
Wordpress node almost ready...
pre-sales advice
With our site activity peaking in recent weeks we've now outgrown dreamhost and they're killing php5 processes all over the place to "manage" the load, so I really need to move soon.
However, before that happens I'm keen for advice on tuning and load testing. My setup is CentOS 5.4 running Webmin and Virtualmin. This has eased the installation and setup of Apache, MySQL and PHP to power my Wordpress and smf instance.
Currently the linode is sitting there mostly idle, and it's got 113 processes running, does this seem like a lot? Additionally it is using 250MB ram and 143MB virtual ram… seems like a lot for an idle box. I've attached a screenshot of the status page.
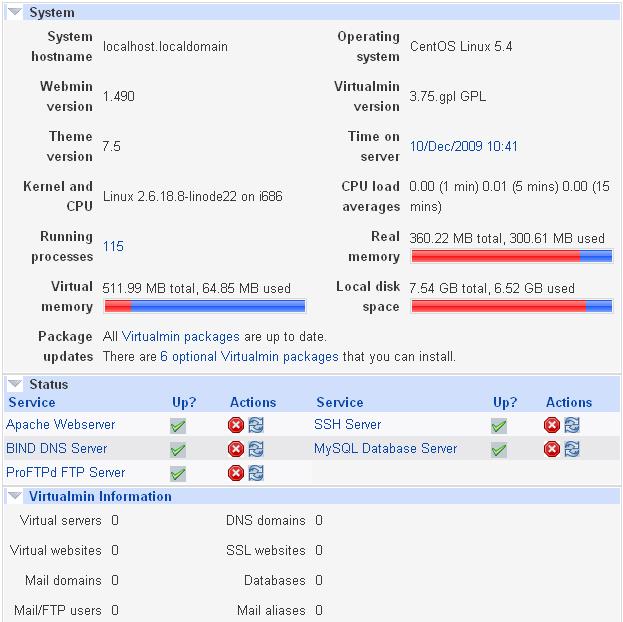 ~~
~~
> ID Owner Started Command
1 root Dec08 init [3]
2 root Dec08 [migration/0]
3 root Dec08 [ksoftirqd/0]
4 root Dec08 [migration/1]
5 root Dec08 [ksoftirqd/1]
6 root Dec08 [migration/2]
7 root Dec08 [ksoftirqd/2]
8 root Dec08 [migration/3]
9 root Dec08 [ksoftirqd/3]
10 root Dec08 [events/0]
11 root Dec08 [events/1]
12 root Dec08 [events/2]
13 root Dec08 [events/3]
14 root Dec08 [khelper]
15 root Dec08 [kthread]
17 root Dec08 [xenwatch]
18 root Dec08 [xenbus]
27 root Dec08 [kblockd/0]
28 root Dec08 [kblockd/1]
29 root Dec08 [kblockd/2]
30 root Dec08 [kblockd/3]
31 root Dec08 [cqueue/0]
32 root Dec08 [cqueue/1]
33 root Dec08 [cqueue/2]
34 root Dec08 [cqueue/3]
36 root Dec08 [kseriod]
120 root Dec08 [pdflush]
121 root Dec08 [pdflush]
122 root Dec08 [kswapd0]
123 root Dec08 [aio/0]
124 root Dec08 [aio/1]
125 root Dec08 [aio/2]
126 root Dec08 [aio/3]
128 root Dec08 [jfsIO]
129 root Dec08 [jfsCommit]
130 root Dec08 [jfsCommit]
131 root Dec08 [jfsCommit]
132 root Dec08 [jfsCommit]
133 root Dec08 [jfsSync]
134 root Dec08 [xfslogd/0]
135 root Dec08 [xfslogd/1]
136 root Dec08 [xfslogd/2]
137 root Dec08 [xfslogd/3]
138 root Dec08 [xfsdatad/0]
139 root Dec08 [xfsdatad/1]
140 root Dec08 [xfsdatad/2]
141 root Dec08 [xfsdatad/3]
750 root Dec08 [net_accel/0]
751 root Dec08 [net_accel/1]
752 root Dec08 [net_accel/2]
753 root Dec08 [net_accel/3]
761 root Dec08 [kpsmoused]
764 root Dec08 [kcryptd/0]
765 root Dec08 [kcryptd/1]
766 root Dec08 [kcryptd/2]
767 root Dec08 [kcryptd/3]
768 root Dec08 [kmirrord]
777 root Dec08 [kjournald]
802 root Dec08 [kauditd]
835 root Dec08 /sbin/udevd -d
1172 root 09:48 /usr/sbin/httpd
1174 apache 09:48 /usr/sbin/httpd
1175 apache 09:48 /usr/sbin/httpd
1176 apache 09:48 /usr/sbin/httpd
1177 apache 09:48 /usr/sbin/httpd
1178 apache 09:48 /usr/sbin/httpd
1179 apache 09:48 /usr/sbin/httpd
1180 apache 09:48 /usr/sbin/httpd
1181 apache 09:48 /usr/sbin/httpd
