






Je nachdem, wen man fragt, bedeutet der KI-Boom, dass der Zugriff auf leistungsstarke GPUs in der Cloud ein Kinderspiel ist - oder fast unmöglich. Das Problem besteht darin, die richtige GPU beim richtigen Anbieter zu finden, ohne zu viel Geld für Hardware-Ressourcen auszugeben, die man realistischerweise nicht braucht und die nur dann zur Verfügung stehen, wenn man sie braucht, ohne dass man sich an Prepaid-Reservierungen oder teure Verträge binden muss.
Das ist eine große Aufgabe, und wir haben die Herausforderung gerne angenommen. Nach strengen Tests und Optimierungen sind die neuen GPUs von Akamai jetzt für alle Kunden verfügbar. Angetrieben von den NVIDIA RTX 4000 Ada Generation Karten, sind diese GPUs für Medienanwendungen optimiert, aber auch für eine Reihe von Arbeitslasten und Anwendungen geeignet. Die RTX 4000 Ada Generation-Tarife beginnen bei 0,52 US-Dollar pro Stunde für 1 GPU, 4 CPUs und 16 GB RAM in sechs Core-Compute-Regionen:
- Chicago, IL
- Seattle, WA
- Frankfurt, DE Erweiterung
- Paris, FR
- Osaka, JP
- Singapur, SG Erweiterung
- Mumbai, IN Expansion (demnächst!)
Highlights des Anwendungsfalls
Im Rahmen unseres Betaprogramms konnten unsere Kunden und unabhängigen Softwareanbieter (ISV) unsere neuen Grafikprozessoren testen, unter anderem für wichtige Anwendungsfälle, von denen wir wussten, dass sie von den von uns entwickelten GPU Planspezifikationen profitieren würden: Medientranskodierung und leichtgewichtige KI.
Der in der Cloud gehostete Encoder Cambria Stream von Capella Systems übernimmt die Live-Codierung, Werbeeinblendung, Verschlüsselung und Verpackung für die anspruchsvollsten Live-Events. Es bedarf der richtigen Technologie und Konfiguration hinter den Kulissen, damit Endnutzer live gestreamte Veranstaltungen von allen verschiedenen Geräten und über Netzwerkinfrastrukturen hinweg ansehen können.
"Mit der neuen NVIDIA RTX 4000 Ada Generation Dual GPU von Akamai kann ein einziger Cambria Stream bis zu 25 Kanäle mit Multi-Layer-Encoding gleichzeitig verarbeiten, was die Gesamtrechenkosten im Vergleich zu CPU-basiertem Encoding deutlich reduziert."
Lesen Sie die vollständige Pressemitteilung.
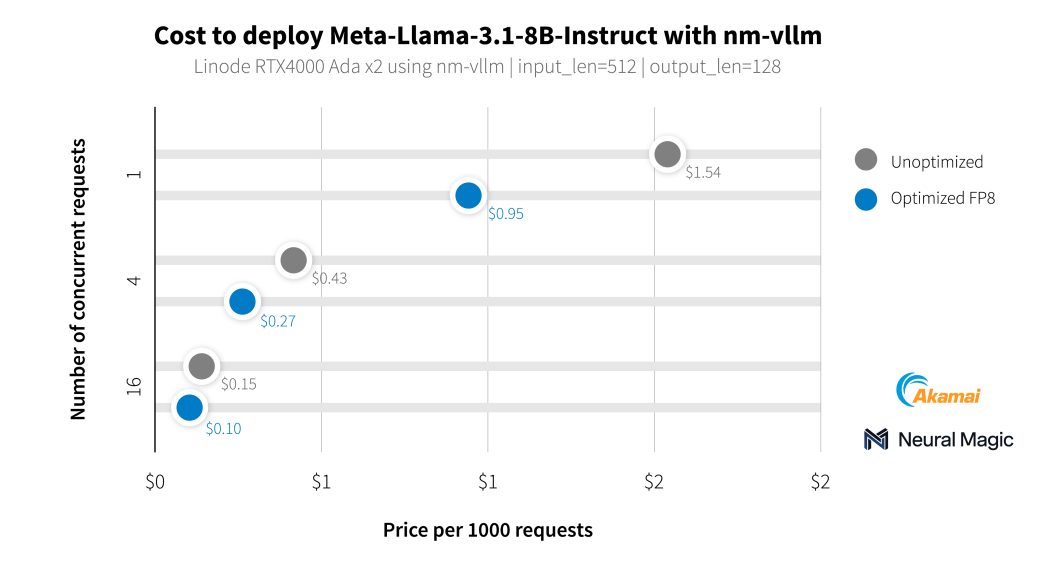
Zusätzlich zu unseren Medienkunden haben wir mit Neural Magic zusammengearbeitet, um die KI-Fähigkeiten unserer neuen GPUs mit nm-vllm, ihrer unternehmensfähigen LLM-Serving-Engine, zu testen. Sie nutzten ihr Open-Source-Komprimierungs-Toolkit für LLMs, LLM Compressor, um wesentlich effizientere Bereitstellungen mit einer Genauigkeit von 99,9 % zu erzielen. Beim Testen der neuesten Llama 3.1-Modelle nutzte Neural Magic seine Software-Optimierungen, um mit RTX 4000-GPUs durchschnittliche Kosten von 0,27 $ pro 1.000 Zusammenfassungsanfragen zu erzielen, was einer Kostenreduzierung von 60 % im Vergleich zum Referenzeinsatz entspricht.
