artículos y otros contenidos extensos
- Transcripciones de entrevistas o podcasts
- Páginas web o documentos
Sin etiquetas explícitas ni etiquetas organizativas, los datos no estructurados son más difíciles de entrenar con LLM. Sin embargo, también pueden dar lugar a modelos más generales. Por ejemplo, un modelo entrenado con un gran corpus de libros podría aprender a generar prosa realista, como ocurre con GPT-3.

Hemos visto que los datos son el núcleo de los LLM, pero ¿cómo pasan estos datos de su estado bruto a un formato que pueda utilizar un LLM? Centrémonos en los principales procesos implicados.
Canalización e ingestión de datos para LLM
Los componentes básicos de la adquisición y el procesamiento de datos para un LLM residen en los conceptos de canalización de datos e ingestión de datos.
¿Qué es una canalización de datos?
Las canalizaciones de datos constituyen el conducto entre los datos brutos no estructurados y un LLM totalmente entrenado. Garantizan que los datos se recopilen, procesen y preparen correctamente, de modo que estén listos para las fases de formación y validación del proceso de creación del LLM.
Una canalización de datos es un conjunto de procesos que mueven los datos desde su origen hasta un destino donde pueden almacenarse y analizarse. Normalmente, esto implica:
- Extracción de datos: Los datos se extraen de su fuente, que puede ser una base de datos, un almacén de datos o incluso una API externa.
- Transformación de datos: Los datos brutos deben limpiarse y transformarse en un formato adecuado para el análisis. La transformación incluye el tratamiento de los valores que faltan, la corrección de los datos incoherentes, la conversión de los tipos de datos o la codificación de variables categóricas.
- Carga de datos: Los datos transformados se cargan en un sistema de almacenamiento, como una base de datos o un almacén de datos. Estos datos están disponibles para su uso en un modelo de aprendizaje automático.
Cuando hablamos de ingesta de datos, nos referimos a la parte delantera de estos procesos de canalización, que se ocupa de la adquisición de datos y su preparación para el uso.
¿Qué aspecto tiene una canalización de datos en el contexto de un LLM?
Si bien la canalización de datos para un LLM puede coincidir en general con la mayoría de las canalizaciones utilizadas por los equipos de datos, los LLM introducen ciertos retos únicos en la gestión de datos para LLM. Por ejemplo:
- Extracción de datos: La extracción de datos para un LLM suele ser más compleja, variada e informática. Dado que las fuentes de datos pueden ser sitios web, libros, transcripciones o redes sociales, cada fuente tiene sus propios matices y requiere un enfoque único.
- Transformación de datos: Con una gama tan amplia de fuentes de datos LLM, cada paso de transformación para cada tipo de datos será diferente, requiriendo una lógica única para procesar los datos en un formato más estándar que un LLM pueda consumir para el entrenamiento.
- Carga de datos: En muchos casos, el paso final de la carga de datos puede requerir tecnologías de almacenamiento de datos fuera de lo normal. Los datos de texto no estructurados pueden requerir el uso de bases de datos NoSQL, en contraste con los almacenes de datos relacionales utilizados por muchas canalizaciones de datos.
