






Wenn Entwickler eine Arbeitslast auf einer Cloud-Computing-Plattform bereitstellen, denken sie oft nicht über die zugrunde liegende Hardware nach, auf der ihre Dienste laufen. In der idealisierten Vorstellung von der "Cloud" sind Hardware-Wartung und physische Einschränkungen unsichtbar. Leider muss die Hardware gelegentlich gewartet werden, was zu Ausfallzeiten führen kann. Um zu vermeiden, dass diese Ausfallzeiten an unsere Kunden weitergegeben werden, und um das Versprechen der Cloud zu erfüllen, implementiert Linode ein Tool namens Live Migrations.
Live Migrations ist eine Technologie, die es Linode-Instanzen ermöglicht, zwischen physischen Maschinen ohne Unterbrechung des Dienstes zu wechseln. Wenn eine Linode mit Live Migrations verschoben wird, ist der Übergang für die Prozesse der Linode unsichtbar. Wenn die Hardware eines Hosts gewartet werden muss, kann Live Migrations verwendet werden, um alle Linodes dieses Hosts nahtlos auf einen neuen Host zu übertragen. Nachdem die Migration abgeschlossen ist, kann die physische Hardware repariert werden, und die Ausfallzeit hat keine Auswirkungen auf unsere Kunden.
Für mich war die Entwicklung dieser Technologie ein entscheidender Moment und ein Wendepunkt zwischen Cloud-Technologien und Nicht-Cloud-Technologien. Ich habe ein Faible für die Live-Migrations-Technologie, weil ich mehr als ein Jahr meines Lebens damit verbracht habe, an ihr zu arbeiten. Jetzt kann ich diese Geschichte mit Ihnen allen teilen.
Wie Live-Migrationen funktionieren
Live Migrations bei Linode begann wie die meisten neuen Projekte: mit viel Forschung, einer Reihe von Prototypen und der Hilfe von vielen Kollegen und Managern. Der erste Schritt nach vorne war die Untersuchung, wie QEMU Live-Migrationen handhabt. QEMU ist eine Virtualisierungstechnologie, die von Linode verwendet wird, und Live-Migrationen sind eine Funktion von QEMU. Folglich lag der Fokus unseres Teams darauf, diese Technologie zu Linode zu bringen, und nicht darauf, sie zu erfinden.
Wie also funktioniert die Live-Migrationstechnologie so, wie QEMU sie implementiert hat? Die Antwort ist ein vierstufiger Prozess:
- Die Ziel-Qemu-Instanz wird mit genau denselben Parametern gestartet, die auch auf der Quell-Qemu-Instanz vorhanden sind.
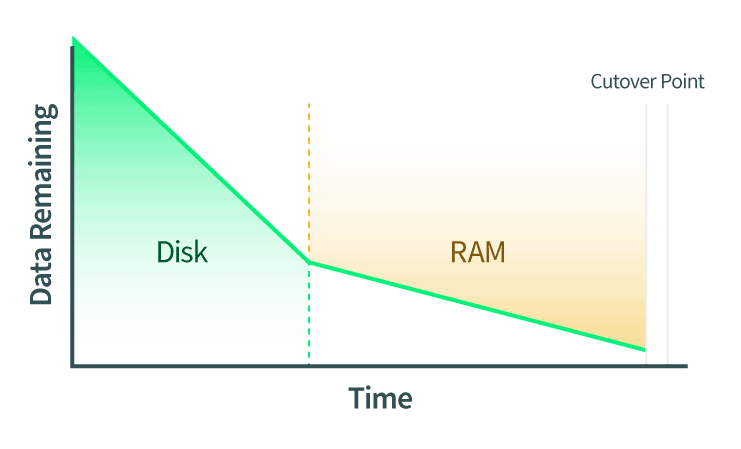
- Die Festplatten werden live migriert. Während dieser Übertragung werden auch alle Änderungen an der Festplatte mitgeteilt.
- Das RAM ist live migriert. Alle Änderungen an den RAM-Seiten müssen ebenfalls mitgeteilt werden. Wenn sich in dieser Phase auch die Festplattendaten ändern, werden diese Änderungen ebenfalls auf die Festplatte der Ziel-QEMU-Instanz kopiert.