1182 apache 09:48 /usr/sbin/httpd
1214 apache 09:49 /usr/sbin/httpd
1812 apache 10:34 /usr/sbin/httpd
1816 apache 10:34 /usr/sbin/httpd
1817 apache 10:34 /usr/sbin/httpd
2151 root Dec08 /sbin/dhclient -1 -q -lf /var/lib/dhclient/dhclient-eth0.leases -pf /var/run/dhc …
2189 root Dec08 syslogd -m 0
2192 root Dec08 klogd -x
2214 named Dec08 /usr/sbin/named -u named
2233 dbus Dec08 dbus-daemon --system
2266 root Dec08 /usr/sbin/sshd
32007 root 08:12 sshd: root@pts/0
32009 root 08:12 -bash
2301 root Dec08 /bin/sh /usr/bin/mysqld_safe --datadir=/var/lib/mysql --socket=/var/lib/mysql/my …
2351 mysql Dec08 /usr/libexec/mysqld --basedir=/usr --datadir=/var/lib/mysql --user=mysql --pid-f …
2418 root Dec08 /usr/libexec/postfix/master
341 postfix 09:09 pickup -l -t fifo -u
2423 postfix Dec08 qmgr -l -t fifo -u
2430 nobody Dec08 proftpd: (accepting connections)
2451 root Dec08 crond
32675 root 09:00 crond
32680 root 09:00 /bin/bash /usr/share/clamav/freshclam-sleep
32686 root 09:00 sleep 10493
2459 root Dec08 /usr/sbin/saslauthd -m /var/run/saslauthd -a pam
2460 root Dec08 /usr/sbin/saslauthd -m /var/run/saslauthd -a pam
2462 root Dec08 /usr/sbin/saslauthd -m /var/run/saslauthd -a pam
2463 root Dec08 /usr/sbin/saslauthd -m /var/run/saslauthd -a pam
2464 root Dec08 /usr/sbin/saslauthd -m /var/run/saslauthd -a pam
2479 mailman Dec08 /usr/bin/python /usr/lib/mailman/bin/mailmanctl -s -q start
2488 mailman Dec08 /usr/bin/python /usr/lib/mailman/bin/qrunner --runner=ArchRunner:0:1 -s
2489 mailman Dec08 /usr/bin/python /usr/lib/mailman/bin/qrunner --runner=BounceRunner:0:1 -s
2490 mailman Dec08 /usr/bin/python /usr/lib/mailman/bin/qrunner --runner=CommandRunner:0:1 -s
2491 mailman Dec08 /usr/bin/python /usr/lib/mailman/bin/qrunner --runner=IncomingRunner:0:1 -s
2492 mailman Dec08 /usr/bin/python /usr/lib/mailman/bin/qrunner --runner=NewsRunner:0:1 -s
2493 mailman Dec08 /usr/bin/python /usr/lib/mailman/bin/qrunner --runner=OutgoingRunner:0:1 -s
2494 mailman Dec08 /usr/bin/python /usr/lib/mailman/bin/qrunner --runner=VirginRunner:0:1 -s
2495 mailman Dec08 /usr/bin/python /usr/lib/mailman/bin/qrunner --runner=RetryRunner:0:1 -s
2496 root Dec08 /usr/bin/perl /usr/libexec/usermin/miniserv.pl /etc/usermin/miniserv.conf
2501 root Dec08 /usr/bin/perl /usr/libexec/webmin/miniserv.pl /etc/webmin/miniserv.conf
1958 root 10:43 /usr/libexec/webmin/proc/index_tree.cgi
2504 root Dec08 /sbin/mingetty tty1
I note that mailman is running but I have no requirement for mail from this server. I can kill the process but it just comes back after a reboot.
Any advice would be most appreciated, I plan to get some users to do a load test this evening.
