






Dependiendo de a quién preguntes, el auge de la IA significa que acceder a potentes GPU en la nube es pan comido... o casi imposible. El problema es encontrar laGPU adecuada en el proveedor adecuado sin pagar de más por recursos de hardware que no necesitas de forma realista, y que estarán disponibles solo cuando los necesites, sin necesidad de comprometerte con reservas de prepago o contratos abultados.
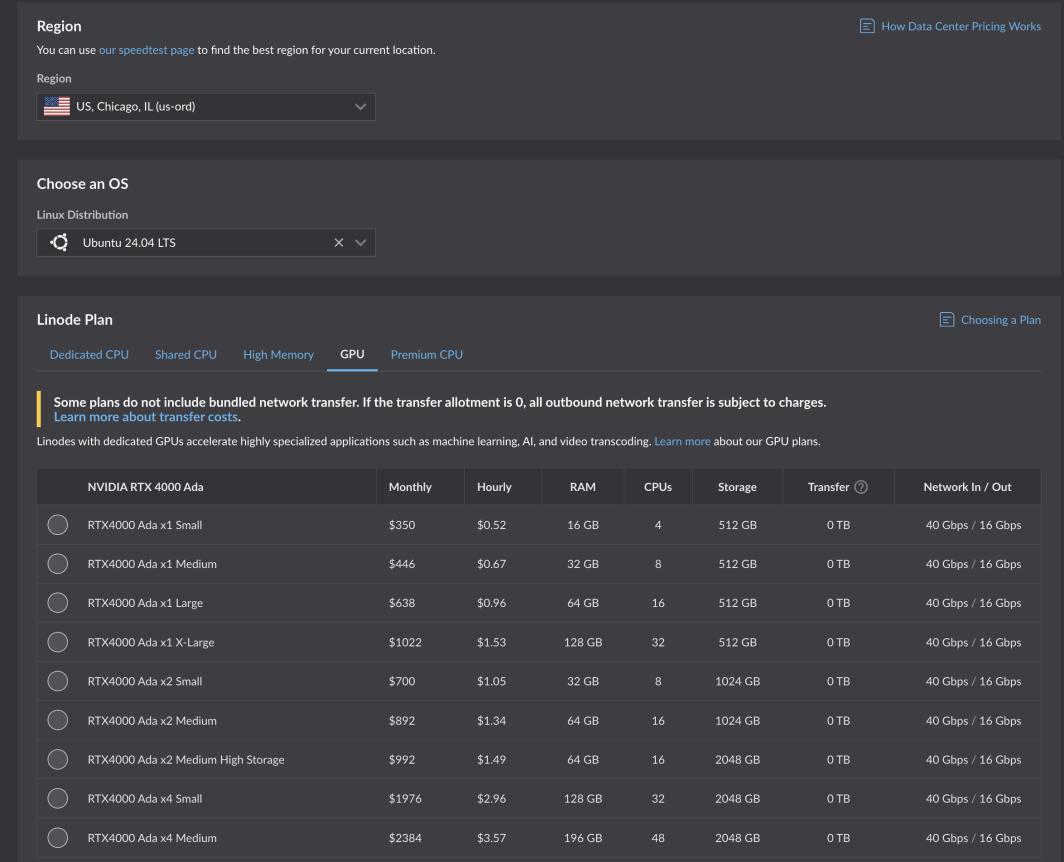
Es una tarea difícil, y aceptamos encantados el reto". Tras rigurosas pruebas y optimizaciones, las nuevas GPU de Akamai ya están disponibles para todos los clientes. Equipadas con las tarjetas NVIDIA RTX 4000 Ada Generation, estas GPU están optimizadas para casos de uso de medios, pero tienen el tamaño adecuado para una amplia gama de cargas de trabajo y aplicaciones. Los planes de la Generación Ada RTX 4000 comienzan en 0,52 dólares por hora para 1 GPU, 4 CPU y 16 GB de RAM en seis regiones de computación central:
- Chicago, IL
- Seattle, WA
- Frankfurt, DE Expansión
- París, FR
- Osaka, JP
- Singapur, SG Expansión
- Ampliación de Mumbai, IN (próximamente)
Casos prácticos destacados
A través de nuestro programa beta, nuestros clientes y socios proveedores de software independientes (ISV ) pudieron poner a prueba nuestras nuevas GPU, incluso para casos de uso clave que sabíamos que se beneficiarían de las especificaciones del plan GPU que diseñamos: transcodificación de medios e IA ligera.