- Der Umschaltpunkt wird ausgeführt. Wenn QEMU feststellt, dass nur noch wenige RAM-Seiten vorhanden sind, die es sicher umschalten kann, werden die Quell- und Ziel-QEMU-Instanzen angehalten. QEMU kopiert die letzten Seiten des RAMs und den Maschinenstatus. Der Maschinenzustand umfasst den CPU-Cache und die nächste CPU-Anweisung. Dann weist QEMU die Zielinstanz an, zu starten, und die Zielinstanz macht genau dort weiter, wo die Quelle aufgehört hat.
Diese Schritte erklären, wie man eine Live-Migration mit QEMU auf hohem Niveau durchführt. Die genaue Festlegung, wie die Ziel-QEMU-Instanz gestartet werden soll, ist jedoch ein sehr manueller Prozess. Außerdem muss jede Aktion des Prozesses zum richtigen Zeitpunkt gestartet werden.
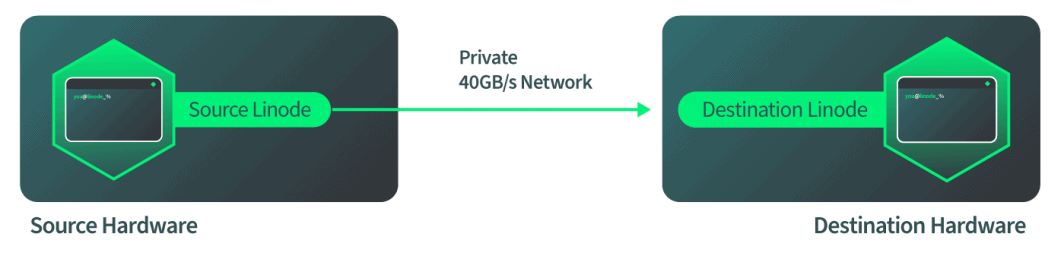
Wie Live-Migrationen bei Linode implementiert werden
Nachdem wir uns angesehen haben, was die QEMU-Entwickler bereits geschaffen haben, wie können wir dies bei Linode nutzen? Die Antwort auf diese Frage war der Hauptteil der Arbeit für unser Team.
In Übereinstimmung mit Schritt 1 des Live-Migrations-Workflows wird die Ziel-QEMU-Instanz hochgefahren, um die eingehende Live-Migration zu akzeptieren. Bei der Implementierung dieses Schritts war der erste Gedanke, das Konfigurationsprofil der aktuellen Linode zu nehmen und es auf einer Zielmaschine zu starten. Theoretisch wäre dies einfach, aber wenn man weiter darüber nachdenkt, ergeben sich kompliziertere Szenarien. Insbesondere sagt das Konfigurationsprofil aus, wie die Linode gebootet wurde, aber es beschreibt nicht unbedingt den kompletten Zustand der Linode nach dem Booten. Zum Beispiel könnte ein Benutzer ein Gerät angeschlossen haben Block Storage Gerät angeschlossen haben, indem er es im laufenden Betrieb an die Linode angeschlossen hat, nachdem diese gebootet wurde, und dies würde nicht im Konfigurationsprofil dokumentiert werden.
Um die QEMU-Instanz auf dem Zielhost zu erstellen, musste ein Profil der aktuell laufenden QEMU-Instanz erstellt werden. Wir erstellten ein Profil dieser aktuell laufenden QEMU-Instanz, indem wir die QMP-Schnittstelle untersuchten. Diese Schnittstelle gibt uns Informationen darüber, wie die QEMU-Instanz aufgebaut ist. Sie liefert keine Informationen darüber, was innerhalb der Instanz aus der Sicht des Gastes vor sich geht. Sie sagt uns, wo die Festplatten eingesteckt sind und in welchen virtualisierten PCI-Steckplatz die virtuellen Festplatten eingesteckt sind, sowohl für lokale SSD- als auch für Blockspeicher. Nach der Abfrage von QMP und der Inspektion und Untersuchung der QEMU-Instanz wird ein Profil erstellt, das genau beschreibt, wie diese Maschine auf dem Zielrechner reproduziert werden kann.
Auf dem Zielrechner erhalten wir die vollständige Beschreibung, wie die Quellinstanz aussieht. Wir können dann die Instanz hier originalgetreu nachbilden, mit einem Unterschied. Der Unterschied besteht darin, dass die Ziel-QEMU-Instanz mit einer Option gebootet wird, die QEMU anweist, eine eingehende Migration zu akzeptieren.