Erste Schritte
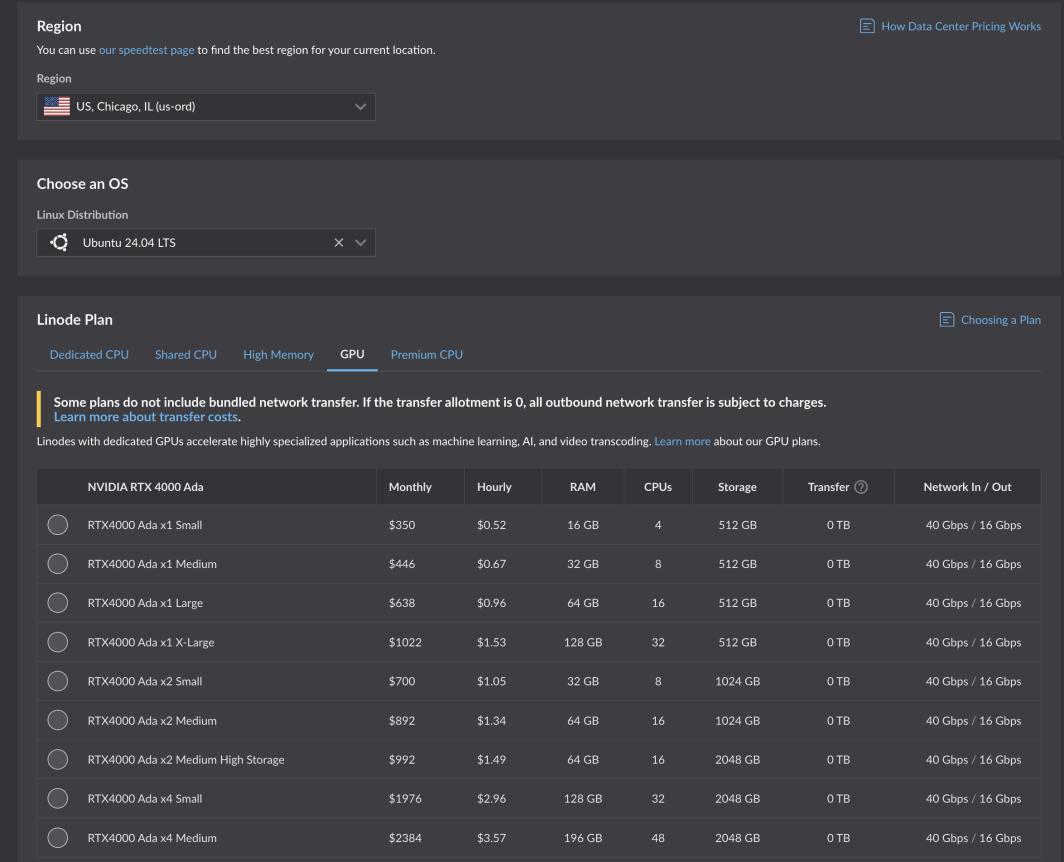
Wenn Sie bereits ein Konto haben, können Sie sofort loslegen. Wählen Sie einfach eine unterstützte Region aus und navigieren Sie zur Registerkarte GPU in der Tabelle der Recheninstanzpläne.
Starten Sie mit unserer Dokumentation.
Entwickler, die Geschäftsanwendungen erstellen und verwalten, sollten sich an unsere Cloud-Beraterteams wenden.
Hinweis: Die Nutzung von Akamai GPU Instanzen erfordert eine positive Abrechnungshistorie für Ihr Konto, ohne Promo-Codes. Wenn Sie nicht in der Lage sind, die Instanzen bereitzustellen und Zugang zu GPU benötigen, öffnen Sie ein Support-Ticket.





Kommentare