El codificador alojado en la nube de Capella Systems, Cambria Stream, se encarga de la codificación en directo, la inserción de anuncios, el cifrado y el empaquetado de los eventos en directo más exigentes. Se necesita la tecnología y la configuración adecuadas entre bastidores para que los usuarios finales puedan ver eventos transmitidos en directo desde todos los dispositivos y en todas las infraestructuras de red.
"Utilizando la nueva NVIDIA RTX 4000 Ada Generation Dual GPU de Akamai, un único Cambria Stream puede procesar hasta 25 canales de codificación multicapa a la vez, reduciendo significativamente el coste informático total en comparación con la codificación basada en CPU."
Lea el comunicado de prensa completo.
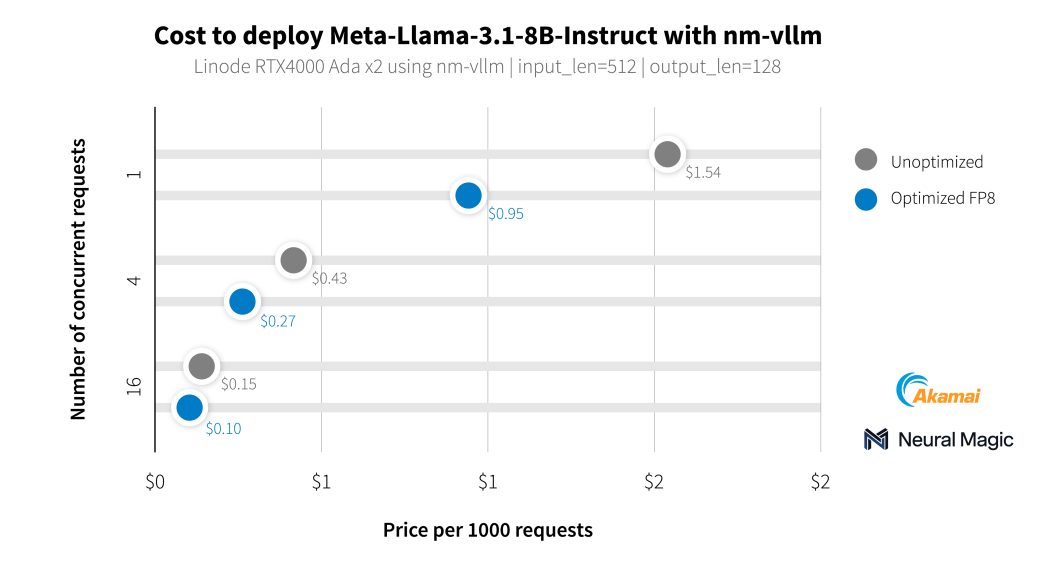
Además de con nuestros clientes del sector de los medios de comunicación, hemos trabajado con Neural Magic para evaluar la capacidad de inteligencia artificial de nuestras nuevas GPU utilizando nm-vllm, su motor de servidores LLM preparado para empresas. Utilizaron su kit de herramientas de compresión de código abierto para LLM, LLM Compressor, para producir implantaciones mucho más eficientes con una conservación de la precisión del 99,9%. Al probar los últimos modelos Llama 3.1, Neural Magic utilizó sus optimizaciones de software para conseguir un coste medio de 0,27 dólares por cada 1.000 peticiones de resumen utilizando GPU RTX 4000, lo que supone una reducción del 60% en comparación con la implantación de referencia.
Comenzar
Si ya tiene una cuenta, puede empezar de inmediato. Solo tiene que seleccionar una región compatible y navegar hasta la pestaña GPU de la tabla del plan de instancias de cálculo.
Empieza con nuestra documentación.
Animamos a los desarrolladores que crean y gestionan aplicaciones empresariales a que se pongan en contacto con nuestros equipos de consultores en la nube.
Nota: El uso de las instancias de Akamai GPU requiere un historial de facturación positivo en su cuenta, sin incluir códigos promocionales. Si no puede implementar y necesita acceso a GPU , abra un ticket de soporte.





Comentarios