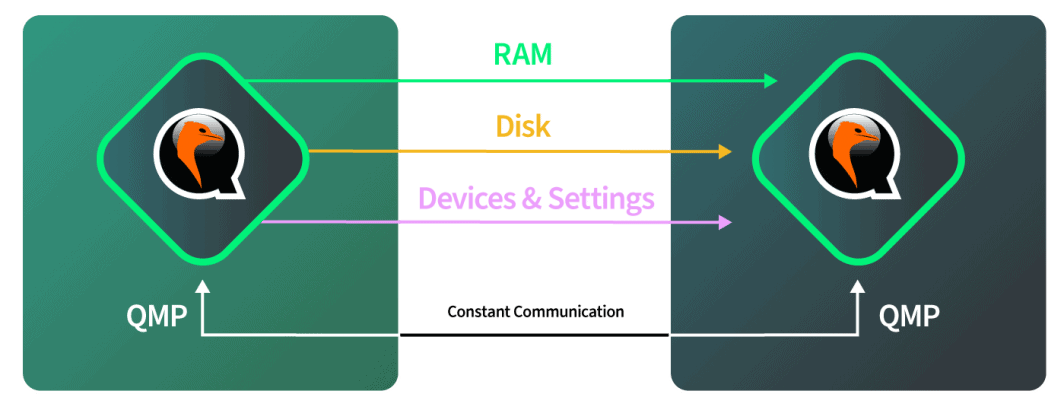
An dieser Stelle sollten wir eine Pause von der Dokumentation der Live-Migrationen einlegen und dazu übergehen, zu erklären, wie QEMU diese Leistungen vollbringt. Der QEMU-Prozessbaum besteht aus einem Kontrollprozess und mehreren Arbeitsprozessen. Einer der Arbeitsprozesse ist für Dinge wie die Rückgabe von QMP-Aufrufen oder die Bearbeitung einer Live-Migration verantwortlich. Die anderen Prozesse werden eins zu eins auf die Gast-CPUs abgebildet. Die Umgebung des Gastes ist von dieser Seite von QEMU isoliert und verhält sich wie ein eigenes, unabhängiges System.
In diesem Sinne gibt es 3 Ebenen, mit denen wir arbeiten:
- Schicht 1 ist unsere Verwaltungsschicht;
- Schicht 2 ist der Teil des QEMU-Prozesses, der all diese Aktionen für uns durchführt; und
- Schicht 3 ist die eigentliche Gastschicht, mit der Linode-Benutzer interagieren.
Nachdem das Ziel hochgefahren und bereit ist, die eingehende Migration zu akzeptieren, teilt die Zielhardware der Quellhardware mit, dass die Quelle mit dem Senden von Daten beginnen soll. Die Quelle startet, sobald sie dieses Signal erhält, und wir weisen QEMU in der Software an, die Festplattenmigration zu starten. Die Software überwacht selbstständig den Fortschritt der Festplattenmigration, um festzustellen, wann sie abgeschlossen ist. Die Software schaltet dann automatisch auf RAM-Migration um, wenn die Festplatte fertig ist. Die Software überwacht dann wiederum selbstständig die RAM-Migration und schaltet dann automatisch in den Cutover-Modus, wenn die RAM-Migration abgeschlossen ist. All dies geschieht über das 40-GBit/s-Netzwerk von Linode, so dass die Netzwerkseite der Dinge ziemlich schnell ist.
Umschnitt: Der kritische Abschnitt
Der Cutover-Schritt wird auch als der kritische Abschnitt einer Live-Migration bezeichnet, und das Verständnis dieses Schritts ist der wichtigste Teil des Verständnisses von Live-Migrationen.
Am Umschaltpunkt hat QEMU festgestellt, dass es bereit ist, umzuschalten und den Betrieb auf dem Zielrechner zu starten. Die Quell-QEMU-Instanz weist beide Seiten an, eine Pause einzulegen. Dies bedeutet mehrere Dinge:
- Die Zeit bleibt je nach Gast stehen. Wenn der Gast einen Zeitsynchronisationsdienst wie das Network Time Protocol(NTP) verwendet, wird NTP die Zeit nach Abschluss der Live-Migration automatisch neu synchronisieren. Der Grund dafür ist, dass die Systemuhr einige Sekunden hinterherhinken wird.