Btw I'm running the wp-super cache and the node url is temporarily
Cheers,
Moses.~~
37 Replies
But if you don't need (sending/receiving) mail, then you should deactivate postfix and especially clamav which is a resource hog (well, at least if used through amavis). If I'm not mistaken you also don't need saslauth and I'm guessing mailman. Although, I don't know if CentOS requires active postfix for local notifications delivery? Also, I don't know Linode's CentOS image, but afaik "vanilla" CentOS installation comes with a lot of unnecessary thingies like bluetooth etc… Oh, and you don't really need Bind (named).
Unless, as I said, it is all required by Webmin, and iirc it is.
Just for comparison, my Gentoo node hosting a few low traffic sites (up to a hundred thousand hits per month and a few thousand email transactions, in total) on lighttpd, php (3 processes per site), postgresql, postfix, dovecot, spamassassin, vsftpd, ssh, memcached, rarely exceeds 100MB (and then only due spamd bloat). Upon boot, memory usage is around 70MB.
Because Apache is a hog an IMHO should be avoided unless you require modules not available under other webservers, or per directory .htaccess (in short, if you're not providing a shared hosting service), and Webmin may be cute clicky-clicky config-fest but in two years of my experience in running a VPS, I never really needed it. It is maybe useful for administering a number of domains, if cPanel is too expensive.
I prefer gentoo, install only what I need, configure it per my liking and call it a day. I have my own set of tools and scripts for easy administration and ready-made config files for services that I use.
But that's me. YMMV.
That comparison is very interesting, it's good to hear real world numbers on the resources that a well tuned site will require. Alas, I'm new to VPS hosting and my site is not overly busy (around 3000 hits to the blog and 6000 hits to the forum per day).
I went with webmin as the clicky admin interface is great for my sanity as I learn linux, and I'm hoping performance will be sustainable for the short to medium term with the current setup. By the time I get my head around the full barebones power of a VPS and then switch over to an optimised instance.
Given these traffic estimates (actually they're our busiest days on record), if I disable/uninstall clamav, postfix, Bind, saslauth, and mailman, then tell apache behave would this be a viable platform for my needs?
I don't know if I really require Apache, though I do need mod_rewrite to run the permalinks in wordpress. Should I be looking to a lighter web server from the start, or perhaps make that the first thing to optimise when performance suffers.
Finally, are there any quick pointers on how to remove the bloatware?
Cheers,
Moses.
 ~~http://www.greenandgoldrugby.com/upload/startup.JPG
~~http://www.greenandgoldrugby.com/upload/startup.JPG
For now I've disabled mailman, named (BIND) and saslauthd. Any others I can get rid of?~~
$ free -m
total used free shared buffers cached
Mem: 348 333 15 0 3 219
-/+ buffers/cache: 109 238
Swap: 127 26 101
On the "Mem:" line, it says I'm using 333MB of RAM… however, if you look at the line after that (which subtracts cached stuff), I'm only using 109MB! For some odd reason, most tools that display memory usage like to display the heart-attack total. I believe this is a vast conspiracy by memory manufacturers, but I digress.
This page has a good explanation of the whole thing: http://www.linuxatemyram.com/
these two changes
> Two tweaks to reduce memory consumption:
1) If not needed, disable innodb and berkley database by adding the following code to /etc/my.cnf in the [mysqld] section and reboot mysql
skip-innodb
skip-bdb
2) Reduce Apache's memory usage by adding the following to httpd.conf
MaxSpareServers 1
MinSpareServers 1
StartServers 1
Webmin now reports that 86.08MB RAM is now being used
> > free -m
total used free shared buffers cached
Mem: 360 177 182 0 7 81
-/+ buffers/cache: 89 271
Swap: 511 0 511
@Moses:
For now I've disabled mailman, named (BIND) and saslauthd. Any others I can get rid of?