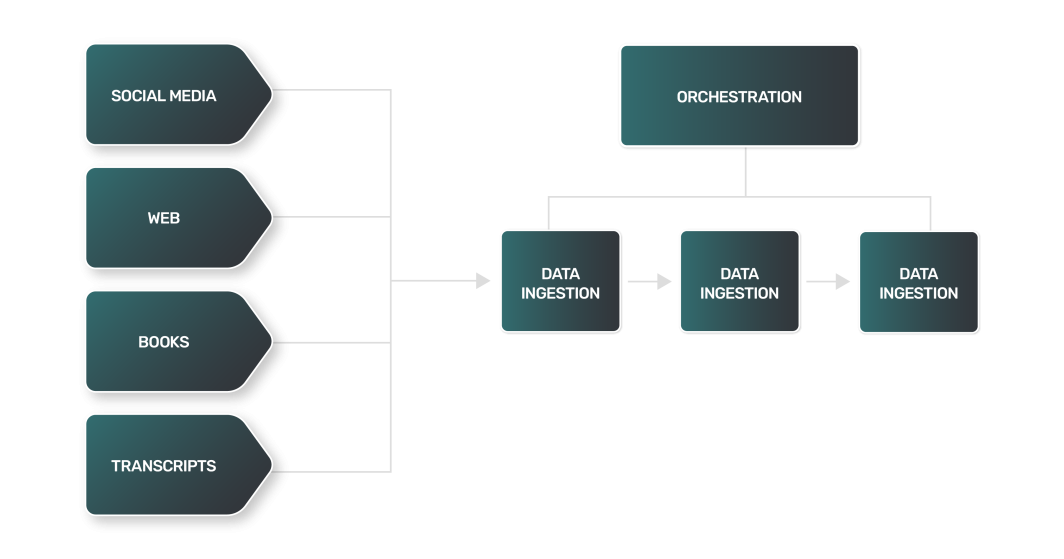
El proceso de transformación de datos para los LLM incluye técnicas similares a las del procesamiento del lenguaje natural (PLN):
- Tokenización: Descomposición del texto en palabras individuales o "tokens".
- Eliminación de palabras vacías: Eliminación de palabras de uso común como "y", "el" y "es". Sin embargo, dependiendo de la tarea para la que se haya entrenado el LLM, las palabras vacías pueden conservarse para preservar información sintáctica y semántica importante.
- Lematización: Reducción de palabras a su forma base o raíz.
Como puedes imaginar, combinar todos estos pasos para ingerir cantidades masivas de datos procedentes de una amplia gama de fuentes puede dar lugar a una canalización de datos increíblemente complicada y de gran tamaño. Para ayudarte en tu tarea, necesitarás buenas herramientas y recursos.
Herramientas habituales para la ingestión de datos
Varias herramientas extremadamente populares en el espacio de la ingeniería de datos pueden ayudarle con los complejos procesos de ingestión de datos que forman parte de su canalización de datos. Si está creando su propio LLM, la mayor parte de su tiempo de desarrollo se dedicará a recopilar, limpiar y almacenar los datos utilizados para el entrenamiento. Las herramientas que le ayudarán a gestionar los datos para los LLM pueden clasificarse de la siguiente manera:
- Orquestación de canalizaciones: Plataformas para supervisar y gestionar los procesos de su canalización de datos.
- Computación: Recursos para procesar tus datos a escala.
- Almacenamiento: Bases de datos para almacenar la gran cantidad de datos necesarios para una formación LLM eficaz.
Veamos cada uno de ellos con más detalle.
Orquestación de canalizaciones
Apache Airflow es una conocida plataforma de código abierto que permite programar, programar y supervisar flujos de trabajo de datos. Permite crear canalizaciones de datos complejas con su interfaz de codificación basada en Python, que es versátil y fácil de usar. Las tareas en Airflow se organizan en grafos acíclicos dirigidos (DAG), donde cada nodo representa una tarea, y los bordes representan las dependencias entre las tareas.
Airflow se utiliza ampliamente para operaciones de extracción, transformación y carga de datos, lo que lo convierte en una valiosa herramienta en el proceso de ingestión de datos. Linode Marketplace ofrece Apache Air flow para facilitar su configuración y uso.
Calcular
Además de la gestión de canalizaciones con herramientas como Airflow, necesitará recursos informáticos adecuados que puedan funcionar de forma fiable a escala. A medida que ingiera grandes cantidades de datos textuales y realice el procesamiento posterior a partir de muchas fuentes, su tarea requerirá recursos informáticos que puedan escalarse -idealmente, de forma horizontal- según sea necesario.