- Netzwerkanfragen werden gestoppt. Wenn es sich um TCP-basierte Netzwerkanforderungen wie SSH oder HTTP handelt, gibt es keinen wahrnehmbaren Verlust der Konnektivität. Handelt es sich um UDP-basierte Netzwerkanforderungen wie Live-Video-Streaming, kann es zu einigen verlorenen Frames kommen.
Da die Zeit und die Netzwerkanfragen angehalten werden, soll die Umschaltung so schnell wie möglich erfolgen. Es gibt jedoch einige Dinge, die wir zuerst überprüfen müssen, um sicherzustellen, dass die Umschaltung erfolgreich ist:
- Stellen Sie sicher, dass die Live-Migration ohne Fehler abgeschlossen wurde. Wenn ein Fehler auftrat, machen wir einen Rollback, heben die Pause der Quell-Linode auf und fahren nicht weiter fort. Dieser Punkt erforderte während der Entwicklung eine Menge Versuche und Irrtümer, um ihn zu beheben, und er war die Quelle vieler Schmerzen, aber unser Team hat schließlich den Grund dafür gefunden.
- Stellen Sie sicher, dass das Netzwerk an der Quelle ausgeschaltet und am Zielort ordnungsgemäß gestartet wird.
- Lassen Sie den Rest unserer Infrastruktur genau wissen, auf welchem physischen Rechner sich diese Linode jetzt befindet.
Da für die Umstellung ein Zeitlimit gilt, wollen wir diese Schritte schnell abschließen. Nachdem diese Punkte abgearbeitet sind, schließen wir die Umschaltung ab. Die Quell-Linode erhält automatisch das abgeschlossene Signal und sagt der Ziel-Linode, dass sie beginnen soll. Die Ziel-Linode macht genau da weiter, wo sie aufgehört hat. Alle verbleibenden Elemente auf der Quelle und dem Ziel werden aufgeräumt. Wenn die Ziel-Linode zu einem späteren Zeitpunkt erneut live migriert werden muss, kann der Prozess wiederholt werden.
Überblick über Edge Cases
Der größte Teil dieses Prozesses war einfach zu implementieren, aber die Entwicklung von Live-Migrationen wurde durch Sonderfälle erweitert. Ein großer Teil des Verdienstes für den Abschluss dieses Projekts gebührt dem Managementteam, das die Vision des fertigen Tools erkannte und die Ressourcen für die Durchführung der Aufgabe bereitstellte, sowie den Mitarbeitern, die das Projekt bis zum Abschluss durchführten.
Im Folgenden werden einige der Bereiche aufgeführt, in denen Grenzfälle aufgetreten sind:
- Das interne Tool zur Orchestrierung von Live-Migrationen für den Linode-Kundensupport und die Hardware-Betriebsteams musste entwickelt werden. Es ähnelte anderen bestehenden Tools, die wir zu der Zeit hatten und benutzten, war aber so unterschiedlich, dass ein großer Entwicklungsaufwand erforderlich war, um es zu erstellen:
- Dieses Tool muss automatisch die gesamte Hardwareflotte in einem Rechenzentrum betrachten und herausfinden, welcher Host das Ziel für jede live migrierte Linode sein sollte. Zu den relevanten Spezifikationen für diese Auswahl gehören der verfügbare SSD-Speicherplatz und die RAM-Zuweisungen.
- Der physische Prozessor des Zielrechners muss mit der ankommenden Linode kompatibel sein. Insbesondere kann eine CPU über Funktionen (auch als CPU-Flags bezeichnet) verfügen, die von der Software der Benutzer genutzt werden können. Ein solches Feature ist zum Beispiel aes, das eine hardwarebeschleunigte Verschlüsselung ermöglicht. Die CPU des Zielrechners für eine Live-Migration muss die CPU-Flags des Quellrechners unterstützen. Dies erwies sich als sehr komplexer Grenzfall, und der nächste Abschnitt beschreibt eine Lösung für dieses Problem.
- Sicherer Umgang mit Fehlern, einschließlich des Eingreifens des Endbenutzers oder des Verlusts des Netzwerks während der Live-Migration. Diese Fehlerfälle werden in einem späteren Abschnitt dieses Beitrags ausführlicher beschrieben.