I'm running CentOS 5.3, and have these services enabled:
$ chkconfig --list | grep 3:on
atd 0:off 1:off 2:off 3:on 4:on 5:on 6:off
auditd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
crond 0:off 1:off 2:on 3:on 4:on 5:on 6:off
haldaemon 0:off 1:off 2:off 3:on 4:on 5:on 6:off
httpd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
ip6tables 0:off 1:off 2:on 3:on 4:on 5:on 6:off
iptables 0:off 1:off 2:on 3:on 4:on 5:on 6:off
irqbalance 0:off 1:off 2:on 3:on 4:on 5:on 6:off
kudzu 0:off 1:off 2:off 3:on 4:on 5:on 6:off
mcstrans 0:off 1:off 2:on 3:on 4:on 5:on 6:off
mdmonitor 0:off 1:off 2:on 3:on 4:on 5:on 6:off
messagebus 0:off 1:off 2:off 3:on 4:on 5:on 6:off
microcode_ctl 0:off 1:off 2:on 3:on 4:on 5:on 6:off
mysqld 0:off 1:off 2:on 3:on 4:on 5:on 6:off
named 0:off 1:off 2:on 3:on 4:on 5:on 6:off
network 0:off 1:off 2:on 3:on 4:on 5:on 6:off
readahead_early 0:off 1:off 2:on 3:on 4:on 5:on 6:off
restorecond 0:off 1:off 2:on 3:on 4:on 5:on 6:off
sendmail 0:off 1:off 2:on 3:on 4:on 5:on 6:off
sshd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
syslog 0:off 1:off 2:on 3:on 4:on 5:on 6:off
vsftpd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
xinetd 0:off 1:off 2:on 3:on 4:on 5:on 6:off
And it's only taking about 100MB memory:
$ free
total used free shared buffers cached
Mem: 553180 491648 61532 0 58404 332188
-/+ buffers/cache: 101056 452124
Swap: 393208 32 393176
And, I could probably turn off several of those, as they aren't doing anything useful.
Basically, what you can do, is search to find out what each of those services do that are running on your VPS. If you don't need them, then turn them off.
I'm guessing, based on what you've said, that you may not need these: clamd-wrapper, named, netfs, postfix, proftpd.
And, as far as I know, these aren't useful on the VPS: lm_sensors, lvm2-monitor, rawdevices
I've removed those from the startup list with the exception of proftpd which I believe I use for transferring files to/from the VPS. When the system is running and stable I guess I could turn it off and only switch it on when I have files to transfer…
Strangely enough memory usage has now gone up to 125MB!
Will reboot and see how it comes back up…
The system is running on a much smaller footprint now, around 120MB seems the norm.
I'll get some users on it tonight for some load testing. Anything I should monitor during the load testing? Linode monitors CPU/Network/IO for me, I guess I shoudl run a few top's through the testing window to see where the RAM is being used….. anything else to have a play with?
I'm thinking I should set Apache to be more in tune with the requirements, currently I have set
>
MinSpareServers 1
StartServers 1
ServerLimit 50
MaxClients 50
MaxRequestsPerChild 2000
StartServers 2 MaxClients 150
MinSpareThreads 25
MaxSpareThreads 75
ThreadsPerChild 25
MaxRequestsPerChild 0
and I just turned off most of the modules as follows:
> #LoadModule authbasicmodule modules/modauthbasic.so
LoadModule authdigestmodule modules/modauthdigest.so
LoadModule authnfilemodule modules/modauthnfile.so
LoadModule authnaliasmodule modules/modauthnalias.so
LoadModule authnanonmodule modules/modauthnanon.so
LoadModule authndbmmodule modules/modauthndbm.so
LoadModule authndefaultmodule modules/modauthndefault.so
LoadModule authzhostmodule modules/modauthzhost.so
LoadModule authzusermodule modules/modauthzuser.so
LoadModule authzownermodule modules/modauthzowner.so
LoadModule authzgroupfilemodule modules/modauthzgroupfile.so
LoadModule authzdbmmodule modules/modauthzdbm.so
LoadModule authzdefaultmodule modules/modauthzdefault.so
LoadModule ldapmodule modules/modldap.so
LoadModule authnzldapmodule modules/modauthnzldap.so
LoadModule includemodule modules/modinclude.so
LoadModule logconfigmodule modules/modlogconfig.so
LoadModule logiomodule modules/modlogio.so
LoadModule envmodule modules/modenv.so
LoadModule extfiltermodule modules/modextfilter.so
LoadModule mimemagicmodule modules/modmimemagic.so
LoadModule expiresmodule modules/modexpires.so
LoadModule deflatemodule modules/moddeflate.so
LoadModule headersmodule modules/modheaders.so
LoadModule usertrackmodule modules/modusertrack.so
LoadModule setenvifmodule modules/modsetenvif.so
LoadModule mimemodule modules/modmime.so
LoadModule davmodule modules/moddav.so
LoadModule statusmodule modules/modstatus.so
LoadModule autoindexmodule modules/modautoindex.so
LoadModule infomodule modules/modinfo.so
LoadModule davfsmodule modules/moddavfs.so
LoadModule vhostaliasmodule modules/modvhostalias.so
LoadModule negotiationmodule modules/modnegotiation.so
LoadModule dirmodule modules/moddir.so
LoadModule actionsmodule modules/modactions.so
LoadModule spelingmodule modules/modspeling.so
LoadModule userdirmodule modules/moduserdir.so
LoadModule aliasmodule modules/modalias.so
LoadModule rewritemodule modules/modrewrite.so
LoadModule proxymodule modules/modproxy.so
LoadModule proxybalancermodule modules/modproxybalancer.so
LoadModule proxyftpmodule modules/modproxyftp.so
LoadModule proxyhttpmodule modules/modproxyhttp.so
LoadModule proxyconnectmodule modules/modproxyconnect.so
LoadModule cachemodule modules/modcache.so
LoadModule suexecmodule modules/modsuexec.so
LoadModule diskcachemodule modules/moddiskcache.so
LoadModule filecachemodule modules/modfilecache.so
LoadModule memcachemodule modules/modmemcache.so
LoadModule cgimodule modules/modcgi.so
LoadModule versionmodule modules/modversion.so
I have a Linode 540 with CentOS 5, Webmin+Virtual, Apache, MySQL, Postfix, Dovecot, etc. It hosts around 30 domains and maybe 60 email users. Memory usage is 100-125 MB.
