






Dieser Beitrag ist Teil unserer Reihe Cloud Computing Foundations. Vertiefen Sie Ihre Kenntnisse in unserem Zertifizierungskurs Einführung in Cloud Computing .
Vielleicht erinnern Sie sich an Datenbanken aus unserem Artikel über Cloud-Ressourcentypen.
Lassen Sie uns vorsichtshalber einen Blick darauf werfen.
Eine Datenbank ist eine Sammlung strukturierter Informationen, die auf einem Server gespeichert und bei Bedarf einfach abgerufen werden kann, ähnlich wie eine Bibliothek. Cloud-Datenbanken werden von Drittanbietern gehostet und bieten Skalierbarkeit und Notfallwiederherstellungsfunktionen und werden in der Regel von einem Datenbankmanagementsystem (DBMS) gesteuert. Datenbanken werden von allen genutzt, die Daten abrufen müssen, insbesondere von denen, die mit großen Datenmengen arbeiten.
Es ist wichtig zu beachten, dass eine Sammlung von Daten und eine Schnittstelle für diese Daten zwei verschiedene Dinge sind. Eine App zum Gassigehen mit Hund könnte beispielsweise Daten sammeln und speichern, aber ein DBMS fungiert als das System, das mit der Datenbank und jedem anderen Dienst, der die Daten benötigt, kommunizieren kann und als Schnittstelle fungiert.
Es gibt zwar verschiedene Arten von Datenbankverwaltungssystemen, aber es gibt zwei gängige Typen: relationale (SQL) und nicht-relationale (NoSQL).
Eine relationale Datenbank ist strukturiert, und die enthaltenen Daten sind in Tabellen organisiert. Die Daten stehen zueinander in Beziehung. NoSQL (nicht-relationale Datenbanken) sind dokumentenorientiert, und die Daten sind nicht unbedingt miteinander verbunden.
Werfen wir einen Blick auf diese beiden Arten von Datenbanken.
SQL-Datenbanken
Structured Query Language (SQL) ist eine Programmiersprache, die für die Bearbeitung von Daten in einem relationalen Datenbankmanagementsystem (RDBMS) verwendet wird. Das RDBMS ist die Software, die wir zur Verwaltung, Speicherung, Abfrage und zum Abruf von Daten aus der Datenbank verwenden.
Eine relationale Datenbank zeichnet sich dadurch aus, dass zwischen verschiedenen Daten in mehreren Tabellen (in denen die Daten gespeichert werden) verschiedene Beziehungen hergestellt werden können.
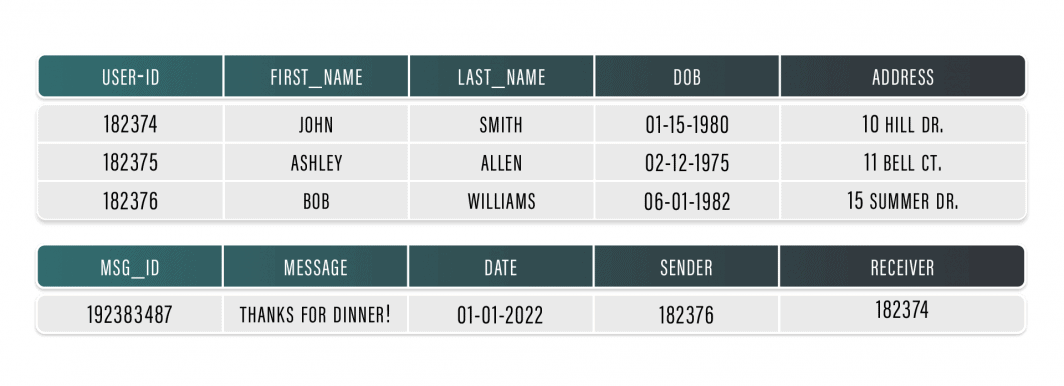
Werfen Sie einen Blick auf die obige Tabelle. Angenommen, eine Webanwendung für soziale Medien verfügt über eine einzige Tabelle in einer Datenbank, in der die ID, der Name und das Geburtsdatum eines Benutzers gespeichert sind. Da jede Benutzer-ID eindeutig ist, kann sie verwendet werden, um Benutzerdaten in einer Tabelle mit einer anderen Tabelle zu verbinden, die den Nachrichtenverlauf des Benutzers enthält. Diese Art von Beziehung wird als Eins-zu-viele-Beziehung bezeichnet, da ein Benutzer mehrere Nachrichten mit seiner Profil-ID verknüpft haben kann. Allerdings können Nachrichten nicht von mehr als einer Profil-ID gesendet werden.
SQL hilft bei der Verwaltung und Manipulation von Daten in einer relationalen Datenbank. Es ermöglicht das Erstellen, Ändern und Abrufen von Daten aus Tabellen innerhalb der Datenbank sowie die Verwaltung der Beziehungen zwischen verschiedenen Tabellen.
Sie haben vielleicht schon von PostgreSQL und MySQL gehört. Dies sind zwei beliebte RDBMS, die beide SQL verwenden. Werfen wir einen kurzen Blick darauf, was sie tun und wie sie sich unterscheiden.