Una opción popular para la informática escalable es Kubernetes. Kubernetes aporta flexibilidad y se integra bien con muchas herramientas, como Airflow. Al aprovechar Kubernetes gestionado, puede poner en marcha recursos informáticos flexibles de forma rápida y sencilla.
Almacenamiento
Una base de datos forma parte integrante del proceso de ingesta de datos, ya que constituye el destino principal de los datos ingeridos una vez limpiados y transformados. Se pueden emplear varios tipos de bases de datos. El tipo que se utilice dependerá de la naturaleza de los datos y de los requisitos específicos de su caso de uso:
- Las bases de datos relacionales utilizan una estructura tabular para almacenar y representar datos. Son una buena opción para datos que tienen relaciones claras y donde la integridad de los datos es crítica. Aunque tu LLM dependerá de datos no estructurados, una base de datos relacional como PostgreSQL también puede trabajar con tipos de datos no estructurados.
- Bases de datos NoSQL: Las bases de datos NoSQL incluyen bases de datos orientadas a documentos, que no utilizan una estructura tabular para almacenar datos. Son una buena opción para manejar grandes volúmenes de datos no estructurados, ya que ofrecen un alto rendimiento, alta disponibilidad y fácil escalabilidad.
Como alternativa a las bases de datos para el almacenamiento de datos LLM, algunos ingenieros prefieren utilizar sistemas de archivos distribuidos. Algunos ejemplos son AWS S3 o Hadoop. Aunque un sistema de archivos distribuido puede ser una buena opción para almacenar grandes cantidades de datos no estructurados, requiere un esfuerzo adicional para organizar y gestionar sus grandes conjuntos de datos.
Para las opciones de almacenamiento de Marketplace, encontrarás PostgreSQL gestionado y MySQL gestionado. Ambas opciones son fáciles de configurar y conectar a tu canal de datos LLM.
Aunque es posible que los LLM más pequeños se entrenen con menos datos y funcionen con bases de datos más pequeñas (como un único nodo PostgreSQL), los casos de uso más intensivos trabajarán con grandes cantidades de datos. En estos casos, probablemente necesitará algo como un Cluster Post greSQL para soportar el volumen de datos con el que trabajará, administrar datos para LLMs, y servir esos datos de manera confiable.
A la hora de elegir una base de datos para gestionar los datos de los LLM, ten en cuenta la naturaleza de los datos y los requisitos de tu caso. El tipo de datos que ingiera determinará qué tipo de base de datos se adapta mejor a sus necesidades. Los requisitos de su caso de uso, como el rendimiento, la disponibilidad y la escalabilidad, también serán consideraciones importantes.
La ingesta de datos de forma eficaz y precisa es crucial para el éxito de un LLM. Con el uso adecuado de las herramientas, puede crear procesos de ingesta de datos fiables y eficientes para su canal, gestionar grandes cantidades de datos y garantizar que su LLM tenga lo que necesita para aprender y ofrecer resultados precisos.
Para concluir
El meteórico aumento de la popularidad de los LLM ha abierto nuevas puertas en el espacio tecnológico. La tecnología es fácilmente accesible para los desarrolladores, pero su capacidad para gestionar los datos de los LLM y aprovecharlos para formar nuevos LLM o perfeccionar los existentes dictará su éxito a largo plazo.
Si estás empezando a trabajar en un proyecto LLM, necesitas comprender los conceptos básicos antes de lanzarte a ello. Para ser más eficaz, un LLM requiere la ingestión de un gran volumen de datos no estructurados, un proceso que incluye la extracción de fuentes, el preprocesamiento, la transformación y la importación. La realización de estas tareas requiere herramientas como Airflow y Kubernetes para la orquestación de canalizaciones y recursos informáticos escalables. Además, la naturaleza no estructurada de los datos utilizados habitualmente para la formación de LLM requiere una opción de almacenamiento de datos como PostgreSQL, que puede utilizarse de forma fiable a escala mediante clústeres.




Comentarios (1)
Artigo muito bom para quem quer se aprofundar em LLM! Parabéns!