- Mit den Änderungen an der Linode-Plattform Schritt zu halten, was ein fortlaufender Prozess ist. Für jede Funktion, die wir jetzt und in Zukunft auf Linodes unterstützen, müssen wir sicherstellen, dass die Funktion mit Live Migrations kompatibel ist. Diese Herausforderung wird am Ende dieses Beitrags beschrieben.
CPU-Flags
QEMU hat verschiedene Optionen, wie eine CPU dem Gastbetriebssystem präsentiert werden kann. Eine dieser Optionen besteht darin, die Modellnummer und die Merkmale der Host-CPU (auch als CPU-Flags bezeichnet) direkt an den Gast zu übergeben. Durch die Wahl dieser Option kann der Gast die volle unbelastete Leistung nutzen, die das KVM Virtualisierungssystem ermöglicht. Als KVM zum ersten Mal von Linode eingeführt wurde (was der Live-Migration vorausging), wurde diese Option gewählt, um die Leistung zu maximieren. Diese Entscheidung stellte jedoch später bei der Entwicklung von Live Migrations viele Herausforderungen dar.

In der Testumgebung für Live-Migrationen waren die Quell- und Zielhosts zwei identische Rechner. In der realen Welt ist unsere Hardwareflotte nicht zu 100 % identisch, und es gibt Unterschiede zwischen den Maschinen, die dazu führen können, dass unterschiedliche CPU-Flags vorhanden sind. Das ist wichtig, denn wenn ein Programm in das Betriebssystem der Linode geladen wird, stellt die Linode dem Programm CPU-Flags zur Verfügung, und das Programm lädt bestimmte Abschnitte der Software in den Speicher, um diese Flags zu nutzen. Wenn eine Linode live auf einen Zielrechner migriert wird, der diese CPU-Flags nicht unterstützt, stürzt das Programm ab. Dies kann zum Absturz des Gastbetriebssystems führen und einen Neustart der Linode zur Folge haben.
Wir haben drei Faktoren gefunden, die beeinflussen, wie die CPU-Flags eines Rechners den Gästen angezeigt werden:
- Es gibt geringfügige Unterschiede zwischen den CPUs, je nachdem, wann die CPU gekauft wurde. Eine CPU, die am Ende des Jahres gekauft wurde, kann andere Flags haben als eine, die am Anfang des Jahres gekauft wurde, je nachdem, wann die CPU-Hersteller neue Hardware herausbringen. Linode kauft ständig neue Hardware, um die Kapazität zu erhöhen, und selbst wenn das CPU-Modell für zwei verschiedene Hardware-Bestellungen das gleiche ist, können die CPU-Flags unterschiedlich sein.
- Verschiedene Linux-Kernel können unterschiedliche Flags an QEMU übergeben. Insbesondere kann der Linux-Kernel des Quellrechners einer Live-Migration andere Flags an QEMU weitergeben als der Linux-Kernel des Zielrechners. Die Aktualisierung des Linux-Kernels auf dem Quellrechner erfordert einen Neustart, so dass diese Diskrepanz nicht durch eine Aktualisierung des Kernels vor der Live-Migration behoben werden kann, da dies zu einer Ausfallzeit für die Linodes auf diesem Rechner führen würde.
- Ebenso können sich unterschiedliche QEMU-Versionen darauf auswirken, welche CPU-Flags angezeigt werden. Die Aktualisierung von QEMU erfordert auch einen Neustart des Rechners.
Daher mussten Live-Migrationen so implementiert werden, dass Programmabstürze aufgrund von CPU-Flag-Fehlern verhindert werden. Es sind zwei Optionen verfügbar:
- Wir könnten QEMU anweisen, die CPU-Flags zu emulieren. Dies würde dazu führen, dass Software, die früher schnell lief, jetzt langsam läuft, ohne dass man herausfinden kann, warum.
- Wir können eine Liste von CPU-Flags in der Quelle erstellen und sicherstellen, dass das Ziel dieselben Flaggen hat, bevor wir fortfahren. Dies ist zwar komplizierter, aber die Geschwindigkeit der Programme unserer Benutzer bleibt erhalten. Diese Option haben wir für Live-Migrationen implementiert.
