

Depending on who you ask, the AI boom means that accessing powerful GPUs in the cloud is a breeze – or, it’s nearly impossible. The problem is finding the right GPU on the right provider without overpaying for hardware resources you don’t realistically need, and that will be available only when you need it, without needing to commit to prepaid reservations or steep contracts.
It’s a tall order, and we were glad to accept the challenge. After rigorous testing and optimization, Akamai’s new GPUs are now available for all customers. Powered by the NVIDIA RTX 4000 Ada Generation cards, these GPUs are optimized for media use cases but are right-sized for a range of workloads and applications. The RTX 4000 Ada Generation plans start at $0.52 per hour for 1 GPU, 4 CPUs, and 16GB of RAM in six core compute regions:
- Chicago, IL
- Seattle, WA
- Frankfurt, DE Expansion
- Paris, FR
- Osaka, JP
- Singapore, SG Expansion
- Mumbai, IN Expansion (Coming Soon!)
Use Case Highlights
Through our beta program, our customers and independent software vendor (ISV) partners were able to put our new GPUs to the test, including for key use cases we knew would benefit from the GPU plan specifications we designed: media transcoding and lightweight AI.
Capella Systems’ cloud-hosted encoder, Cambria Stream, handles live encoding, ad insertion, encryption, and packaging for the most demanding live events. It takes the right technology and configuration behind-the-scenes for end users to watch live streamed events from all different devices and across network infrastructures.
“Using Akamai’s new NVIDIA RTX 4000 Ada Generation Dual GPU, a single Cambria Stream can process up to 25 channels of multi-layer encoding at once, reducing the total computing cost significantly compared to CPU-based encoding.”
Read the full press release.
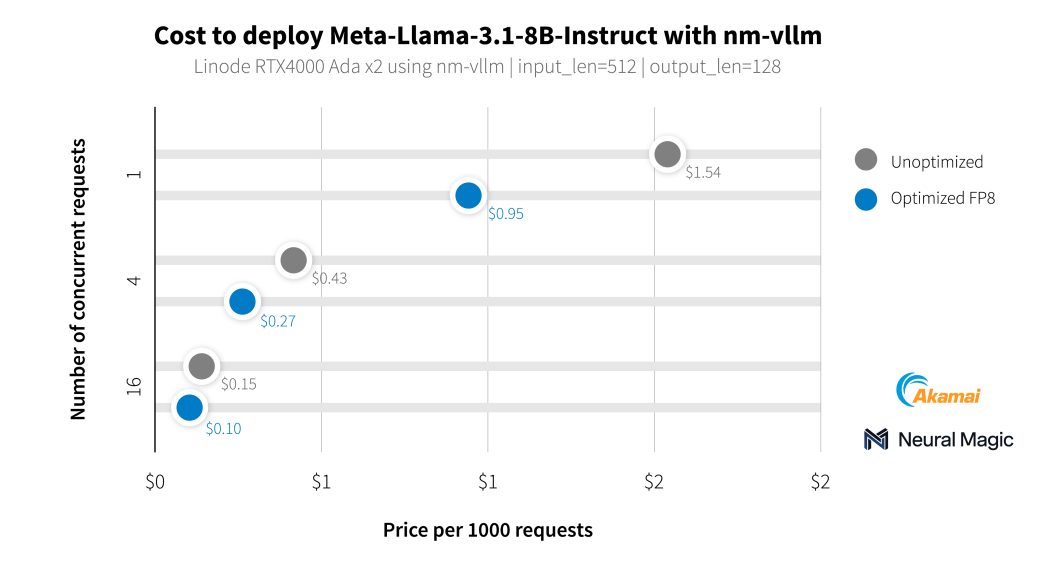
In addition to our media customers, we worked with Neural Magic to benchmark the AI capabilities of our new GPUs using nm-vllm, their enterprise-ready LLM serving engine. They made use of their open source compression toolkit for LLMs, LLM Compressor, to produce much more efficient deployments with 99.9% accuracy preservation. While testing the latest Llama 3.1 models, Neural Magic utilized their software optimizations to achieve an average cost of $0.27 per 1,000 summarization requests using RTX 4000 GPUs, a 60% reduction in cost compared to the reference deployment.
Get Started
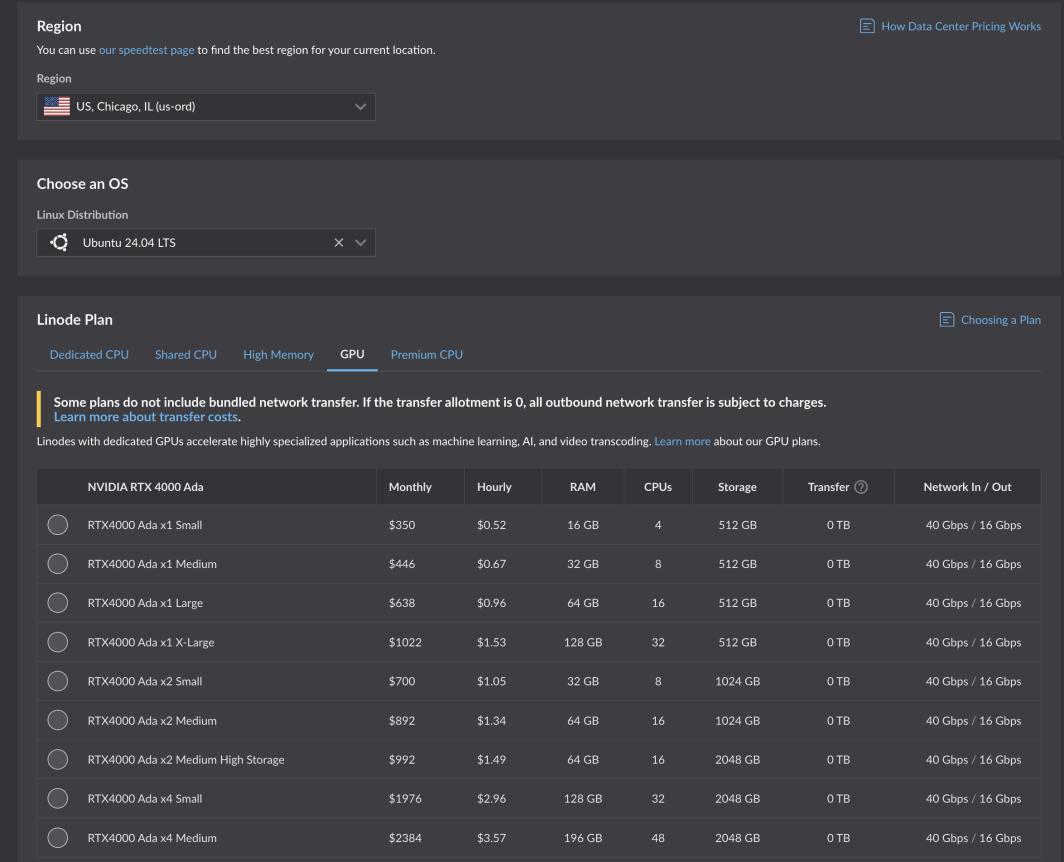
If you already have an account, you can get started right away. Simply select a supported region and navigate to the GPU tab on the compute instance plan table.
Get started with our documentation.
Developers building and managing business applications are encouraged to reach out to our cloud consultant teams.
Note: Use of Akamai GPU instances requires a positive billing history on your account, not including promo codes. If you are unable to deploy and require GPU access, open a support ticket.





Comments