I'd suggest you…
Disable the services you don't need. If you're not sure what they do, read up on them or ask. e.g., Mailman definitely can go, and Bind also if you're going to use Linode's DNS manager.
Look into MySQL memory optimization. There is likely a big saving you can realize there.
By all means restrict Apache, but don't strangle the poor thing. Your sites will be happier with more than one Apache process running. Try setting those *Servers settings in the 3-6 range and set an upper limit (MaxClients) to maybe 20. Then monitor and see how things go.
<ifmodule prefork.c="">StartServers 8
MinSpareServers 2
MaxSpareServers 10
ServerLimit 256
MaxClients 25
MaxRequestsPerChild 400</ifmodule>
Memory usage:
total used free shared buffers cached
Mem: 360 309 50 0 28 88
-/+ buffers/cache: 193 167
Swap: 255 0 255
It's been up for 43 days and hasn't hit swap yet.
From your list of enabled services, I have haldaemon, ip6tables, kudzu, mcstrans, and messagebus turned off with no apparent ill effect. Note that I'm not using IPv6, SELinux, or Webmin, so your mileage may vary.
Thanks all for your help so far, it's definately running on a much smaller footprint now so we'll see how it handles some load…
@Moses:
I guess I shoudl run a few top's through the testing window to see where the RAM is being used..
Yes. And hit "M" (capital) when top is running to sort by RAM usage.
With a massive shout out to The_Guv for his excellent guides
Now I can use that RAM saved by nginx for caching PHP and MYSQL… as soon as I work out how!
I've got the blog and forums firing now, and will probably migrate the live DNS tonight or tomorrow. Here's the top stats sorted by MEM of the system sitting idle:
> top - 18:06:38 up 7 min, 1 user, load average: 0.04, 0.03, 0.00Tasks: 83 total, 1 running, 82 sleeping, 0 stopped, 0 zombie
Cpu(s): 0.0%us, 0.0%sy, 0.0%ni,100.0%id, 0.0%wa, 0.0%hi, 0.0%si, 0.0%st
Mem: 368864k total, 185160k used, 183704k free, 4408k buffers
Swap: 393208k total, 0k used, 393208k free, 97204k cached
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2668 www-data 15 0 61792 31m 13m S 0 8.8 0:00.72 php-cgi
2669 www-data 16 0 55440 22m 11m S 0 6.3 0:01.07 php-cgi
2287 mysql 15 0 124m 17m 5004 S 0 4.8 0:00.11 mysqld
2667 www-data 15 0 48080 14m 9696 S 0 4.0 0:00.22 php-cgi
2670 www-data 18 0 59008 12m 6516 S 0 3.5 0:00.04 php-cgi
2617 www-data 21 0 46560 9168 6120 S 0 2.5 0:00.06 php-cgi
2671 www-data 18 0 46824 4708 1300 S 0 1.3 0:00.00 php-cgi
2672 moses 17 0 5572 3068 1404 S 0 0.8 0:00.12 bash
2609 www-data 15 0 4916 1636 752 S 0 0.4 0:00.00 nginx
2107 root 16 0 2476 1168 904 S 0 0.3 0:00.00 login
2697 moses 15 0 2220 1076 832 R 0 0.3 0:00.02 top
2610 www-data 15 0 4596 1064 436 S 0 0.3 0:00.00 nginx
2611 www-data 15 0 4596 1064 436 S 0 0.3 0:00.00 nginx
2612 www-data 15 0 4596 1064 436 S 0 0.3 0:00.00 nginx
2166 klog 17 0 2128 1024 392 S 0 0.3 0:00.00 klogd
2187 root 18 0 5220 968 616 S 0 0.3 0:00.00 sshd
1 root 15 0 1956 964 528 S 0 0.3 0:00.00 init
Do the above figures look reasonable? Are there any decent load testing apps that I could use to stress the site and see how she rolls?