Nachdem wir uns für den Abgleich von Quell- und Ziel-CPU-Flags entschieden hatten, lösten wir diese Aufgabe mit einem "Gürtel und Hosenträger"-Ansatz, der aus zwei verschiedenen Methoden bestand:
- Die erste Methode ist die einfachere von beiden. Alle CPU-Flags werden von der Quelle an die Zielhardware gesendet. Wenn die Zielhardware die neue qemu-Instanz einrichtet, prüft sie, ob sie mindestens alle Flags hat, die auf der Quell-Linode vorhanden waren. Wenn sie nicht übereinstimmen, wird die Live-Migration nicht fortgesetzt.
- Die zweite Methode ist viel komplizierter, aber sie kann fehlgeschlagene Migrationen verhindern, die durch nicht übereinstimmende CPU-Flags verursacht werden. Bevor eine Live-Migration eingeleitet wird, erstellen wir eine Liste von Hardware mit kompatiblen CPU-Flags. Dann wird ein Zielrechner aus dieser Liste ausgewählt.
Diese zweite Methode muss schnell durchgeführt werden und ist sehr komplex. In einigen Fällen müssen wir bis zu 226 CPU-Flags auf mehr als 900 Rechnern überprüfen. Das Schreiben all dieser 226 CPU-Flag-Prüfungen wäre sehr schwierig, und sie müssten gewartet werden. Dieses Problem wurde schließlich durch eine erstaunliche Idee des Linode-Gründers, Chris Aker, gelöst.
Die Grundidee war, eine Liste aller CPU-Flags zu erstellen und diese als binäre Zeichenkette darzustellen. Dann kann die bitweise und-Operation verwendet werden, um die Zeichenketten zu vergleichen. Um diesen Algorithmus zu demonstrieren, beginne ich mit einem einfachen Beispiel wie folgt. Betrachten Sie diesen Python Code, der zwei Zahlen mit bitweise und vergleicht:
>>> 1 & 1
1
>>> 2 & 3
2
>>> 1 & 3
1Um zu verstehen, warum die bitweise und-Operation zu diesen Ergebnissen führt, ist es hilfreich, die Zahlen in binärer Form darzustellen. Untersuchen wir die bitweise und-Operation für die Zahlen 2 und 3, dargestellt in binärer Form:
>>> # 2: 00000010
>>> # &
>>> # 3: 00000011
>>> # =
>>> # 2: 00000010Die bitweise und-Operation vergleicht die binären Ziffern oder Bits der beiden verschiedenen Zahlen. Einstieg mit der Ziffer ganz rechts in den obigen Zahlen und gehen Sie dann nach links:
- Die ganz rechten/ersten Bits von 2 und 3 sind 0 bzw. 1. Die bitweise Verknüpfung und das Ergebnis für
0 & 1ist 0. - Das zweite Bit ganz rechts von 2 und 3 ist bei beiden Zahlen 1. Das bitweise und Ergebnis für
1 & 1ist 1. - Alle anderen Bits für diese Zahlen sind 0, und das bitweise und Ergebnis für 0 & 0 ist 0.
Die binäre Darstellung für das vollständige Ergebnis lautet dann 00000010was gleich 2 ist.
Bei Live-Migrationen wird die vollständige Liste der CPU-Flags als binäre Zeichenfolge dargestellt, wobei jedes Bit ein einzelnes Flag darstellt. Wenn das Bit 0 ist, ist das Flag nicht vorhanden, und wenn das Bit 1 ist, ist das Flag vorhanden. So kann beispielsweise ein Bit dem aes-Flag entsprechen und ein anderes Bit dem mmx-Flag. Die spezifischen Positionen dieser Flaggen in der binären Darstellung werden gepflegt, dokumentiert und von den Maschinen in unseren Rechenzentren gemeinsam genutzt.
Die Pflege dieser Listendarstellung ist viel einfacher und effizienter als die Pflege einer Reihe von if-Anweisungen, die hypothetisch das Vorhandensein eines CPU-Flags prüfen würden. Nehmen wir zum Beispiel an, es gäbe insgesamt 7 CPU-Flags, die verfolgt und überprüft werden müssten. Diese Flags könnten in einer 8-Bit-Zahl gespeichert werden (wobei ein Bit für zukünftige Erweiterungen übrig bliebe). Ein Beispielstring könnte wie folgt aussehen 00111011wobei das Bit ganz rechts anzeigt, dass aes aktiviert ist, das zweite Bit ganz rechts zeigt an, dass mmx aktiviert ist, das dritte Bit zeigt an, dass ein anderes Flag deaktiviert ist, usw.