PostgreSQL (oft nur Postgres genannt) ist bekannt für seine Skalierbarkeit und Genauigkeit und dafür, dass es komplexe Abfragen und große Datensätze verarbeiten kann. PostgreSQL ist auch für seine fortschrittlichen Funktionen bekannt, wie z. B. die Unterstützung für erweiterte Indizierung und Volltextsuche, die es zu einer beliebten Wahl für Anwendungen machen, die eine erweiterte Datenanalyse erfordern.
MySQL hingegen ist für seine Geschwindigkeit, Flexibilität, Skalierbarkeit und Benutzerfreundlichkeit bekannt. Es wird häufig für Webanwendungen verwendet, die einen schnellen Lese-/Schreibzugriff auf Daten erfordern, wie z. B. Content-Management-Systeme oder eCommerce-Plattformen.
Ein Hauptunterschied zwischen den beiden Systemen besteht darin, dass sie sich in ihrer Herangehensweise an die Datenintegrität unterscheiden. PostgreSQL ist dafür bekannt, dass es die Datenintegrität strikt durchsetzt. Es legt mehr Wert darauf, dass die Daten konsistent und genau sind. MySQL hingegen ist dafür bekannt, daß es nachsichtiger ist und eine größere Flexibilität bei der Datenverarbeitung zuläßt. Dies spricht auch für die Geschwindigkeit, für die MySQL bekannt ist. Jedes System hat seine Stärken und Grenzen, wie die meisten Werkzeuge auch.
Tauchen wir ein in NoSQL-Datenbanken.
NoSQL-Datenbanken
NoSQL-Datenbanken verwenden ein nicht-relationales Datenmodell zum Speichern und Abrufen von Daten. Im Gegensatz zu relationalen Datenbanken, die Tabellen mit festen Spalten und Zeilen verwenden, können NoSQL-Datenbanken Daten in verschiedenen Formaten speichern, darunter Schlüssel-Wert-, Dokument-, Spaltenfamilien- und Diagrammformate.
Einer der Hauptvorteile von NoSQL-Datenbanken ist, dass sie flexibler sind als SQL-Datenbanken. Es ist einfach, Daten hinzuzufügen oder zu ändern, ohne die Datenbankstruktur wesentlich ändern zu müssen. Dadurch sind NoSQL-Datenbanken ideal für die Speicherung großer, unstrukturierter Datensätze.
NoSQL-Datenbanken sind skalierbar und können mit großen Datenmengen und hohem Datenverkehr umgehen. Viele
Schauen wir uns die gängigen Typen von NoSQL-Datenbanken an.
Key-Value-Speicher
Schlüsselwertspeicher werden häufig verwendet, wenn schnell und effizient auf Daten zugegriffen werden muss. Aufgrund ihrer einfachen Struktur sind sie sehr schnell und leicht skalierbar, was sie zu einer guten Wahl für Anwendungen mit hohen Leistungsanforderungen macht.
Dokumentenspeicher
Dokumentenspeicher ermöglichen eine flexible Datenmodellierung und sind daher ideal für Content-Management-Systeme, Social-Media-Plattformen und E-Commerce-Sites.
Säulen-Familien-Geschäfte
Diese Datenbanken speichern Daten in Spalten und nicht in Zeilen, was eine effiziente Speicherung und Abfrage großer Datenmengen ermöglicht. Spaltenspeicher werden häufig für Analysen und Data Warehousing verwendet.
Graph-Datenbanken
In Graphdatenbanken werden Daten als Knoten und Kanten gespeichert, was sie ideal für die Speicherung und Analyse komplexer, miteinander verbundener Datensätze macht. Graphdatenbanken werden häufig für soziale Netzwerke, Empfehlungsmaschinen und Betrugserkennung verwendet.
Nachdem wir nun die verschiedenen Arten von Datenbanken kennengelernt haben, wollen wir uns ansehen, wie Datenbanken in der realen Welt verwendet werden.
Wie werden Datenbanken verwendet?
Datenbanken ermöglichen es uns, große Datenmengen an einem Ort zu speichern. Da die meisten Unternehmen eine Online-Präsenz haben, werden Datenbanken in fast allen denkbaren Bereichen eingesetzt.
Nehmen wir an, wir haben eine eCommerce-Website. Wir können die Bestellhistorie der Kunden, Produktdetails und Kundendaten an einem Ort speichern. Oder nehmen wir unsere Handys. Sie verwenden Datenbanken, um unsere Kontaktliste zu speichern. Datenbanken sind durchsuchbar und sortierbar, so dass die benötigten Daten schnell und einfach gefunden werden können. Wenn wir zum Beispiel nach einer E-Mail im Posteingang suchen, fragen wir eine Datenbank ab, um die gewünschte Nachricht zu finden.
Erwerben Sie die Fähigkeiten, um im Cloud Computing erfolgreich zu sein, indem Sie unseren Zertifizierungskurs Introduction to Cloud Computing besuchen.





Kommentare