Thanks for all the advice to date, it's been educational!
I did my big server move tonight and it all seems to have gone smoothly so far, and damn it FLIES! Well, it could well slow down a lot once the users get on there, but for now I'm loving it.
I've noticed a bunch of permissions related errors, and have been slowly rectifying these with chmod's. Is there a way to export all the chmod's from my old (dreamhost) server to the VPS? Well that's assuming they were correct in the first place, but it's a starting point at least.
Also, I thought I'd update Wordpress however the automated login seems to not be working. I've set it to use IP.ADD.RE.SS:PORT as well as my SFTP details (that work in FileZilla from home) and get:
> Error: There was an error connecting to the server, Please verify the settings are correct.
Finally, I've got huge amounts of RAM free, should I be looking to increase mysql cache or something to use some of this up?
> $ free -m
total used free shared buffers cached
Mem: 360 256 103 0 30 109
-/+ buffers/cache: 116 243
Swap: 383 0 383
$ top
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
2429 www-data 18 0 63080 39m 20m S 0 11.1 0:12.34 php-cgi
2430 www-data 16 0 55416 28m 16m S 0 7.8 0:14.58 php-cgi
2432 www-data 16 0 52356 24m 15m S 0 6.8 0:12.81 php-cgi
2433 www-data 16 0 51552 24m 15m S 0 6.7 0:13.61 php-cgi
2431 www-data 16 0 51548 22m 14m S 0 6.3 0:10.99 php-cgi
2271 mysql 15 0 158m 20m 5200 S 0 5.8 0:03.27 mysqld
2385 www-data 22 0 46560 9188 6136 S 0 2.5 0:00.03 php-cgi
2562 root 15 0 6816 4952 1544 S 0 1.3 0:00.01 munin-node
2685 moses 15 0 4440 3024 1268 S 0 0.8 0:00.11 bash
2563 root 16 0 7808 2376 1940 S 0 0.6 0:00.03 sshd
4092 root 16 0 7804 2224 1800 S 0 0.6 0:00.04 sshd
11881 postfix 16 0 5440 1936 1584 S 0 0.5 0:00.00 smtp
Cheers,
Moses.
@Moses:
Finally, I've got huge amounts of RAM free, should I be looking to increase mysql cache or something to use some of this up?
SMF has memory caching capabilities, with memcached, APC and I believe even XCache, the last two also being opcode cachers. I'm assuming you're using one of them.
> 502 Bad Gateway
nginx/0.7.62
Should I have chown'ed anything to www-data
Here's my nginx.conf
> user www-data www-data;
worker_processes 4;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
sendfile on;
tcp_nopush on;
tcp_nodelay off;
keepalive_timeout 5;
gzip on;
gzipcomplevel 2;
gzip_proxied any;
gzip_types text/plain text/css application/x-javascript text/xml applic
ation/xml application/xml+rss text/javascript;
include /usr/local/nginx/sites-enabled/*;
}
Thanks for any tips,
Moses.
> 2009/12/16 11:47:09 [error] 12081#0: *1145 recv() failed (104: Connection reset by peer) while readi
ng response header from upstream, client: 221.133.197.254, server:
www.domain.com , request: "POST /wp-comments-post.php HTTP/1.1", upstream: "fastcgi://127.0.0.1:9000", host: "
www.greenandg oldrugby.com", referrer: "
" http://www.domain.com/ggr-moves-to-our- … al-server/">http://www.domain.com/ggr-moves-to-our-own-virtual-server/ 2009/12/16 11:47:10 [error] 12081#0: *1109 recv() failed (104: Connection reset by peer) while readi
ng response header from upstream, client: 203.33.167.125, server:
www.domain.com , request: "GET /wp-content/plugins/top-10/top-10-counter.js.php?toptenid=7401 HTTP/1.1", upstream: "fastcg
i://127.0.0.1:9000", host: "
www.domain.com ", referrer: "http://www.domain.com/ "
2009/12/16 11:47:11 [error] 12081#0: *1110 recv() failed (104: Connection reset by peer) while readi
ng response header from upstream, client: 203.33.167.125, server:
www.domain.com , request: "GET /wp-content/plugins/top-10/top-10-counter.js.php?toptenid=7294 HTTP/1.1", upstream: "fastcg
i://127.0.0.1:9000", host: "
www.domain.com ", referrer: "http://www.domain.com/ "
2009/12/16 11:50:15 [error] 12081#0: *1290 recv() failed (104: Connection reset by peer) while readi
ng response header from upstream, client: 150.101.187.176, server:
www.domain.com , request: "GET /feed/atom/ HTTP/1.1", upstream: "fastcgi://127.0.0.1:9000", host: "
www.domain.co m"
2009/12/16 11:55:12 [error] 12083#0: *1457 readv() failed (104: Connection reset by peer) while read
ing upstream, client: 71.235.154.48, server:
www.domain.com , request: "GET /feed/ HTTP/1.1", upstream: "fastcgi://127.0.0.1:9000", host: "
www.domain.com "
strange….