Wie im nächsten Codeschnipsel gezeigt, können wir dann sehen, welche Hardware diese Kombination von Flags unterstützt und alle Übereinstimmungen in einem Zyklus zurückgeben. Hätten wir eine Reihe von if-Anweisungen verwendet, um diese Übereinstimmungen zu berechnen, wäre eine viel höhere Anzahl von Zyklen erforderlich, um dieses Ergebnis zu erzielen. Bei einem Beispiel für eine Live-Migration, bei der 4 CPU-Flags auf dem Quellcomputer vorhanden waren, würde es 203.400 Zyklen dauern, um passende Hardware zu finden.
Der Live-Migrationscode führt eine bitweise und-Operation an den CPU-Merkerzeichenfolgen auf dem Quell- und dem Zielcomputer durch. Wenn das Ergebnis gleich dem CPU-Flag-String des Quellrechners ist, ist der Zielrechner kompatibel. Betrachten Sie diesen Python Codeausschnitt:
>>> # The b'' syntax below represents a binary string
>>>
>>> # The s variable stores the example CPU flag
>>> # string for the source:
>>> s = b'00111011'
>>> # The source CPU flag string is equivalent to the number 59:
>>> int(s.decode(), 2)
59
>>>
>>> # The d variable stores the example CPU flag
>>> # string for the source:
>>> d = b'00111111'
>>> # The destination CPU flag string is equivalent to the number 63:
>>> int(d.decode(), 2)
63
>>>
>>> # The bitwise and operation compares these two numbers:
>>> int(s.decode(), 2) & int(d.decode(), 2) == int(s.decode(), 2)
True
>>> # The previous statement was equivalent to 59 & 63 == 59.
>>>
>>> # Because source & destination == source,
>>> # the machines are compatibleBeachten Sie, dass im obigen Codeschnipsel das Ziel mehr Flags unterstützt als die Quelle. Die Maschinen werden als kompatibel angesehen, da alle CPU-Flags der Quelle auf dem Ziel vorhanden sind, was durch die bitweise und-Operation sichergestellt wird.
Die Ergebnisse dieses Algorithmus werden von unserem internen Tooling verwendet, um eine Liste kompatibler Hardware zu erstellen. Diese Liste wird unserem Kundensupport und unseren Hardware-Operations-Teams angezeigt. Diese Teams können das Tooling nutzen, um verschiedene Vorgänge zu orchestrieren:
- Das Tool kann verwendet werden, um die beste kompatible Hardware für eine bestimmte Linode auszuwählen.
- Wir können eine Live-Migration für eine Linode einleiten, ohne einen Zielort festzulegen. Die beste kompatible Hardware im selben Rechenzentrum wird automatisch ausgewählt und die Migration beginnt.
- Wir können Live-Migrationen für alle Linodes auf einem Host als eine einzige Aufgabe initiieren. Diese Funktion wird vor der Durchführung von Wartungsarbeiten an einem Host verwendet. Das Tool wählt automatisch Ziele für alle Linodes aus und orchestriert Live-Migrationen für jede Linode.
- Wir können eine Liste mit mehreren Maschinen angeben, die gewartet werden müssen, und das Tool orchestriert automatisch Live-Migrationen für alle Linodes auf den Hosts.
Es wird viel Entwicklungszeit darauf verwendet, dass Software "einfach funktioniert".
Misserfolgsfälle
Ein Merkmal, über das bei Software nicht oft gesprochen wird, ist der Umgang mit Fehlern. Software soll "einfach funktionieren". Ein Großteil der Entwicklungszeit wird darauf verwendet, dass Software "einfach funktioniert", und das war auch bei Live Migrations der Fall. Es wurde viel Zeit damit verbracht, über alle Möglichkeiten nachzudenken, wie dieses Tool nicht funktionieren könnte, und wie man mit diesen Fällen umgehen könnte. Hier sind einige dieser Szenarien und wie sie angegangen werden:
- Was passiert, wenn ein Kunde auf eine Funktion seiner Linode von der Website aus zugreifen möchte? Cloud Manager? Zum Beispiel kann ein Benutzer die Linode-Instanz neu starten oder ein Blockspeicher-Volume an sie anhängen.