Could it be related to a memory problem? Here are my charts from munin where the reboot just after midday on wednesday can be seen..
 ~~http://www.mosey.id.au/memory.png
~~http://www.mosey.id.au/memory.png
my nginx error log is filling up again as well…
> //127.0.0.1:9000", host: "www..com", referrer: "http://www..com/"
2009/12/16 16:27:27 [error] 2369#0: *11692 recv() failed (104: Connection reset by peer) while reading response header from upstream, client: 203.14.52.45, server: www.***.com, request:
"GET /wp-content/plugins/top-10/top-10-counter.js.php?toptenid=7364 HTTP/1.0", upstream: "fastcgi:
//127.0.0.1:9000", host: "www..com", referrer: "http://www..com/"
2009/12/16 16:27:27 [error] 2369#0: *11690 recv() failed (104: Connection reset by peer) while reading response header from upstream, client: 203.14.52.45, server: www.***.com, request:
"GET /wp-content/plugins/top-10/top-10-counter.js.php?toptenid=7448 HTTP/1.0", upstream: "fastcgi:
//127.0.0.1:9000", host: "www..com", referrer: "http://www..com/"
2009/12/16 16:27:51 [error] 2369#0: *11720 readv() failed (104: Connection reset by peer) while reading upstream, client: 203.14.52.45, server: www.***.com, request: "GET /wallaby-tight-head-prop-of-the-decade/ HTTP/1.0", upstream: "fastcgi://127.0.0.1:9000", host: "www..com", referrer: "http://www..com/"
2009/12/16 16:27:53 [error] 2369#0: 11724 recv() failed (104: Connection reset by peer) while reading response header from upstream, client: 203.14.52.45, server: www.***.com, request: "GET /wp-content/plugins/top-10/top-10-addcount.js.php?toptenid=7367 HTTP/1.0", upstream: "fastcgi://127.0.0.1:9000", host: "www.**.com", referrer: "http://www.***.com/w
allaby-tight-head-prop-of-the-decade/"
2009/12/16 16:27:53 [error] 2369#0: *11724 recv() failed (104: Connection reset by peer) while reading response header from upstream, client: 203.14.52.45, server: www.***.com, request: "GET /index.php?akaction=akttcss HTTP/1.0", upstream: "fastcgi://127.0.0.1:9000", host: "www..com", referrer: "http://www..com/wallaby-tight-head-prop-of-the-decade/"~~
Are you still having problems? What size linode are you using?
In your webmin boot up panel, do you have this:
php_cgi Yes Run php-cgi as app server
I swiftly read through your thread, saw you're using NGINX and followed some of theguv's instructions….
You're site is up right now, cached and loading great from Fort Worth, TX.
Cheers!
Thanks for the response!
I suppose I should have started a new thread when I blew away the CentOS instance and moved to Ubuntu Hardy.. There's too much in this thread now that's no longer relevant, and I don't expect people to read so much dribble!
Yep the site's up and flying, well at least it does for a few hours then certain things start giving nginx 502 errors. Things such as going to the wordpress admin page /wp-admin and leaving a comment on the blog.
The first time it happened I found a restart fixed it. The second time I was able to get it going again with
> /etc/init.d/php-fastcgi stop
/etc/init.d/php-fastcgi start
I have just re-read the Guv's guide and checked my system to find that I'm using libfcgi0ldbl for fcgi… and I suspect it's the cause of my systems' instability.
> dpkg -l | grep cgi
ii libfcgi0ldbl 2.4.0-7 Shared library of FastCGI
btw I'm on a Linode 360.
Also, it will appear in your bootup list in webmin as php_cgi. Make sure it is setup to start on boot. And make sure HTTP is set to not start at bootup.
Glad to see your wordpress site is humming along. I use wordpress mu on a quadcore, 6GB ram, SAS hd. I'm considering switching all to a linode. Testing the response to your site helped my confidence. I think I'd feel safer running a few linodes than my single point of failure dedicated server @ThePlanet.
I also found out that one of the lead wordpress developers and head wordpress mu guru has his site on a linode: http://ocaoimh.ie/
Cheers,
eyecool
I'm thinking of installing spawn-fcgi rather than the libfcgi0ldbl one from The Guv's guides.
I've gone without webmin after the move to Ubuntu, riding bareback in the console has been an experience! Is this what you're looking for:
> ps -ef | grep cgi
www-data 18031 1 0 21:07 ? 00:00:00 /usr/bin/php-cgi -q -b localhost:9000
www-data 18034 18031 2 21:07 ? 00:03:00 /usr/bin/php-cgi -q -b localhost:9000
www-data 18035 18031 3 21:07 ? 00:03:16 /usr/bin/php-cgi -q -b localhost:9000
www-data 18036 18031 2 21:07 ? 00:03:05 /usr/bin/php-cgi -q -b localhost:9000
www-data 18037 18031 2 21:07 ? 00:03:02 /usr/bin/php-cgi -q -b localhost:9000
www-data 18038 18031 3 21:07 ? 00:03:24 /usr/bin/php-cgi -q -b localhost:9000
root 28068 17473 0 22:53 pts/0 00:00:00 grep cgi
I haven't installed http, in fact the only part of apache I have got is the apache2-utils for the ab benchmarking.
> $ dpkg -l | grep http
$
Sounds like a good idea to move to a linode, alas I know far too little to give you any real advice at this point but I like the idea of a few nodes to load balance a busier site.
If I use master + children processes (children = 1+), the children (worker) processes will not disappear in case of a crash. Also note the setting to restart PHP after X requests, afaik the default is 500 which might have caused your problem (restarts, but nothing is there to respawn new, if you used single PHP process).
Regarding those 500 requests, there are mixed opinions about it, but the common denominator is that PHP is/was bad at memory management and required process restart after certain number of requests, for example see this:
I installed spawn-fcgi and will monitor it to see how it runs.. strangely it doesn't like to startup after a reboot, is there any way on ubuntu where I can check if it's set to run?
I've created an init script at /etc/init.d/init-fastcgi
Running this script manually does start php-cgi
> ps -ef | grep php
www-data 2719 1 0 00:54 ? 00:00:00 /usr/bin/php-cgi -q -b localhost:9000
www-data 2722 2719 1 00:54 ? 00:00:08 /usr/bin/php-cgi -q -b localhost:9000
www-data 2723 2719 0 00:54 ? 00:00:04 /usr/bin/php-cgi -q -b localhost:9000
www-data 2724 2719 0 00:54 ? 00:00:03 /usr/bin/php-cgi -q -b localhost:9000
www-data 2725 2719 0 00:54 ? 00:00:03 /usr/bin/php-cgi -q -b localhost:9000
www-data 2726 2719 0 00:54 ? 00:00:02 /usr/bin/php-cgi -q -b localhost:9000
root 4120 2694 0 01:08 pts/0 00:00:00 grep php
I ran
update-rc.d init-fastcgi defaults
There is a symbolic link in the startup folder
> ls /etc/rc0.d -lthr | grep cgi
lrwxrwxrwx 1 root root 22 2009-12-17 00:39 K20init-fastcgi -> ../init.d/init-fastcgi
but I need to manually start it after a reboot. Any log I can check for this?
Cheers,
Moses.
I've switched over to spawn-fcgi (wish I'd read atambo's link first) and it's been a lot more stable… though I now get this message popping up in my console several times a minute!
> sh: host: not found
It doesn't seem to affect anything, but damn if I know where it's coming from!
apt-get install host
If I recall, something in your site is trying to do reverse lookups on domains. Install 'host' and the error goes away. Or disable anything doing a reverse lookup.
@saiboogu:
Had something like that error on my install.
apt-get install hostIf I recall, something in your site is trying to do reverse lookups on domains. Install 'host' and the error goes away. Or disable anything doing a reverse lookup.
Thanks saiboogu,
That fixed the host not found errors, and replaced them with "invalid query name 1" errors!
I googled this one and it led me to a conflict between that version of host and smf (simple machines forum). The solution was to install bind9-host, and the error has gone now so thanks for your help.
@Moses:
I googled this one and it led me to a conflict between that version of host and smf (simple machines forum). The solution was to install bind9-host, and the error has gone now so thanks for your help.
That explains why it was familiar, I'm also running SMF.