- Antwort: Der Kunde hat die Möglichkeit, dies zu tun. Die Live-Migration wird unterbrochen und kann nicht fortgesetzt werden. Diese Lösung ist angemessen, da die Live-Migration zu einem späteren Zeitpunkt erneut versucht werden kann.
- Was passiert, wenn die Ziel-Linode nicht bootet?
- Antwort: Informieren Sie die Quellhardware, und entwickeln Sie die internen Tools so, dass sie automatisch eine andere Hardware im Rechenzentrum auswählen. Informieren Sie auch das Betriebsteam, damit es die Hardware des ursprünglichen Ziels untersuchen kann. Dies ist in der Produktion bereits vorgekommen und wurde von unserer Live-Migrations-Implementierung bewältigt.
- Was passiert, wenn Sie das Netzwerk während der Migration verlieren?
- Antwort: Überwachen Sie den Fortschritt der Live-Migration selbstständig und brechen Sie die Live-Migration ab, wenn sie in der letzten Minute keine Fortschritte gemacht hat, und informieren Sie das Betriebsteam. Dies ist außerhalb einer Testumgebung noch nicht vorgekommen, aber unsere Implementierung ist auf dieses Szenario vorbereitet.
- Was passiert, wenn der Rest des Internets herunterfährt, aber die Quell- und Zielhardware noch läuft und kommuniziert und die Quell- oder Ziel-Linode normal läuft?
- Antwort: Wenn sich die Live-Migration nicht im kritischen Bereich befindet, stoppen Sie die Live-Migration. Versuchen Sie es dann später erneut.
- Wenn Sie sich im kritischen Bereich befinden, setzen Sie die Live-Migration fort. Dies ist wichtig, da die Quell-Linode angehalten ist und die Ziel-Linode gestartet werden muss, damit der Betrieb wieder aufgenommen werden kann.
- Diese Szenarien wurden in der Testumgebung nachgebildet, und das vorgeschriebene Verhalten erwies sich als die beste Vorgehensweise.
Mit den Veränderungen Schritt halten
Nach Hunderttausenden von erfolgreichen Live-Migrationen wird manchmal die Frage gestellt: "Wann ist Live-Migrationen abgeschlossen?" Da es sich bei Live Migrations um eine Technologie handelt, deren Einsatz sich im Laufe der Zeit ausweitet und die ständig weiterentwickelt wird, ist es nicht unbedingt einfach, das Ende des Projekts zu bestimmen. Eine Möglichkeit, diese Frage zu beantworten, besteht darin, zu überlegen, wann der Großteil der Arbeit für dieses Projekt abgeschlossen ist. Die Antwort lautet: Bei zuverlässiger, verlässlicher Software ist die Arbeit noch lange nicht getan.
Wenn im Laufe der Zeit neue Funktionen für Linodes entwickelt werden, muss daran gearbeitet werden, die Kompatibilität mit Live Migrations für diese Funktionen sicherzustellen. Bei der Einführung einiger Funktionen muss keine neue Entwicklungsarbeit an Live Migrations geleistet werden, und wir müssen nur testen, ob Live Migrations noch wie erwartet funktioniert. Bei anderen Funktionen wird die Kompatibilität mit Live Migrations bereits zu einem frühen Zeitpunkt in der Entwicklung der neuen Funktion als Aufgabe markiert.
Wie bei allem in der Softwarebranche gibt es immer wieder bessere Implementierungsmethoden, die durch Forschung entdeckt werden. Es könnte zum Beispiel sein, dass ein modularer Ansatz für die Integration von Live Migrations langfristig weniger Wartungsaufwand bedeutet. Oder es ist möglich, dass die Einbindung der Live Migrations-Funktionalität in den Code auf niedrigerer Ebene dazu beiträgt, dass sie für künftige Linode-Funktionen sofort einsatzbereit ist. Unsere Teams ziehen alle diese Optionen in Betracht, und die Werkzeuge, die die Linode-Plattform antreiben, sind lebendige Gebilde, die sich ständig weiterentwickeln werden.




Kommentare